Faster R-CNN 论文阅读
Faster R-CNN
简介
目标检测网络依赖于Region Proposal算法假设目标位置,通过引入Region Proposal(网络RPN),与检测网络共享全图像卷积特征,使得Region Proposals的成本近乎为零。
如下图所示,图a采用的是图像金子塔(Pyramids Of Images)方法;图b采用的是滤波器金字塔(Pyramids Of Filters)方法;图c引入“锚”盒("Anchor" Boxes)这一概念作为多尺度和长宽比的参考,其可看作回归参考金字塔(Pyramids Of Regression References)方法,该方法可避免枚举图像、多尺度滤波器和长宽比。
 解决多尺度和尺寸的不同方案
解决多尺度和尺寸的不同方案
为了将RPN与Fast R-CNN相结合,本文提出了一种新的训练策略:在region proposal任务和目标检测任务之间交替进行微调,同时保持proposals的固定。该方案能够快速收敛,两个任务之间并共享具有卷积特征的统一网络。
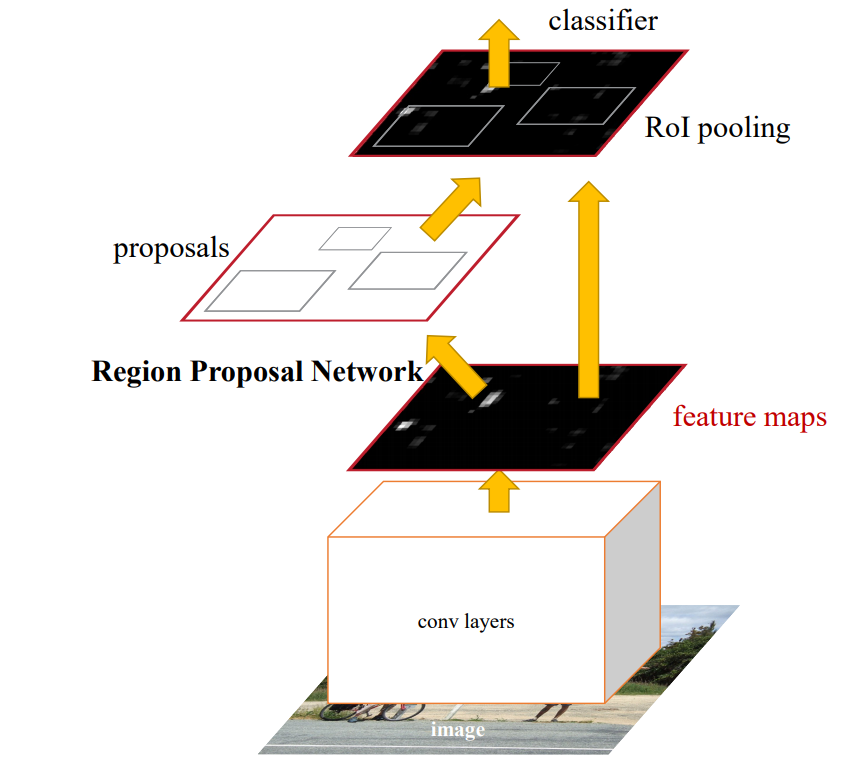
网络结构
Faster R-CNN由两个模块组成:
- RPN,该模块采用“注意力”机制
- Fast R-CNN检测器
RPN
RPN以任意大小的图像作为输入,输出一组矩形的目标proposals,每个proposals都有一个目标得分。在实验中,假设两个网络(RPN和Fast R-CNN)共享一组共同的卷积层,并研究了具有5个共享卷积层的Zeiler和Fergus模型(ZF),以及具有13个共享卷积层的Simonyan和Zisserman模型(VGG-16)。
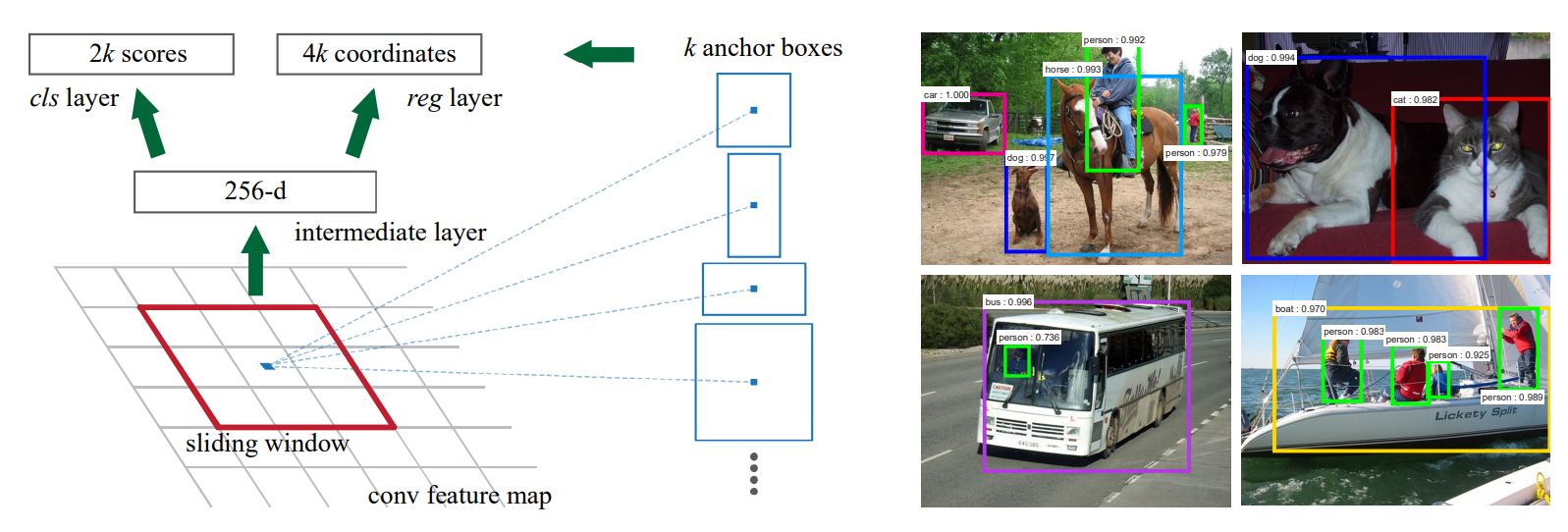
为了生成region proposals,对最后的共享卷积层输出的卷积特征图谱使用一个小网络。该网络以卷积特征图谱的空间窗口作为输入,且每个滑动窗口映射到一个低维特征,所有空间位置共享全连接层。
本文中,
。关于低维特征,ZF为256维,VGG为512维,其后为Relu激活函数。
该低维特征作为两个子全连接层———边界框回归层(box-regression layer, reg)和边界框分类层(box-classification layer, cls)的输入,其卷积核均为大小。
Anchors
对于每个滑动窗口位置,可同时预测多个region proposals,最大region proposals数为。因此,reg层具有
个输出,用于编码k个边界框的坐标;cls层具有
个得分,用于估计每个proposal是目标或不是目标的概率。
Anchors:k个proposals相对于个参考框是参数化形式。
The
proposals are parameterized relative to
anchor位于滑动窗口的中心,并与尺度和长宽比相关。默认情况,使用3个尺度和3个长宽比,在每个滑动位置产生个anchors。对于大小为
的卷积特征图谱,共产生
个anchors。
特性:平移不变性
多尺度anchors作为回归参考
基于anchor的方法建立在anchors金字塔(pyramid of anchors)上,参考多尺度和长宽比的anchor盒来分类和回归边界框,用于解决多尺度和多长宽比问题。
