Volley 源码分析
我的博客: Volley 源码分析
Volley 的使用流程分析
官网示例
- 创建一个请求队列
RequestQueue,并启动队列 - 创建一个请求
Request添加到请求队列中
创建 RequestQueue 对象
final TextView mTextView = (TextView) findViewById(R.id.text);
...
// 实例化一个请求队列
RequestQueue queue = Volley.newRequestQueue(this);
String url ="http://www.google.com";
// 创建一个期待类型为字符串类型的请求
StringRequest stringRequest = new StringRequest(Request.Method.GET, url,
new Response.Listener<String>() {
@Override
public void onResponse(String response) {
// Display the first 500 characters of the response string.
mTextView.setText("Response is: "+ response.substring(0,500));
}
}, new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
mTextView.setText("That didn't work!");
}
});
// 将请求添加到请求队列中
queue.add(stringRequest);
上面代码片段的第5行,我们调用 Volley.newRequestQueue(this) 来创建一个请求队列。Volley 中提供了两种创建请求队列的方法,newRequestQueue(Context context,HttpStack stack) 和 newRequestQueue(Context context)
public static RequestQueue newRequestQueue(Context context) {
// 在此方法内部会调用另一个 newRequestQueue 方法,第二个参数为 null 代表使用默认的 HttpStack 实现
return newRequestQueue(context, null);
}
public static RequestQueue newRequestQueue(Context context, HttpStack stack) {
// 缓存文件目录 data/data/packagename/cache/volley
File cacheDir = new File(context.getCacheDir(), DEFAULT_CACHE_DIR);
String userAgent = "volley/0";
try {
String packageName = context.getPackageName();
PackageInfo info = context.getPackageManager().getPackageInfo(packageName, 0);
userAgent = packageName + "/" + info.versionCode;
} catch (NameNotFoundException e) {
}
if (stack == null) {
if (Build.VERSION.SDK_INT >= 9) {
stack = new HurlStack();//基于HttpClient
} else {
//基于HttpUrlConnection
stack = new HttpClientStack(AndroidHttpClient.newInstance(userAgent));
}
}
//利用HttpStack创建一个Network对象
Network network = new BasicNetwork(stack);
//创建一个RequestQueue对象,在构造函数中传入缓存对象,网络对象
RequestQueue queue = new RequestQueue(new DiskBasedCache(cacheDir), network);
//启动队列
queue.start();
return queue;
}
在上面代码片段中的第2行可以看见,Volley 调用 getCacheDir() 方法来获取缓存目录,Volley 中的缓存文件会存储在 /data/data/packagename/cache 目录下面,并不是存储在 SD 卡中的。
从12~18的代码可以看见,Volley 当中有对 HttpStack 的默认实现,HttpStack 是真正用来执行请求的接口 ,根据版本号的不同,实例化不同的对象,在 Android2.3 版本之前采用基于 HttpClient 实现的 HttpClientStack 对象,不然则采用基于 HttpUrlConnection 实现的 HUrlStack。
之后我们通过 HttpStack 构建了一个 Network 对象,它会调用 HttpStack#performRequest() 方法来执行请求,并且将请求的结果转化成 NetworkResponse 对象,NetworkResponse 类封装了响应的响应码,响应体,响应头等数据。
接着我们会将之前构建的缓存目录以及网络对象传入 RequestQueue(Cache cache, Network network) 的构造函数中,构造一个 RequestQueue 对象,然后调用队列的 start()方法来启动队列,其实就是启动队列中的两种线程:
//启动队列中所有的调度线程.
public void start() {
stop(); // 确保停止所有当前正在运行的调度线程
// 创建缓存调度线程,并启动它,用来处理缓存队列中的请求
mCacheDispatcher = new CacheDispatcher(mCacheQueue,mNetworkQueue,mCache,mDelivery);
mCacheDispatcher.start();
// 创建一组网络调度线程,并启动它们,用来处理网络队列中的请求,默认线程数量为4,也可以通过RequestQueue的构造函数指定线程数量。
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue,mNetwork,mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
networkDispatcher.start();
}
}
在 start() 方法中,主要是启动了两种线程分别是 CacheDispatcher 和 NetworkDispatcher,它们都是线程类,顾名思义 CacheDispatcher 线程会处理缓存队列中请求,NetworkDispatcher 处理网络队列中的请求,由此可见在我们调用 Volley 的公开方法创建请求队列的时候,其实就是开启了两种线程在等待着处理我们添加的请求。
添加请求 add(Request)
之前我们已经创建了 RequestQueue 对象,现在我们只需要构建一个 Request 对象,并将它加入到请求队列中即可。下面我们来看看 add(Request<T> request) 方法:
public <T> Request<T> add(Request<T> request) {
// 将请求加入到当前请求队列当中,毋庸置疑的我们需要将所有的请求集合在一个队列中,方便我们做统一操作,例如:取消单个请求或者取消具有相同标记的请求...
