Extracting data from websites us
This page is a copy from
this link
Extracting data from websites using Scrapy
1 Introduction
<span class="graf-dropCap">A</span> big percent of the world’s data is unstructured, estimated around 70%-80%. Websites are a rich source for unstructured text that can be mined and turned into useful insights. The process of extracting information from websites is usually referred to as Web scraping.
There are several good open source Web scraping frameworks, including Scrapy, Nutch and Heritrix. A good review on Open Source Crawlers can be found here, also this Quora question contains some good related answers.
For medium sized scraping projects, Scrapy stands out from the rest since it is:
- Easy to setup and use
- Great documentation
- Mature and focused solution
- Built-in support for proxies, redirection, authentication, cookies and others
- Built-in support for exporting to CSV, JSON and XML
This article will walk you through installing Scrapy, extracting data from a site and analyzing it.
Note:
- This guide is written for Ubuntu 14.04 and 16.04, but it should work with other Linuxes.
2 Installing Scrapy
2.1 Python
Scrapy framework is developed in Python, which is preinstalled in Ubuntu and almost all Linux distributions. As of Scrapy 1.05, it requires Python 2.x, to make sure Python 2.x is installed, issue the following command:
<pre name="6d72" id="6d72" class="graf--pre graf-after--p">python --version</pre>
The result should be something like the following:
<pre name="53f4" id="53f4" class="graf--pre graf-after--p">Python 2.7.6</pre>
Note:
- Ubuntu 16.04 minimal install does not come with Python 2 preinstalled anymore. To install it, issue the following command:
<pre name="f1cb" id="f1cb" class="graf--pre graf-after--li">sudo apt-get install python-minimal</pre>
2.2 Pip
There are several ways to install Scrapy on Ubuntu. In order to get the latest Scrapy version, this guide we will use the pip (Python Package Management System) method. To install pip on Ubuntu along with all the needed dependency, issue the following command:
<pre name="8fe2" id="8fe2" class="graf--pre graf-after--p">sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev</pre>
2.3 Scrapy
After installing pip, install Scrapy with the following command:
<pre name="27d7" id="27d7" class="graf--pre graf-after--p">sudo -H pip install Scrapy</pre>
- Make sure you use the -H flag, in order for the environment variables to be set correctly
To make sure that Scrapy is installed correctly, issue the following command:
<pre name="45d5" id="45d5" class="graf--pre graf-after--p">scrapy version</pre>
The result should be something like the following:
<pre name="e0e9" id="e0e9" class="graf--pre graf-after--p">Scrapy 1.0.5</pre>
3 Scrapy in Action
3.1 Using Scrapy
There are various methods to use Scrapy, it all depends on your use case and needs, for example:
- Basic usage: create a Python file containing a spider. A spider in Scrapy is a class that contains the extraction logic for a website. Then run the spider from the command line.
- Medium usage: create a Scrapy project that contains multiple spiders, configuration and pipelines.
- Scheduled scraping: use Scrapyd to run scrapy as a service, deploy projects and schedule the spiders.
- Testing and debugging: use Scrapy interactive shell console for trying out things
In this guide, I will focus on running spiders from the command line, since all other methods are similar and somehow straightforward.
3.2 Understanding Selectors
Before scraping our first website, it is important to understand the concept of selectors in scrapy. Basicly, selectors are the path (or formula) of the items we need to extract data from inside a HTML page.
From Scrapy documentation:
Scrapy comes with its own mechanism for extracting data. They’re called selectors because they “select” certain parts of the HTML document specified either by XPath or CSS expressions.
XPath is a language for selecting nodes in XML documents, which can also be used with HTML. CSS is a language for applying styles to HTML documents. It defines selectors to associate those styles with specific HTML elements.
You can either use the CSS or XPath selectors to point to the items you want to extract. Personally, I prefer the CSS selectors since they are easier to read. To find the CSS/XPath of items I greatly recommend that you install the Chrome plugin SelectorGadget. On Firefox you can install Firebug and Firefinder.
We will use the SelectorGadget Chrome plugin for this guide, so install from here.
3.3 Scraping walkthrough: getting the selectors
For this guide we will extract deals information from Souq.com, the largest Ecommerce site in Arabia. We will start with the deals page and follow the links to each product and scrape some data from each page.
After opening the deals page, click on SelectorGadget icon to activate the plugin, afterwards click on any product name, as shown in Figure [1].