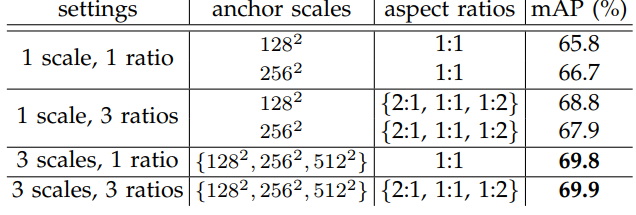
mAP指平均精度均值,mean Average Precision。
Loss函数
为了训练RPN,为每个anchor分配一个二值标签。
正标签:
- 与真值框的最高重叠交并比(Intersection-over-Union,IoU)比的anchor;
- 与真值框的重叠IoU值超过0.7的anchor。
注:单个真值框可为多个anchor分配正标签。通常,采用第一个条件。在极少情况下,第二个条件可能无正样本。
负标签:IoU值低于0.3。
对Fast R-CNN中的多任务损失进行最小化。图像的损失函数为:
其中,是mini-batch数据中anchor的索引,
是第i个anchor作为目标的预测概率。若anchor为正标签,真值
;反之,
。
是表示预测边界框4个参数化坐标的向量,
是正真值框的向量。分类损失
为两个类别的对数损失;回归损失
,其中
为在Fast R-CNN一文中定义的鲁棒损失函数(平滑
)。
表示回归损失仅对正anchor激活,否则被禁用(
)。cls和rge层的输出分别由
和
组成。该两项使用
和
进行标准化,并使用平衡参数
加权处理。等式中cls项根据mini-batch的大小进行归一化,而reg项根据anchor位置的数据进行归一化。默认情况下,
从而使得cls和reg项的权重大致相等。
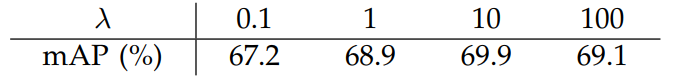
实验结果表明,
值在宽泛的范围内不敏感,且对reg和cls两项的归一化可简化。
对于边界框回归,采用Rich feature hierarchies for accurate object detection and semantic segmentation一文中的4个坐标参数化方法:
其中,和
表示边界框的中心坐标及其宽和高。变量
和
分别表示预测边界框、anchor和真值框。
RPN训练策略
采样策略:以图像为中心。
在图像中随机采样256个anchors,用于mini-batch数据中损失函数的计算,正负样本的比例为。
若图像中的正样本数量少于128个,则使用负样本数据补充mini-batch中的数据。
从标准差为0.01的零均值高斯分布中提取权重来随机初始化所有的新网络层,而共享卷积层通过预训练ImageNet分类模型来初始化。同时,调整ZF网络的所有网络层,以及VGG网络的conv3_1之上的网络,用于节省内存的使用。对于60k的mini-batch数据,学习率为0.001;对于PASCAL VOC数据集中的20k的mini-bacth数据,学习率为0.0001。随机梯度下降算法的动量设置为0.9,重量衰减率为0.0005。
RPN和Fast R-CNN共享特征
训练具有共享特征网络的三个方法:
- 交替训练。首先训练RPN,并使用这些proposals训练Fast R-CNN;然后,使用Fast R-CNN初始化RPN,重复上述过程。
本文使用的方法。
- 近似联合训练。在训练期间,RPN和Fast R-CNN网络合并为一个网络。在每次SGD迭代中,前向传递生成region proposals,在训练Fast R-CNN检测器时作为固定的、预计算的proposals。共享层组合来自RPN损失和Fast R-CNN损失的反向传播信息。
相比于交替训练方法,训练时间减少了大约25~50%。
- 非近似的联合训练。