request.setRequestQueue(this);
synchronized (mCurrentRequests) {
mCurrentRequests.add(request);
}
// 给请求设置顺序.
request.setSequence(getSequenceNumber());
request.addMarker("add-to-queue");
// 如果请求是不能够被缓存的,直接将该请求加入网络队列中.
if (!request.shouldCache()) {
mNetworkQueue.add(request);
return request;
}
// 如果有相同的请求正在被处理,就将请求加入对应请求的等待队列中去.等到相同的正在执行的请求处理完毕的时候会调用 finish()方法,然后将这些等待队列中的请求全部加入缓存队列中去,让缓存线程来处理
synchronized (mWaitingRequests) {
String cacheKey = request.getCacheKey();
if (mWaitingRequests.containsKey(cacheKey)) {
// 有相同请求在处理,加入等待队列.
Queue<Request<?>> stagedRequests = mWaitingRequests.get(cacheKey);
if (stagedRequests == null) {
stagedRequests = new LinkedList<>();
}
stagedRequests.add(request);
mWaitingRequests.put(cacheKey, stagedRequests);
if (VolleyLog.DEBUG) {
VolleyLog.v("Request for cacheKey=%s is in flight, putting on hold.", cacheKey);}
} else {
// 向mWaitingRequests中插入一个当前请求的空队列,表明当前请求正在被处理
mWaitingRequests.put(cacheKey, null);
mCacheQueue.add(request);
}
return request;
}
}
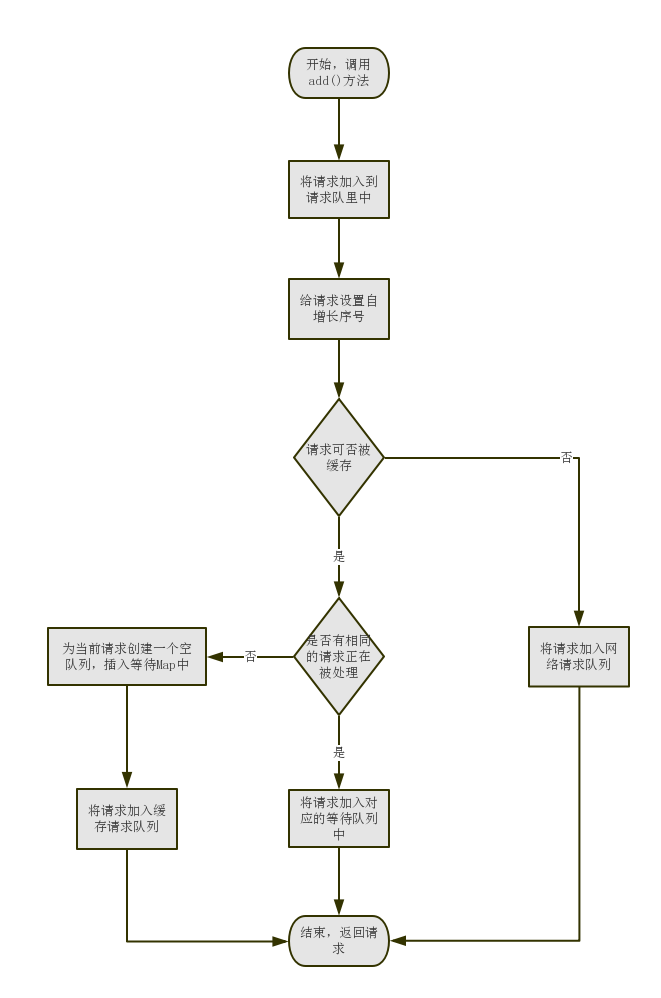 add.png-53.6kB
add.png-53.6kB
RequestQueue#add(Request) 方法的调用流程
处理请求 Cache/NetworkDispatcher
请求被加入缓存请求队列或者是网络请求队列,在后台我们的缓存处理线程,网络处理线程,一直在运行着等待着请求的到来。我们先来看看 CacheDispatcher 线程是如何处理的:
CacheDispatcher
public CacheDispatcher(
BlockingQueue<Request<?>> cacheQueue, BlockingQueue<Request<?>> networkQueue,
Cache cache, ResponseDelivery delivery) {
mCacheQueue = cacheQueue;
mNetworkQueue = networkQueue;
mCache = cache;
mDelivery = delivery;
}
这是 CacheDispatcher 的构造函数,可以看见该对象内部持有缓存队列,网络队列,缓存对象,响应投递对象的引用。
@Override
public void run() {
if (DEBUG) VolleyLog.v("start new dispatcher");
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
// 初始化缓存,将缓存目录下的所有缓存文件的摘要信息加载到内存中.