<figure name="b090" id="b090" class="graf--figure graf-after--p">
<div class="aspectRatioPlaceholder is-locked" style="max-width: 620px; max-height: 349px;">[
<div class="progressiveMedia js-progressiveMedia graf-image" data-image-id="0*axqemHqVZje1dEED." data-width="620" data-height="349">
<canvas class="progressiveMedia-canvas js-progressiveMedia-canvas"></canvas>
<noscript class="js-progressiveMedia-inner">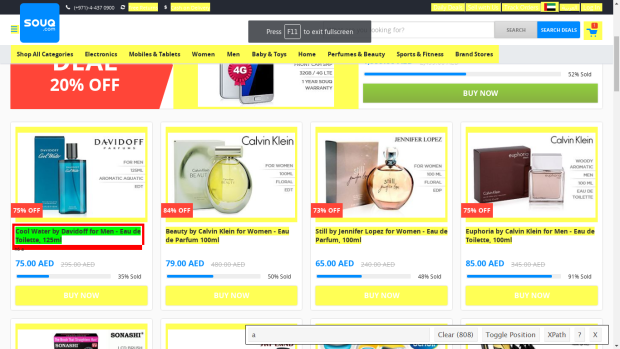
</noscript>
</div>
](https://kaismh.files.wordpress.com/2016/04/souq1.png)</div>
<figcaption class="imageCaption">Figure 1: Using SelectorGadget to select product title</figcaption>
</figure>
Notice, that the SelectorGadget selected all the links in the page and highlighted them yellow, which is something we don’t want. Now, click on one of the unwanted links, the product image will do. You will end up with only the relevant links highlighted as shown in the annotated Figure [2]. Look closely at the SelectorGadget toolbar, and notice:
1. CSS Selector: this text box will contain the CSS selector based on your selection. You can also manually edit it to test out selectors. In Souq’s deals page, it contains
<pre name="841f" id="841f" class="graf--pre graf-after--p">.sp-cms_unit — ttl a</pre>
2. Number of results: this label counts the number of found items based on your selection.
<figure name="d651" id="d651" class="graf--figure graf-after--p">
<div class="aspectRatioPlaceholder is-locked" style="max-width: 620px; max-height: 356px;">[
<div class="progressiveMedia js-progressiveMedia graf-image" data-image-id="0*BmITX_tKzjEL2Rpx." data-width="620" data-height="356">
<canvas class="progressiveMedia-canvas js-progressiveMedia-canvas"></canvas>
<noscript class="js-progressiveMedia-inner">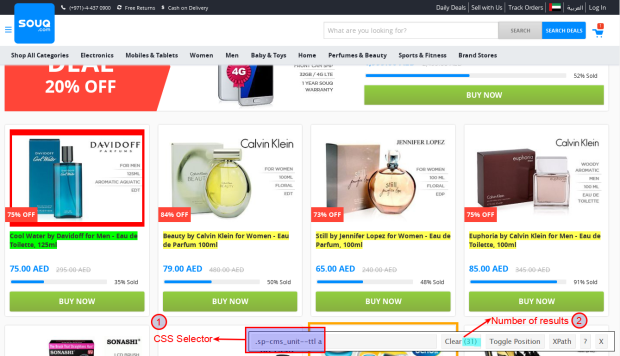
</noscript>
</div>
](https://kaismh.files.wordpress.com/2016/04/souq2.png)</div>
<figcaption class="imageCaption">Figure 2: Annotated page of all the required links selected</figcaption>
</figure>
Click on the SelectorGadget icon again to deactivate it, click on the title for any product so you can be redirected to that product page. Use the SelectorGadget plugin to determine the selectors for Title, Seller and other interesting information. Alternatively, have look at the code in the next section to to view the selectors values.
3.4 Scraping walkthrough: coding the spider
Copy the following code listing into your favourite text editor and save it as souq_spider.py
<pre name="9787" id="9787" class="graf--pre graf-after--p"># -- coding: utf-8 --
import scrapy
class SouqSpider(scrapy.Spider):
name = "Souq" # Name of the Spider, required value
start_urls = ["http://deals.souq.com/ae-en/"] # The starting url, Scrapy will request this URL in parse
# Entry point for the spider
def parse(self, response):
for href in response.css('.sp-cms_unit--ttl a::attr(href)'):
url = href.extract()
yield scrapy.Request(url, callback=self.parse_item)
# Method for parsing a product page
def parse_item(self, response):
original_price = -1
savings=0
discounted = False
seller_rating = response.css('.vip-product-info .stats .inline-block small::text'). extract()[0]
seller_rating = int(filter(unicode.isdigit,seller_rating))
# Not all deals are discounted
if response.css('.vip-product-info .subhead::text').extract():
original_price = response.css('.vip-product-info .subhead::text').extract()[0].replace("AED", "")
discounted = True
savings = response.css('.vip-product-info .message .noWrap::text').extract()[0].replace("AED", "")
yield {
'Title': response.css('.product-title h1::text').extract()[0],
'Category': response.css('.product-title h1+ span a+ a::text').extract()[0],
'OriginalPrice': original_price,
'CurrentPrice': response.css('.vip-product-info .price::text').extract()[0].replace(u"\xa0", ""),
'Discounted': discounted,
'Savings': savings,
'SoldBy': response.css('.vip-product-info .stats a::text').extract()[0],
'SellerRating': seller_rating,
'Url': response.url
}</pre>
The previous code will request the deals page at Souq, loop on each product link and extract the required data inside the parse_item method.
