Github 项目,爬取免费可用代理供爬虫等工具使用
2017-09-04 本文已影响0人
Gavin23
proxy_list
很多网站对爬虫都会有 IP 访问频率的限制。如果你的爬虫只用一个 IP 来爬取,那就只能设置爬取间隔,来避免被网站屏蔽。但是这样爬虫的效率会大大下降,这个时候就需要使用代理 IP 来爬取数据。一个 IP 被屏蔽了,换一个 IP 继续爬取。此项目就是提供给你免费代理的。
需要免费代理的可以试试,如果对您有帮助,希望给个 Star ⭐,谢谢!😁😘🎁🎉
Github 项目地址 gavin66 / proxy_list
特性
-
爬取、验证、存储、Web API 多进程分工合作。
-
验证代理有效性时使用协程来减少网络 IO 的等待时间。
-
持久化(目前使用 Redis)爬取下来的代理。
-
提供 Web API,随时提取与删除代理。
使用
使用 Python3.6 开发的项目,没有对其他版本 Python 测试
克隆源码
git clone git@github.com:gavin66/proxy_list.git
安装依赖
pip install -r requirements.txt
运行脚本
python run.py
Web API
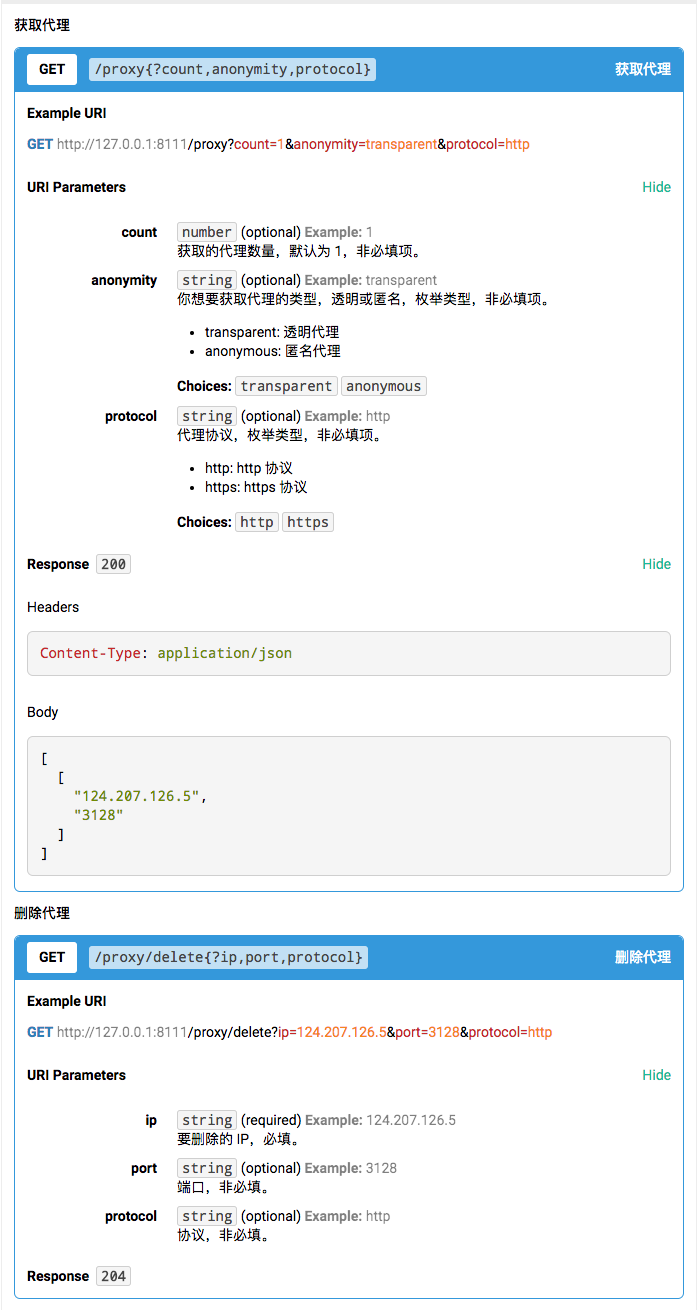 文档截图
文档截图
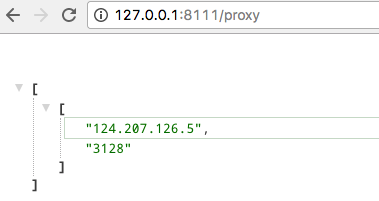 直接获取一个速度最快的代理
直接获取一个速度最快的代理
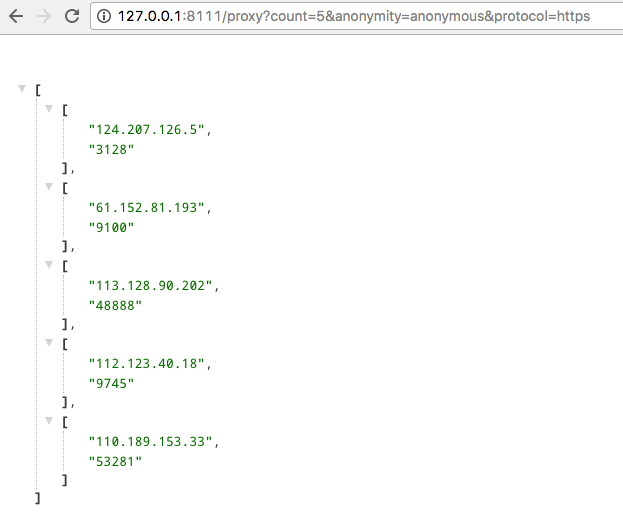 获取 https 的匿名代理,取前5个速度最快的
获取 https 的匿名代理,取前5个速度最快的