mCache.initialize();
//无线循环,意味着线程启动之后会一直运行
while (true) {
try {
// 从缓存队列中取出一个请求,如果没有请求则一直等待
final Request<?> request = mCacheQueue.take();
request.addMarker("cache-queue-take");
// 如果当前请求已经取消,那就停止处理它
if (request.isCanceled()) {
request.finish("cache-discard-canceled");
continue;
}
// 尝试取出缓存实体对象
Cache.Entry entry = mCache.get(request.getCacheKey());
if (entry == null) {
request.addMarker("cache-miss");
// 没有缓存,将当前请求加入网络请求队列,让NetworkDispatcher进行处理.
mNetworkQueue.put(request);
continue;
}
// 如果缓存实体过期,任然将当前请求加入网络请求队列,让NetworkDispatcher进行处理.
if (entry.isExpired()) {
request.addMarker("cache-hit-expired");
request.setCacheEntry(entry);
mNetworkQueue.put(request);
continue;
}
// 将缓存实体解析成NetworkResponse对象.
request.addMarker("cache-hit");
Response<?> response = request.parseNetworkResponse(
new NetworkResponse(entry.data, entry.responseHeaders));
request.addMarker("cache-hit-parsed");
if (!entry.refreshNeeded()) {
// 缓存依旧新鲜,投递响应.
mDelivery.postResponse(request, response);
} else {
//缓存已经不新鲜了,我们可以进行响应投递,然后将请求加入网络队列中去,进行新鲜度验证,如果响应码为 304,代表缓存新鲜可以继续使用,不用刷新响应结果
request.addMarker("cache-hit-refresh-needed");
request.setCacheEntry(entry);
// 标记当前响应为中间响应,如果经过服务器验证缓存不新鲜了,那么随后将有第二条响应到来.这意味着当前请求并没有完成,只是暂时显示缓存的数据,等到服务器验证缓存的新鲜度之后才会将请求标记为完成
response.intermediate = true;
// 将响应投递给用户,然后加入网络请求队列中去.
mDelivery.postResponse(request, response, new Runnable() {
@Override
public void run() {
try {
mNetworkQueue.put(request);
} catch (InterruptedException e) {
// Not much we can do about this.
}
}
});
}
} catch (InterruptedException e) {
