多态,OO与FP
注:本文原名《OO NOT SUCKS, YOU DO》。
缘起
Erlang之父Joe Armstrong曾经写过一篇《Why OO Sucks》,被很多反OO的程序员——尤其是erlang社区的程序员——当作了大旗。
文中指出了OO的四大问题:
- 数据结构和函数不应被绑在一起(
Data structure and functions should not be bound together); - 所有事物都不得不是对象(
Everything has to be an object); - 在面向对象语言里,数据类型定义散播在各处(
In an OOPL data type definitions are spread out all over the place); - 对象有私有状态(
Objects have private state)。
做为一个已经关注OO与FP都将近10年的老鸟(包括erlang),我对此的看法是:这四大问题里,除了第二条尚可商榷之外,其它几条都只是证明了Joe并不明白什么是面向对象,甚至都不明白什么叫高内聚,低耦合。
一个例子
Joe在其著作《Programming Erlang》里,给出一个下面的例子:
area({rectangle, Width, Ht}) -> Width * Ht;
area({circle, R}) -> 3.14159 * R * R;
area({square, X}) -> X * X.
这个例子充分反映了Joe对于程序设计的看法:
- 数据结构和算法是分离的;
- 没有私有状态,所有的数据结构信息都是公开的;
- 对于不同类型数据的类似操作应该被放在一起。
接着,为了证明Erlang的简练,Joe给出了一个C语言的实现:
enum ShapeType { Rectangle, Circle, Square };
struct Shape {
enum ShapeType kind;
union {
struct { int width, height; } rectangleData;
struct { int radius; } circleData;
struct { int side; } squareData
} shapeData;
};
double area(struct Shape* s) {
if( s->kind == Rectangle ) {
int width, ht; width = s->shapeData.rectangleData.width;
ht = s->shapeData.rectangleData.ht;
return width * ht;
} else if ( s->kind == Circle ) {
// ...
} else if ( s->kind == Square ) {
// ...
}
}
Joe认为这是一个与Erlang版本思想一致的C实现。都是使用模式匹配。差别只在于,Erlang的版本要比C版本要简练的多。
然后Joe又给出了一个Java的版本:
abstract class Shape {
abstract double area();
}
class Circle extends Shape {
final double radius;
Circle(double radius) { this.radius = radius; }
double area() { return Math.PI * radius*radius; }
}
class Rectangle extends Shape {
final double ht;
final double width;
Rectangle(double width, double height) {
this.ht = height; this.width = width;
}
double area() { return width * ht; }
}
