Python学习记录-网站爬点句子
2019-01-08 本文已影响6人
听风轻咛
背景
想用python上网爬点句子,于是花一下午的时间来做这件事,这只是一个简单的例子,不过对于入坑来说nn
conda使用
顺便添加一下conda的使用,之前一直是用python自带的virtualenv工具,安装了anoconda后还是觉得conda比较好用;
-
创建一个环境
$ conda create -n vir_name python=2.7 -
使用环境
$ source activate vir_name -
安装工具
$ conda install tools_name # or $ pip install tools_name
Beautiful Soup安装
linux下安装
apt-get isntall python-bs4
urllib2
自行解决吧!
开始写代码了
首先我们需要用到这么些个库,自行去匹配吧,环境没有,自己去凑;
#!/usr/bin/python
# coding:utf-8
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
import time
import sys
import os
import socket
接下来的这两段解决的是,默认的网络请求超时时间设定,以及解决系统编码问题,因为使用过程中会遇到乱码的问题(本人使用mac系统,参考教程使用的是win系统)
second_out = 200
socket.setdefaulttimeout(second_out)
reload(sys)
sys.setdefaultencoding('utf-8')
我们爬取的网站是一个句子网,静态网站比较好操作,而且网址的形式就是下面的前缀,加1000+的数字,所以我们只需要写一个循环,每隔一定时间请求新的网站地址就可以了;
web = "http://www.siandian.com/yulu/"
为了防止程序异常出现导致请求网站的索引丢失,我们把已经请求过的网址索引保存起来,下次请求从本地“恢复现场”,这样就不会重复请求了;
global index
index = 1351
index_path = os.path.join(os.getcwd(), 'index.txt')
if not os.path.exists(index_path):
with open(index_path, 'w') as f:
s = str(index)
f.write(s)
with open(index_path, 'r') as f:
s = f.read()
print s
index = int(s)
- 下面的说明会写在代码里
 image_1d0lk9rapih31pcjcft1puv1ach9.png-428.4kB
image_1d0lk9rapih31pcjcft1puv1ach9.png-428.4kB
def get_page(index):
url = web + "{}.html".format(index)
request = urllib2.Request(url)
page = urllib2.urlopen(request, timeout=second_out)
return page
while True: # 我们需要一个一直运行的循环
page = get_page(index) # 获取请求的网站内容