// We may have been interrupted because it was time to quit.
if (mQuit) {
return;
}
}
}
}
在代码的注释中基本上可以理清 CacheDispatcher 的工作流程,下面附上流程图
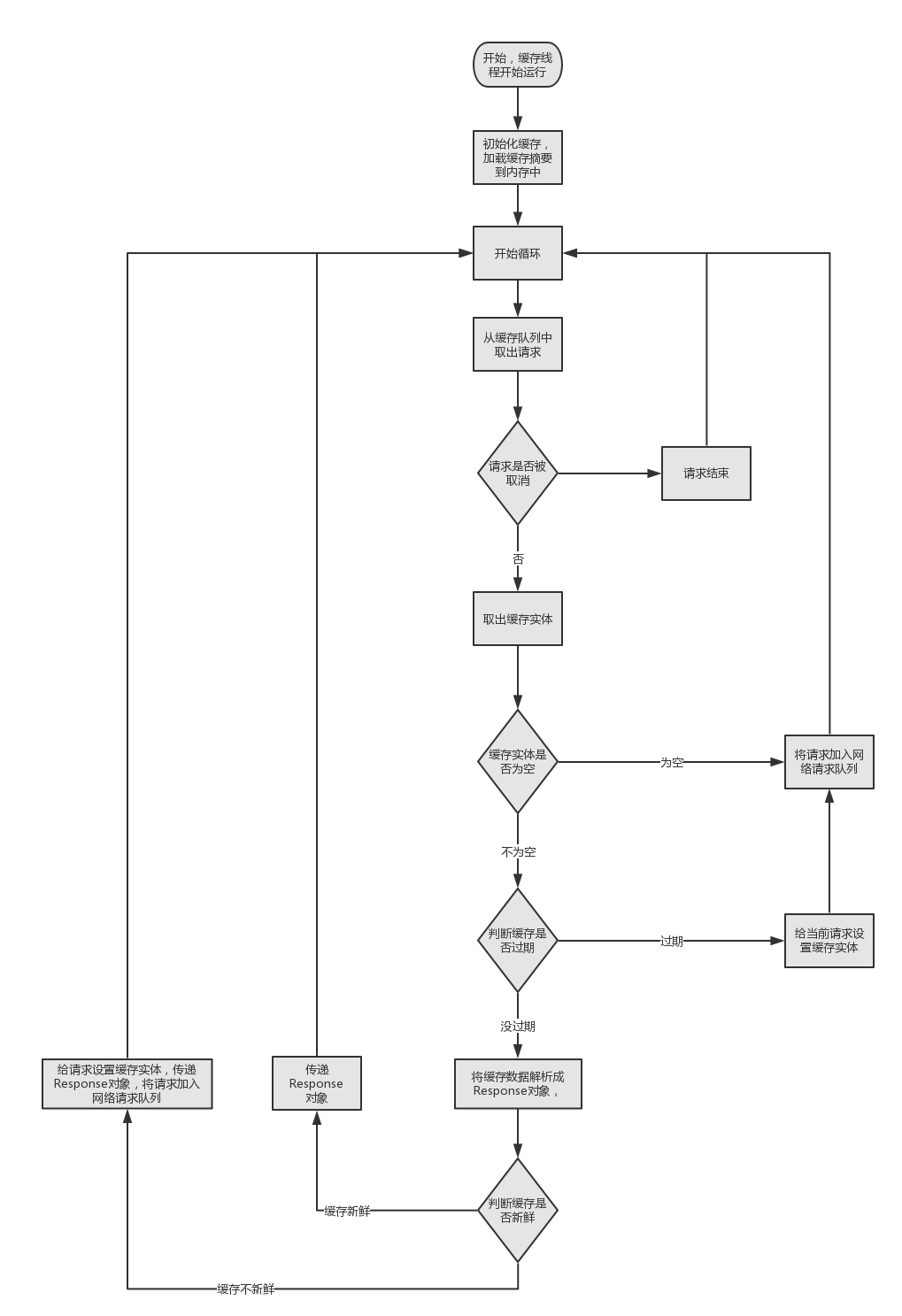 缓存run方法 .png-95.6kB
缓存run方法 .png-95.6kB
CacheDispatcher#run() 方法内部流程
NetworkDispatcher
在 CacheDispatcher 当中我们会把一些不符合条件的请求加入网络请求队列中,下面我们来看看在 NetworkDispatcher 的 run() 方法中是怎么来处理这些请求的:
public NetworkDispatcher(BlockingQueue<Request<?>> queue,
Network network, Cache cache,ResponseDelivery delivery) {
mQueue = queue;
mNetwork = network;
mCache = cache;
mDelivery = delivery;
}
这是 NetworkDispatcher 的构造函数,可以看见该对象内部持有网络队列,缓存对象,响应投递对象,Network对象的引用。
@Override
public void run() {
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
while (true) {
long startTimeMs = SystemClock.elapsedRealtime();
Request<?> request;
try {
// 从网络队列中取出一个请求,没有请求则一直等待.
request = mQueue.take();
} catch (InterruptedException e) {
// We may have been interrupted because it was time to quit.
if (mQuit) {
return;
}
continue;
}
try {
request.addMarker("network-queue-take");
// 如果请求被取消的话,就结束当前请求,不再执行
if (request.isCanceled()) {
request.finish("network-discard-cancelled");
continue;
}
addTrafficStatsTag(request);
// 执行网络请求.
NetworkResponse networkResponse = mNetwork.performRequest(request);
request.addMarker("network-http-complete");
// 如果响应码为304,并且我们已经传递了一次响应,不需要再传递一次验证的响应,意味着本次请求处理完成。也就是说该请求的缓存是新鲜的,我们直接使用就可以了。
if (networkResponse.notModified && request.hasHadResponseDelivered()) {
request.finish("not-modified");
continue;
}
// 在工作线程中想响应数据解析成我们需要的Response对象,之所以在工作线程进行数据解析,是为了避免一些耗时操作造成主线程的卡顿.