class Square extends Shape {
final double side;
Square(double side) {
this.side = side;
}
double area() { return side * side; }
}
通过这个例子,Joe除了想说明Java版本比Erlang版本更为繁琐之外,更是为了证明之前批评OO的理由,在面向对象语言里,数据类型定义散播在各处:Java版本的三个类定义被放在三个不同的文件里。
Joe对OO的所有批评都是集中在现象级(包括他对OOPL的批评,错误的把某种OO语言的现象当做OOPL本身),却没有深入到软件设计的挑战,目标和解决方案一级来探讨。这也是他写出那篇充满谬误的文章的最根本原因。
回到这三个实现,事实上是三种不同的设计思路(不仅仅是语言造成的实现差异)。这一切,还需要从本源说起。
选择问题
软件开发中,存在着大量的选择问题。所以,结构化的语言都提供了诸如if-else,switch-case的语法结构;C/C++的预处理则提供了#if,#ifdef,#else等控制结构;而其它语言,比如 Erlang,Haskell等则提供了模式匹配作为选择方式;而 Makefile也提供了if-else结构,让程序的构建者可以选择不同的构建方式。
而选择问题恰恰是程序的复杂度和管理难度所在。很多时候,如果程序过于依赖这些if-else式的控制结构,会让一段代码过于依赖具体的细节,从而造成这些代码需要不断修改,无法做到开放封闭,也有害于代码的重用。
隔离细节(也意味着隔离变化)的方法当然是抽象。程序员们试图通过抽象的手段,将 if-else, switch-case所表达的不同事物,统一为某个一致的概念。然后,当前代码就可以对那些不同事物进行一致的操作,从而将if-else式的选择过程踢出当前代码。
但这并不意味着选择的过程消失了,它们只是被从当前代码中被分离出去(分离不同变化方向)。而这种分离就保证了当前代码不再受选择过程的干扰。
这种处理问题的思路,被称为多态。其定义为: 同一外表之下的多种形态。结合之前的描述,可以总结出多态思想的四个关键元素:
- 客户代码(用户)
- 同一外表(抽象)
- 不同形态(细节)
- 形态选择(映射)
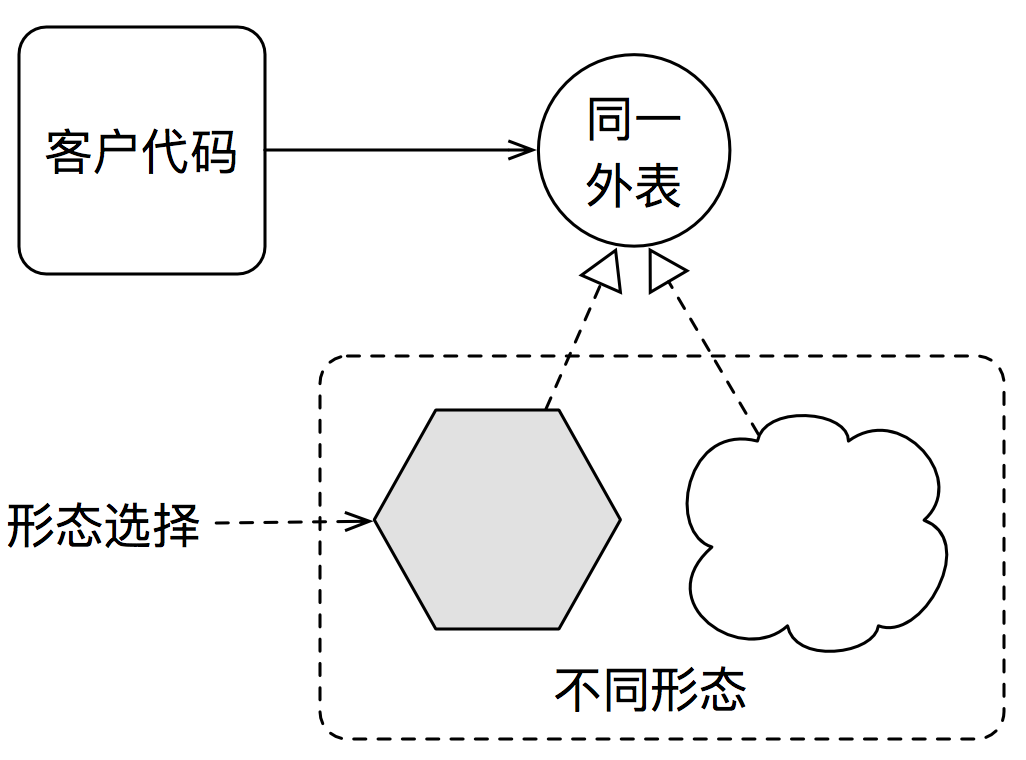 多态四要素
多态四要素
从之前的描述及这幅图也可以清晰的看出:
- 形态的变化,是一个选择问题,因而与其它选择形式,比如
if-else,switch-case,模式匹配等,可以等价转换; - 多态通过同一外表,封装了形态的变化;让客户代码不再受形态变化的影响,从而让系统具备更好的正交性。(多种不同形态间也是正交的)
- 形态选择的过程,其实是一个组合的过程:把客户代码与某种具体形态进行组合。这是组合式设计的源泉之一。
多态与组合式设计
我一直认为,FP语言给程序员提供的最强大武器在于:极其便利的计算组合手段。比如map函数(下面例子给出的是一个haskell版本的类型注解)。
map :: (a -> b) -> [a] -> [b]
这个函数,和任何一个类型为a->b的函数进行组合,就能把一个类型为[a]的列表转化为一个类型为[b]的列表。
C程序员则会使用callback function的方式达到类似的效果。
而基于单个函数的组合,正是一种最为朴素的运行时多态实现。
另外,Haskell的这个实现还包括了另外一种多态:参数化多态。其中a,b都是泛化的类型变量,在具体的调用时,编译器会根据实际传入的参数类型对a,b进行实例化。
而Erlang由于是弱类型,所以并不存在参数化多态的问题。
C++程序员,可以将其看作范型编程中的模版。事实上,模版也是一种参数化多态。
运行时多态解决的是算法变化问题;而参数化多态解决的是类型变化问题。
FP以参数化多态,以及朴素的运行时多态为基础,构成了FP自底向上的组合设计方法:通过将一个个可以适应类型变化的小函数逐级组合,最后得到更为强大的计算功能。
OO ROCKS!!!