time.sleep(1) # 有些网站对频繁请求的IP会做处理,另外网页请求需要时间处理,所以我们每隔一定时间去请求新的内容
try:
if page != None:
contents = page.read()
# print contents
soup = BeautifulSoup(contents, "html.parser", fromEncoding="gb18030")
# 下面这两句是解决编码问题的,因为会涉及到中文输出乱码的问题
soup.originalEncoding
soup.prettify()
# print soup.prettify()
print "当前索引:{}".format(index)
# print soup.title
# print soup.head
# print soup.p
# print soup.a
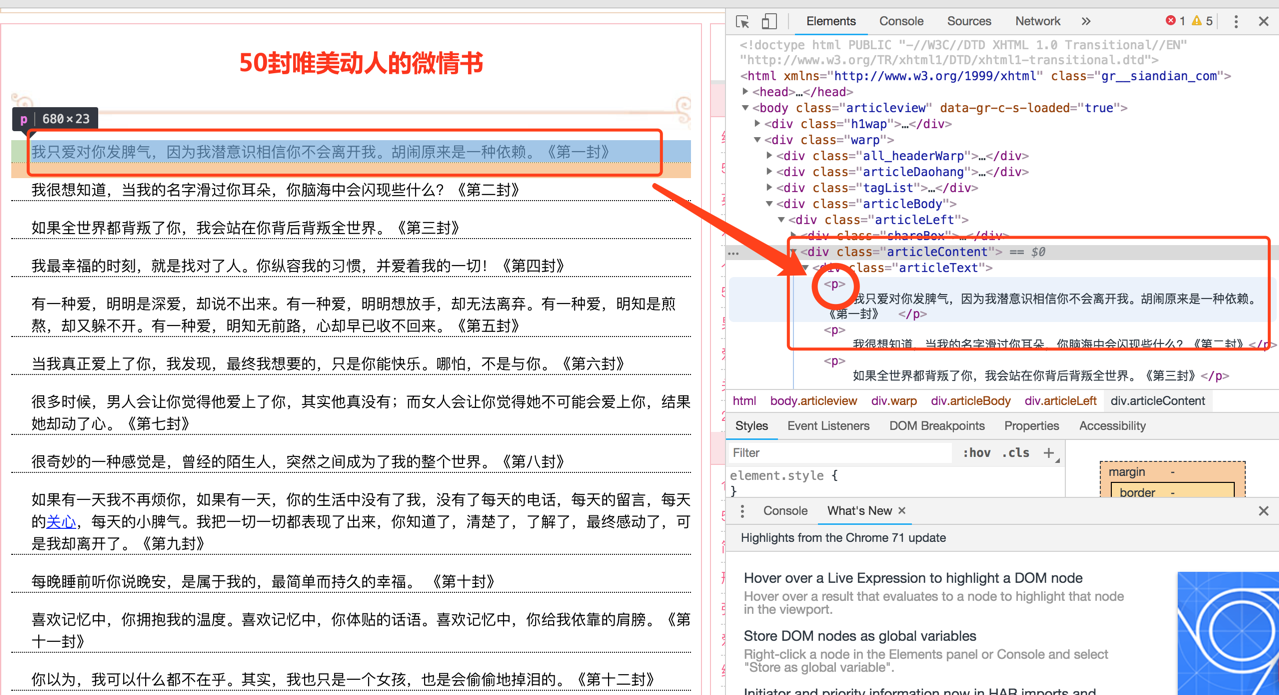
# 这里其实就是我们的重点处理,使用find_all函数可以找到网页中所有<p>名字的标签,返回类型为{bs4.element.Tag},可以去查一下,通过Tag可以直接把文本取出来;
ppps = soup.find_all('p')
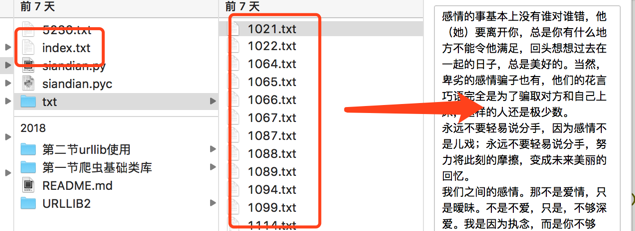
path_dir = os.path.join(os.getcwd(), "txt")
if not os.path.exists(path_dir):
os.mkdir(path_dir)
if len(ppps) > 10:
file_path = "{}/{}.txt".format(path_dir,index)
if os.path.exists(file_path):
index += 1
continue
with open(file_path, 'w') as f:
for cont in soup.find_all('p'):
# print type(cont) # bs4.element.Tag
# 其实真正解决中文乱码问题的应该是这句
text = cont.text.encode('utf-8').decode('utf-8')
f.write(text + '\n')
# 最后我们把找到的文本标签写入文件
with open(index_path, 'w') as f:
f.write("{}".format(index))
else:
print "无信息可保存!!!"
index += 1
continue
else:
print "index: {} ----> None".format(index)
except Exception as e:
print "处理网址异常!!!"
print e
index += 1
continue
finally:
print "finally"
with open(index_path, 'w') as f:
f.write("{}".format(index))
pass
结果
 image_1d0lken6rd6ep9sf5s1oofcl9.png-120.7kB
image_1d0lken6rd6ep9sf5s1oofcl9.png-120.7kB
后记
具体如何进一步通过标签找到自己想要的网站内容,请自行学习,路漫漫其修远兮,吾程序员将上下而求码~~~