Response<?> response = request.parseNetworkResponse(networkResponse);
request.addMarker("network-parse-complete");
// 如果允许,则将响应数据写入缓存,这里的缓存是需要服务器支持的,这点我们接下来再说
// TODO: Only update cache metadata instead of entire record for 304s.
if (request.shouldCache() && response.cacheEntry != null) {
mCache.put(request.getCacheKey(), response.cacheEntry);
request.addMarker("network-cache-written");
}
// 传递响应数据.
request.markDelivered();
mDelivery.postResponse(request, response);
} catch (VolleyError volleyError) {
volleyError.setNetworkTimeMs(SystemClock.elapsedRealtime() - startTimeMs);
parseAndDeliverNetworkError(request, volleyError);
} catch (Exception e) {
VolleyLog.e(e, "Unhandled exception %s", e.toString());
VolleyError volleyError = new VolleyError(e);
volleyError.setNetworkTimeMs(SystemClock.elapsedRealtime() - startTimeMs);
mDelivery.postError(request, volleyError);
}
}
}
在代码当中的第29行,我们调用 Network 对象的 performRequest(Request<?> request) 方法来执行网络请求,并且返回我们需要的 NetworkResponse 对象。如果是304响应,并且我们已经传递过一次响应,就不需要在传递新的解析数据,不然我们将数据解析成 Reponse 对象,并传递给主线程进行回到处理,如果该请求允许被缓存,就将该请求的结果写入缓存中去,这就是 Networkdispatcher 的工作流程。以下是 NetworkDispatcher 的流程图:
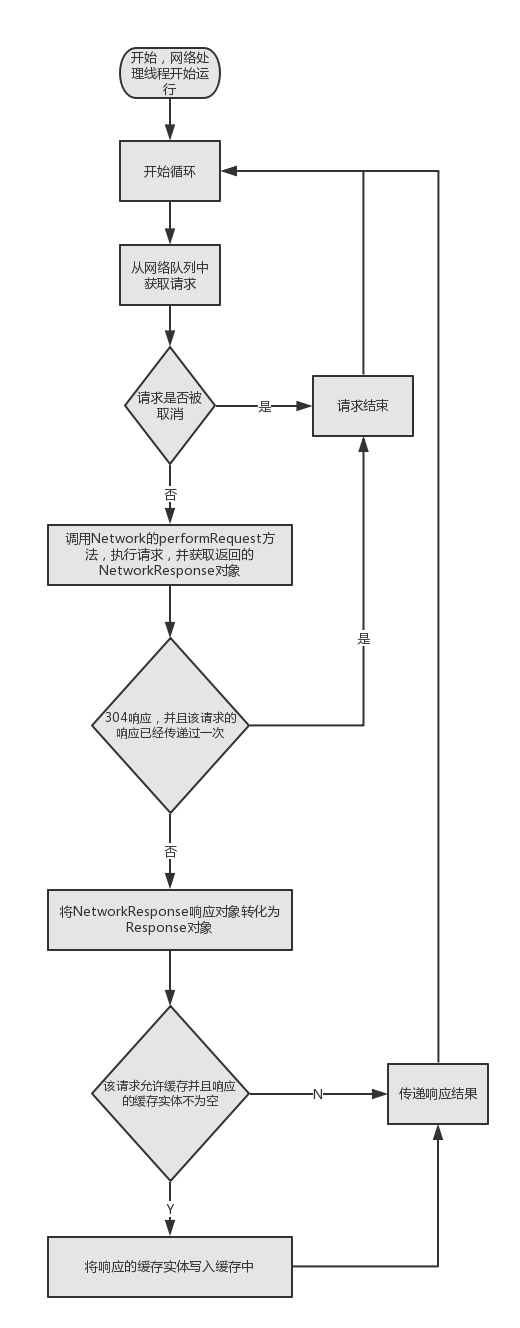 网络处理线程run方法.png-73.9kB
网络处理线程run方法.png-73.9kB
NetworkDispatcher的run() 方法
执行请求 performRequest
在上面 NetworkDispatcher 的代码中第29行,会通过 Network 的 performRequest 方法来进行网络请求:
public interface Network {
/**
* 执行指定的请求.