Erlang作为一门FP语言,想必Joe一定是认可基于运行时多态的设计思想的。
而运行时多态,作为OO关键特征之一,则提供了更为强大的运行时多态的支持。这里谈到的强大,指的是更为便捷的隔离变化的手段。
-
OO以class为单位,可以定义一个接口集。 - 如果数据是一种实现细节,
OO可以将数据进行信息隐藏。
对于第一点:如果这组接口集正是一个概念应该提供的高内聚完整集合,我们就应该有一种直观便利的手段来表达。
比如,Transaction DSL的公共抽象Action,其定义如下:
struct Action
{
virtual Status exec(TransactionInfo&) = 0;
virtual Status handleEvent(TransactionInfo&, const Event&) = 0;
virtual Status stop(TransactionInfo&) = 0;
virtual void kill(TransactionInfo&) = 0;
virtual ~Action() {}
};
我们知道,所谓单一职责,不仅包含前半部分:DO ONE THING,还包含后半部分DO IT WELL。如果一个概念,必须要包含多个接口才完整,那么我们没有任何理由非要将其分离为一个个孤零零的函数;而是恰恰相反,语言需要提供一种直观便利的手段,让我们可以完整的定义。
而第二点,Joe认为对象有私有状态是OO Sucks的重要原因之一。但是对实现细节进行信息隐藏,是构成了OO对提升系统正交性,促进系统局部化影响的重要手段。如下图所示:
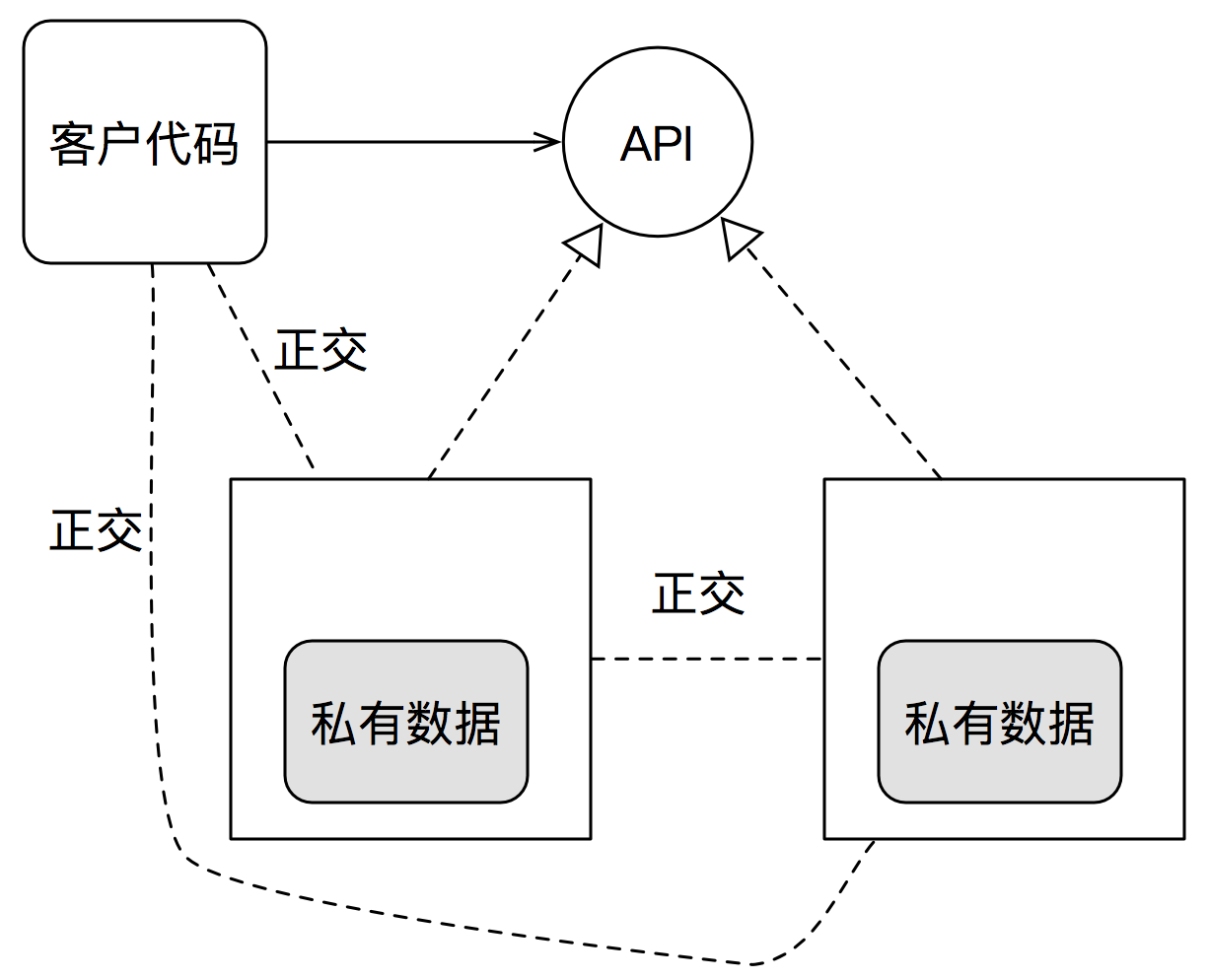 私有数据带来的正交性
私有数据带来的正交性