3.5 Scraping walkthrough: running the spider
To run the spider we are going to use the runspider command, issue the following command:
<pre name="d28e" id="d28e" class="graf--pre graf-after--p">scrapy runspider souq_spider.py -o deals.csv</pre>
When the extractions finishes you will have a CSV file (deals.csv) containing Souq deals for the day, Figure [3] contains a sample out. You can also change the format of the output to JSON or XML by changing the output file extension in the runspider command, for example, to get the results in JSON issue:
<pre name="ac19" id="ac19" class="graf--pre graf-after--p">scrapy runspider souq_spider.py -o deals.json</pre>
<figure name="5a9c" id="5a9c" class="graf--figure graf-after--pre">
<div class="aspectRatioPlaceholder is-locked" style="max-width: 620px; max-height: 349px;">[
<div class="progressiveMedia js-progressiveMedia graf-image" data-image-id="0*UAs7yhMbij92ymFe." data-width="620" data-height="349">
<canvas class="progressiveMedia-canvas js-progressiveMedia-canvas"></canvas>
<noscript class="js-progressiveMedia-inner">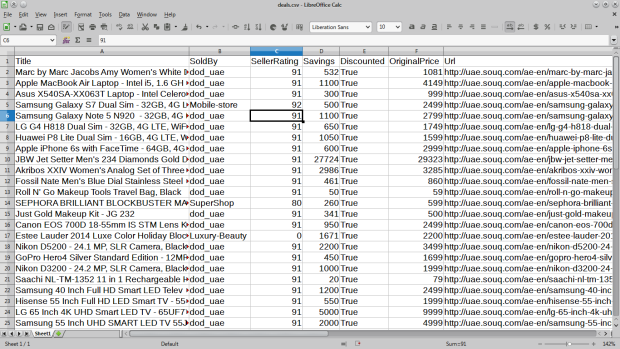
</noscript>
</div>
](https://kaismh.files.wordpress.com/2016/04/souq3.png)</div>
<figcaption class="imageCaption">Figure 3: deals.csv file containing the extracted deals</figcaption>
</figure>
4 Data Analysis
Looking at the data of 1,200 product deals, I came with the following analysis:
4.1 Top Categories
There are 113 different categories in the deals data. I found it a bit surprising that the top two deals categories are Watches (10%) and Handbags (9%) as shown in Figure [4]. But if we combine Mobile Phone (7.6%), Laptops (5.6%) and Tablets (4%) into a general Electronics category, we get (17%), which bring it to the top category and makes much more sense.
<figure name="c920" id="c920" class="graf--figure graf-after--p">
<div class="aspectRatioPlaceholder is-locked" style="max-width: 620px; max-height: 328px;">[
<div class="progressiveMedia js-progressiveMedia graf-image" data-image-id="0*WTW5_Y5waXpGnAYZ." data-width="620" data-height="328">
<canvas class="progressiveMedia-canvas js-progressiveMedia-canvas"></canvas>
<noscript class="js-progressiveMedia-inner">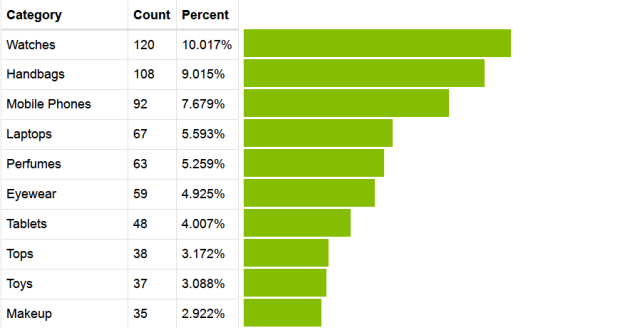
</noscript>
</div>
](https://kaismh.files.wordpress.com/2016/04/souqcat.png)</div>
<figcaption class="imageCaption">Figure 4: Top Product Categories in Deals</figcaption>
</figure>
4.2 Top Sellers
This data is more interesting, from the 86 different sellers, around 78% of the 1,200 deals are provided by one seller (dod_uae). Also, as illustrated in Figure [5], the next seller (JUMBOELECTRONICS) accounts for only 2%. Seller dod_uae deals are in 98 different categories (87% of categories) ranging from Baby Food, Jewelry to Laptops and Fitness Technology. In comparison, JUMBOELECTRONICS deals are in 3 related categories.One can conclude that dod_uae is somehow related to Souq or a very active seller!