* @param request 被处理的请求
* @return 一个 NetworkResponse 对象,包含响应的数据,头部以及响应码等数据
* @throws VolleyError on errors
*/
NetworkResponse performRequest(Request<?> request) throws VolleyError;
}
Network 是一个接口,它的内部只有这一个方法,在 Volley 中我们最终调用的是它的实现类,BasicNetwork 的 performRequest() 方法,方法如下所示:
@Override
public NetworkResponse performRequest(Request<?> request) throws VolleyError {
long requestStart = SystemClock.elapsedRealtime();//请求开始的时间
while (true) {
HttpResponse httpResponse = null;
byte[] responseContents = null;
Map<String, String> responseHeaders = Collections.emptyMap();
try {
// 收集头部
Map<String, String> headers = new HashMap<String, String>();
//对于addCacheHeaders这个方法,我们也会在缓存的部分进行介绍
addCacheHeaders(headers, request.getCacheEntry());//附加请求头部,用来验证缓存数据?
httpResponse = mHttpStack.performRequest(request, headers);
StatusLine statusLine = httpResponse.getStatusLine();
int statusCode = statusLine.getStatusCode();
responseHeaders = convertHeaders(httpResponse.getAllHeaders());
// 验证缓存的新鲜度.
if (statusCode == HttpStatus.SC_NOT_MODIFIED) {
//请求的资源没有修改,意思可以使用缓存中的数据
Cache.Entry entry = request.getCacheEntry();
if (entry == null) {
return new NetworkResponse(HttpStatus.SC_NOT_MODIFIED, null,
responseHeaders, true,SystemClock.elapsedRealtime() -requestStart);
}
// A HTTP 304 response does not have all header fields. We
// have to use the header fields from the cache entry plus
// the new ones from the response.
// http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3.5
entry.responseHeaders.putAll(responseHeaders);
return new NetworkResponse(HttpStatus.SC_NOT_MODIFIED, entry.data,
entry.responseHeaders, true,
SystemClock.elapsedRealtime() - requestStart);
}
// Some responses such as 204s do not have content. We must check.
if (httpResponse.getEntity() != null) {
responseContents = entityToBytes(httpResponse.getEntity());
} else {
// Add 0 byte response as a way of honestly representing a
// no-content request.
responseContents = new byte[0];
}
// if the request is slow, log it. 请求持续时间
long requestLifetime = SystemClock.elapsedRealtime() - requestStart;
logSlowRequests(requestLifetime, request, responseContents, statusLine);
if (statusCode < 200 || statusCode > 299) {
throw new IOException();
}
//一条真正的网络响应
return new NetworkResponse(statusCode, responseContents, responseHeaders, false,SystemClock.elapsedRealtime() - requestStart);
} catch (SocketTimeoutException e) {
//......这部分代码是用来进行请求重试的,我们随后在做解析
}
}
}
在上面代码的第12行,又会调用 HttpStack 对象的 performRequest() 方法去执行网络请求,在 HttpStack 中才真正进行网络请求,HttpStack 对象在我们一开始调用 Volley.newRequestQueue() 的方法时候初始化的,默认情况下,如果系统版本在 Android2.3 之前就会创建 HttpClientStack,之后就会创建 HUrlStack 对象,同样我们也可以实现自己的 HttpStack对象,通过 Volley 的重载方法 newRequestQueue(Context,HttpStack) 将我们自定义的 HttpStack 传入即可。
在代码的18行,我们会进行新鲜度验证,如果是304响应那么我们会直接利用缓存实体的数据。之后会将响应的数据组装成一个 NetworkResponse 对象返回。
在回到之前 NetworkDispatcher 的代码中,当我们获得这个 NetworkResponse 对象之后,如果是304响应那我们的请求处理结束,不然的话就会调用 Request#parseNetworkResponse(NetworkResponse) 方法将 NetworkResponse 对象解析成我们需要的 Response 对象,这是一个抽象方法,由子类具体实现来解析成期望的响应类型,此方法在工作线程调用。如果该请求可以被缓存,就会将响应实体写入缓存,标记请求被投递,然后调用 ResponseDelivery 对象的 postResponse() 方法来将解析的结果投递到主线程中,然后进行回调处理。
响应传递、回调 postResponse
响应结果投递接口,主要负责将响应的结果/错误,投递到主线程中,供回调函数处理:
public interface ResponseDelivery {
/**
* 传递从网络或者缓存中解析的Response对象.