对于这一点,Joe坚持程序应该与数据分离,可是按照高内聚原则:关联紧密的事物应该被放在一起。如果数据确实是某种算法的特定细节时,这种强制分离只会降低内聚度,提高耦合度。如下图所示:
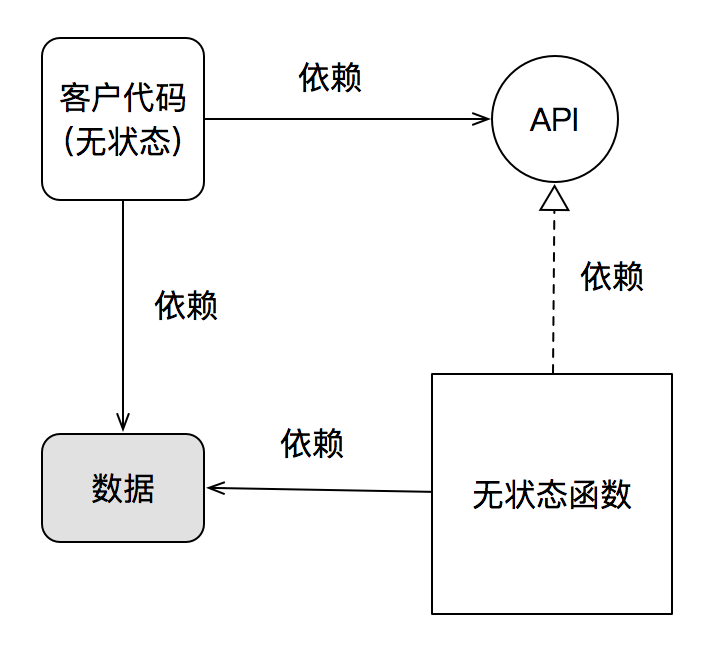 数据与程序分离带来的耦合
数据与程序分离带来的耦合
从这两幅图,可以清晰的看出,当数据是一种不稳定的实现细节时,对象有私有状态与数据与程序分离对于系统耦合度的不同影响。
所以,如果站在Joe对于OO批评的论据出发,不仅不会得到OO Sucks的结论,而是恰恰相反:OO ROCKS!!
AD-HOC多态 vs. SUBTYPE多态
现在,让我们回到Joe在其著作中给出的例子:
area({rectangle, Width, Ht}) -> Width * Ht;
area({circle, R}) -> 3.14159 * R * R;
area({square, X}) -> X * X.
这是个模式匹配的版本。模式匹配也是一种多态:ad-hoc多态。
而之前例子中Java的版本,则是我们熟知的subtype多态。
按照Joe的观点,Erlang的版本,优于Java的版本。但这是否就意味着ad-hoc多态优于sub-type多态呢?
如果这个系统的需求复杂度就是这个样子,不再变化,那么毫无疑问:erlang的版本明显更简洁。
可现实是,对于很多长生命周期的大型项目,需求变化是家常便饭。如果现在增加一个需求:对于所有Shape,增加一个求周长的需求。
这难不倒Erlang程序员,很快,他们就在同一个文件里(这正是Joe所倡导的),写下了如下代码:
perimeter({rectangle, Width, Ht}) -> 2 * (Width + Ht);
perimeter({circle, R}) -> 2 * 3.14159 * R;
perimeter({square, X}) -> 4 * X.