<figure name="0271" id="0271" class="graf--figure graf-after--p">
<div class="aspectRatioPlaceholder is-locked" style="max-width: 620px; max-height: 342px;">[
<div class="progressiveMedia js-progressiveMedia graf-image" data-image-id="0*t9SGIhFBBqhJ9jRB." data-width="620" data-height="342">
<canvas class="progressiveMedia-canvas js-progressiveMedia-canvas"></canvas>
<noscript class="js-progressiveMedia-inner">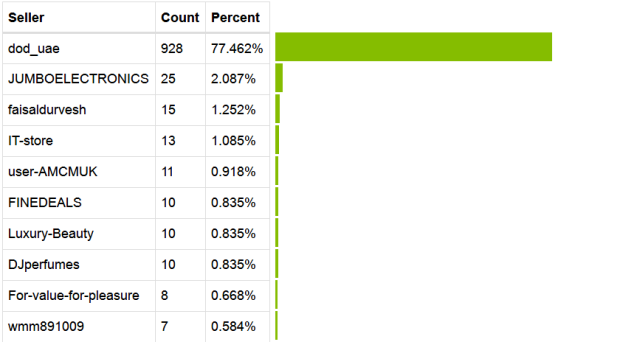
</noscript>
</div>
](https://kaismh.files.wordpress.com/2016/04/souqsellers.png)</div>
<figcaption class="imageCaption">Figure 5: Top sellers in deals</figcaption>
</figure>
4.3 Sellers Ratings
There are 14 sellers with 0% Positive Rating, I am not sure what does that mean in Souq terminology. It might be that these sellers don’t have a rating yet or their overall rating is too low, so it was decided to hide it. The average rating for the remaining non-zero rating is 86.542 with a standard deviation of 8.952. There does not seem to be a correlation between seller rating and discount percentage as shown in Figure [6], it seems other variables such as service and quality factors more in rating than discount percentage.
<figure name="8267" id="8267" class="graf--figure graf-after--p">
<div class="aspectRatioPlaceholder is-locked" style="max-width: 620px; max-height: 358px;">[
<div class="progressiveMedia js-progressiveMedia graf-image" data-image-id="0*eRh57wO3gKWKNSqw." data-width="620" data-height="358">
<canvas class="progressiveMedia-canvas js-progressiveMedia-canvas"></canvas>
<noscript class="js-progressiveMedia-inner">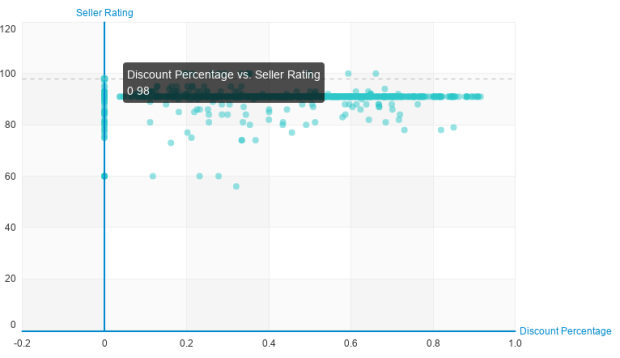
</noscript>
</div>
](https://kaismh.files.wordpress.com/2016/04/souqsellersdiscount.png)</div>
<figcaption class="imageCaption">Figure 6: Discount vs rating</figcaption>
</figure>
4.4 Product Prices and discounts
We can get a lot of useful information looking at the deals prices and discounts, for example:
- The most expensive item before discount is a JBW watch (29323 AED), coincidentally it is also the most discounted item (94%) discount, so you can get it now for 1599 AED.
- The most expensive item after discount is a Nikon Camera, selling for 7699 AED (around 2000$)
- The average discount percentage for all the deals is 42%
If you have the urge to buy something from Souq after scraping and analyzing the deals, but you are on a tight budget, you can always find the cheapest item. Currently, it is a Selfie Stick, selling for only 6 AED ( < 2$)
5 Related Links
If you have found this article useful and managed to scrap interesting data with Scrapy, share your results via the comments section.