*/
void postResponse(Request<?> request, Response<?> response);
/**
* 传递从网络或者缓存中解析的Response对象.提供一个Runnable对象,会在传递之后执行
*/
void postResponse(Request<?> request, Response<?> response, Runnable runnable);
/**
* 传递给定请求的Error
*/
void postError(Request<?> request, VolleyError error);
}
它的内部实现类为 ExecutorDelivery,让我们来看看 ExecutorDelivery 中的具体实现:
private final Executor mResponsePoster;
public ExecutorDelivery(final Handler handler) {
// Make an Executor that just wraps the handler.
mResponsePoster = new Executor() {
@Override
public void execute(Runnable command) {
handler.post(command);
}
};
}
@Override
public void postResponse(Request<?> request, Response<?> response, Runnable runnable) {
request.markDelivered();
request.addMarker("post-response");
mResponsePoster.execute(new ResponseDeliveryRunnable(request, response, runnable));
}
我们会在 postResponse 方法中调用 mResponsePoster 对象的 execute 方法,紧接着通过 handler 对象发送一个消息,这个消息是 ResponseDeliveryRunnable 对象,它是 Runnable 的实现类,并且这个 Runnable 对象会在主线程被执行,为什么呢?这是因为 handler 是在 ExecutorDelivery 初始化的时候作为参数传递出来的,我们可以看一下该构造函数调用的时机:
public RequestQueue(Cache cache, Network network, int threadPoolSize) {
this(cache, network, threadPoolSize,
new ExecutorDelivery(new Handler(Looper.getMainLooper())));
}
可以看见我们使用主线的 Looper 在构建一个 Handler对象,所以由该 Handler 对象发送的消息,都会在主线程被执行,不熟悉 Handler 机制的可以看下这篇文章 Android消息机制。
接着我们看看这个 ResponseDeliveryRunnable 类:
private class ResponseDeliveryRunnable implements Runnable {
//......省略
@SuppressWarnings("unchecked")
@Override
public void run() {
// If this request has canceled, finish it and don't deliver.
/** 如果请求已经取消的话,就不用在投递了*/
if (mRequest.isCanceled()) {
mRequest.finish("canceled-at-delivery");
return;
}
// Deliver a normal response or error, depending.
if (mResponse.isSuccess()) {
mRequest.deliverResponse(mResponse.result);
} else {
mRequest.deliverError(mResponse.error);
}
// If this is an intermediate response, add a marker, otherwise we're done
// and the request can be finished.
if (mResponse.intermediate) {
mRequest.addMarker("intermediate-response");
} else {
mRequest.finish("done");
}
// If we have been provided a post-delivery runnable, run it.
if (mRunnable != null) {
mRunnable.run();
}
}
}
这个 Runnable 会在主线程执行,然后将响应结果传递给请求的回调函数。在代码中的15,17行就是我们的回调函数,每一个请求的响应结果,不论是成功或者是失败,都会传递到这两个方法中,第15行的 deliverResponse 方法也是一个抽象方法,由子类实现,参照 Volley 提供的 StringRequest 可以看见,在这个方法中,我们最终将期望的对象传递给了 Response 中的 onResponse() 方法中,可以看 创建 RequestQueue 对象 这一段落的第一段代码中的12行
StringRequest stringRequest = new StringRequest(Request.Method.GET, url,
new Response.Listener<String>() {
@Override
public void onResponse(String response) {
// Display the first 500 characters of the response string.
mTextView.setText("Response is: "+ response.substring(0,500));
}
}, new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
mTextView.setText("That didn't work!");
}
});