而使用Java,则修改如下:
interface Shape {
// untouched code
double perimeter();
}
class Circle extends Shape {
// untouched code
double perimeter() { return Math.PI * 2 * radius; }
}
class Rectangle extends Shape {
// untouched code
double perimeter() { return (width + ht) * 2; }
}
class Square extends Shape {
// untouched code
double perimeter() { return 4 * side; }
}
我们可以看出,从工作量的角度,两者差不多。区别在于,Erlang版本,只需要在一个地方罗列三种实现;而Java版本则需要到四个文件进行同步修改。好在,如果某个子类在修改时被遗漏,编译器会报错。这会强迫程序员对所有子类都进行修改,不会遗忘。这一局,Erlang继续保持优势。
现在,我们考虑另外一个变化方向:如果现在增加一个新的Shape,比如Triangle。
则Erlang需要做的修改是:
area({rectangle, Width, Ht}) -> Width * Ht;
area({circle, R}) -> 3.14159 * R * R;
area({square, X}) -> X * X;
area({triangle, Data}) -> ... .
perimeter({rectangle, Width, Ht}) -> 2 * (Width + Ht);
perimeter({circle, R}) -> 2 * 3.14159 * R;
perimeter({square, X}) -> 4 * X;
perimeter({triangle, Data}) -> ... .
需要修改area和perimeter两个函数的实现。
而Java则无需改动任何原有代码,只需要增加一个新的类:
class Triangle extends Shape {
// Data
double area() { ... }
double perimeter() { ... }
}
在这个变化方向上,Java版本对于系统的影响程度,要小于Erlang版本。
由此,我们可以知道,从两者受变化影响程度角度看:
-
如果扩展一个操作,
ad-hoc多态优于subtype多态; -
如果扩展一个类型,
subtype多态优于ad-hoc多态。
到目前为止,两者平分秋色。
我们再看看其它的变化:如果某个Shape的数据发生了变化,比如,Triange的数据从Data变化为Data1。则Erlang的代码需要到两个地方修改:
area({rectangle, Width, Ht}) -> Width * Ht;
area({circle, R}) -> 3.14159 * R * R;
area({square, X}) -> X * X;
area({triangle, Data1}) -> ... .
perimeter({rectangle, Width, Ht}) -> 2 * (Width + Ht);
perimeter({circle, R}) -> 2 * 3.14159 * R;
perimeter({square, X}) -> 4 * X;
perimeter({triangle, Data1}) -> ... .
而Java版本则只需要修改一个类:
class Triangle extends Shape {
// Data1
double area() { ... }
double perimeter() { ... }
}
subtype多态再胜一局。
更何况,subtype版本的四个Shape都各自隐藏了自己的数据格式。客户代码不可能对这些数据产生任何依赖。客户只依赖Shape所提供的API。
而Erlang版本的设计,所有数据对于客户均是公开的,客户可以自由的访问它们。而一旦数据格式发生了变化,BANG!!!,所有相关的代码都需要修改。
因而,无论站在缩小依赖范围,还是向着稳定方向依赖原则来看,subtype多态都完胜ad-hoc多态。
ADT 与 Existential Quantification
对于上面这个例子,由于erlang是弱类型,尚可以那么实现。如果使用强类型语言比如haskell,如果要使用ad-hoc多态,则必须首先让它们类型一致化。其中一种手段是代数数据类型(ADT),比如:
data Shape = Circle Float
| Rectangle Float Float
| Square Float
area :: Shape -> Float
area (Circle r) = PI * r * r
area (Rectangle w h) = w * h
area (Square s) = s * s
perimeter :: Shape -> Float
perimeter (Circle r) = PI * r * 2
perimeter (Rectangle w h) = (w + h) * 2
perimeter (Square s) = s * 4
这样的实现,是典型的在一处穷举所有Shape的设计方式。每次增加,修改,删除一个Shape,都需要来修改这里所有的代码。
这很明显不符合开放封闭原则。但如果这样的情况是可穷举且稳定的,那么这样的设计倒也无可厚非。
但假如我们现在设计了一个框架,需要由框架的用户自己定义和扩展具体的Shape,然后注册给我们的框架。这时就需要一个与具体Shape无关的公共抽象。此时,ad-hoc多态不再能解决我们的问题。而subtype多态正是解决这类问题的灵丹妙药。
在这种情况下,Joe所批评的数据类型定义散播在各处,不仅不是一个问题,而恰恰是一个最为正交的合理选择。(当然,如果不需要将类型定义在多处时,只有Java这类的具体OO语言才有这样的约束,而其它支持OO的语言,比如C++,完全可以将多个类型定义在一个文件里。)
而在缺乏subtype多态的强类型的系统下,这类问题很难简单的解决。因而GHC引入了一个扩展:Existential Quantification,用来模拟subtype多态,才终于别扭的部分解决了这类问题。
关于Existential Quantification,由于篇幅问题,不再具体展开。感兴趣的可查阅相关资料。
枚举 vs. subtype多态
Joe的例子,还给出了一个C语言的使用Union和枚举的实现,这是一种典型的模拟ADT的实现方式(Union是ADT Sum Type在C语言中的具体实现)。因而其带来的问题也和ADT一样。
而我们也可以从中清晰的看出:基于枚举的实现,与基于subtype多态的实现方式之间存在着转换关系。
正像模式匹配一样,如果一套枚举对应的switch-case在系统中多处存在,那就意味着,每次增加,删除一个新的枚举常量,都需要多处修改代码;另外,如果某个枚举值对应的数据结构发生了变化,也需要到多处修改代码。
而为了做到局部化影响,则最好将枚举修改为subtype多态的方式来解决问题。从而让系统对于这类变化可以做到开放封闭。
结论
多态是用来应对变化,提高可重用性的重要手段。而不同多态,各自有各自的适用场景及问题。而如何取舍,则还是要用《简单设计原则》来作为标尺。
erlang确实有其非常出色的设计:比如其虚拟机提供的轻量级进程,以及Actor Model对于高并发,分布式,高可靠的支持,可复用库OTP对于快速构建通信类应用的支持等等都很不错。但所有这些都并不能构成OO Sucks的理由。
事实上,完全可以存在一个系统,同样提供相同的机制,唯独编程语言被设定为OO语言,或者更强大的混合范式语言,这并不会削弱Erlang平台+OTP所提供的价值,反而可能会有利于构建更加高效的,易于应对变化的系统。
而被某种具体范式的某个具体语言的某些具体特性在某些具体场景下漂亮应用所吸引,在不明觉历、或者并未明白设计的根本出发点的情况下,狂热的推崇一种范式,并转而攻击另外一种自己并不真正了解的范式,并不是一种可取的态度。(难道这个问题真的是非此即彼,非黑即白么?)
比如,C++对于ad-hoc多态,subtype多态,参数化多态,duck typing多态,预处理时多态,编译时多态,链接时多态,等等各种隔离变化、有助于提高系统正交性的手段全部支持,却总有那么一群完全没搞懂C++的人却在不明就里,人云亦云的批评它。
语言的复杂本身并不是坏事情,因为这个世界的问题就是那么复杂多样,你必须拥有足够多的手段才能高效应对。只要这些复杂度都是在帮助程序员正确高效的解决问题,那么再复杂都是好事情。只有那些没有价值,只带来麻烦的偶发复杂度才是问题。而让一群没有编程素养的人使用一门强大的工具,以至于误用滥用,也是一个问题(问题在于,为何我们要让没有编程素养的程序员单独工作?难道让没有设计素养的程序员使用简单语言就会做出好设计,写出好代码?)。而作为追求高效开发的程序员,使用一门极其简单,却对很多问题缺乏高效手段的乏味工具,这才是最浪费生命,也会缩短职业生命的糟糕选择。
因此,作为解决实际问题的程序员,首先应该深刻去理解设计本身的挑战与目的。然后尽可能丰富自己的工具箱,让自己持有多种武器,以便与在解决具体问题时,可以找到更为合适的手段。而不是手里持有一把锤子,则到处都是钉子。
写在最后
在今天写完这篇文章之时,为了添加相关的链接引用,无意中发现了这个消息,Joe Armstrong承认他之前那篇Why OO Sucks的文章是不成熟的,转而宣称Erlang才是唯一的OO语言:
Erlang has got all these things. It's got isolation, it's got polymorphism and it's got pure messaging. From that point of view, we might say it's the only object oriented language and perhaps I was a bit premature in saying that object oriented languages are about. You can try it and see it for yourself.
——Ralph Johnson, Joe Armstrong on the State of OOP
我说Joe叔,咱能别这么从一个极端走向另外一个极端好么?你让之前跟着你喊OO sucks的人情何以堪啊…… :D