请求的结果最终就会被传递这 onResponse,onErrorResponse 中。在这里贴一张 Volley 内部的 Response 转换流程图:
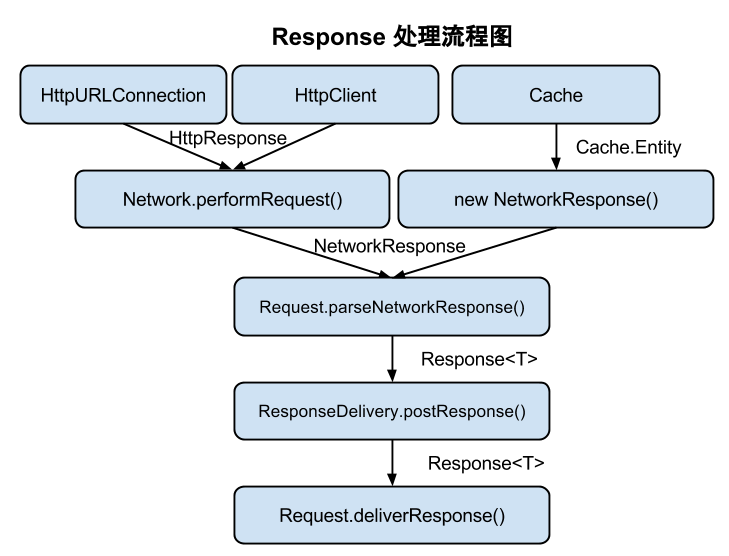 Response 处理流程图
Response 处理流程图
图片取自codeKK Volley 源码分析
请求完成 Request#finish(String)
在执行完我们的回调函数之后,会调用 Request 中的 finish() 方法标记请求完成,然后会将我们的请求从请求队列中移除,以下代码展示了两处调用 finish() 的地方:
if (mResponse.intermediate) {
mRequest.addMarker("intermediate-response");
} else {
mRequest.finish("done");
}
if (networkResponse.notModified && request.hasHadResponseDelivered()) {
request.finish("not-modified");
continue;
}
他们的区别是,第一段代码的 Response 是从网络返回的数据,而第二段代码是代表我们之前传递了需要验证缓存新鲜度的缓存实体,经验证后缓存新鲜,标记请求完成,大家可以查看一下 Response 的 intermediate 属性被赋值的时机就明白了。
// Request中的finish()会调用 RequestQueue中的finish()方法
void finish(final String tag) {
if (mRequestQueue != null) {
mRequestQueue.finish(this);
}
}
// RequestQueue#finish(Request)
<T> void finish(Request<T> request) {
//从当前的请求队列中移除该请求
synchronized (mCurrentRequests) {
mCurrentRequests.remove(request);
}
//调用该请求设置的回调函数
synchronized (mFinishedListeners) {
for (RequestFinishedListener<T> listener : mFinishedListeners) {
listener.onRequestFinished(request);
}
}
if (request.shouldCache()) {
synchronized (mWaitingRequests) {
String cacheKey = request.getCacheKey();
Queue<Request<?>> waitingRequests = mWaitingRequests.remove(cacheKey);
if (waitingRequests != null) {
if (VolleyLog.DEBUG) {
VolleyLog.v("Releasing %d waiting requests for cacheKey=%s.",
waitingRequests.size(), cacheKey);
}
// Process all queued up requests. They won't be considered as in flight, but
// that's not a problem as the cache has been primed by 'request'.
mCacheQueue.addAll(waitingRequests);
}
}
}
}
在移除已经完成的请求之后,如果该请求是可以缓存的,并且存在着等待该请求的等待队列,就将队列中的所有请求加入缓存队列(mCacheQueue) 中去,让缓存线程接着处理。
补充一点---取消请求
- 可以调用 Request 的 cancel() 方法来标记请求取消,这样我们的回调函数永远不会被调用
- 可以调用 RequstQueue 的 cancelAll(Object) 的方法来批量取消被打上 Object 标记的请求
- 可以调用 RequstQueue 的 cancelAll(RequestFilter) 的方法,按照自定义的过滤方法来取消符合过滤条件的请求
抽象的处理流程图
 抽象的流程图.png-43.3kB
抽象的流程图.png-43.3kB
通过 CacheDispatcher 和 NetworkDispatcher 两种线程不断的从 RequestQueue 中取出请求来处理,然后将获取的数据在子线程解析成我们需要的结果,通过 ResponseDelivery 的 postResponse 方法将结果投递到主线程中去,触发回调。
请求缓存和重试机制
再此之前我们先看一下 Request 类中的一些重要属性和方法:
Request<T>
所有请求的抽象类,T 类型代表请求期望的类型,也是响应最终被解析成的类型。支持 Get,Post,Put,Delete,Options,Trace,Head,Patch 共8种请求,提供 Low,Normal,Hight,Imediate 4种优先级。下面会挑出一些比较重要的字段和方法进行讲解:
- mShouldCache,用于标识请求是否允许缓存,缓存需要客户端和服务器的支持,这个字段仅仅代表客户端是否支持缓存
- mShouldRetryServerErrors,默认值为 false,代表在服务器返回响应码在 500~599的范围内的话(服务器错误),不进行请求重试
- mCacheEntry,该请求的缓存实体,在 CacheDispatcher 处理 CacheQueue 中请求的时候,会判断该请求之前是否有缓存存在,如果存在的话将缓存实体赋值给该字段。用于在服务器返回 304 响应的时候构建 NetworkResponse 对象
- mResponseDelivered,代表该请求的响应结果已经被投递到主线程,只有在响应被传递给主线程的时候标记为 true,它的作用同样是用来验证缓存一致性
- abstract protected Response<T> parseNetworkResponse(NetworkResponse response);抽象方法,将请求返回的结果解析成请求期望的类型,具体的解析方式需要子类实现
-
abstract protected void deliverResponse(T response);抽象方法,也同样需要子类自行实现,将解析后的结果传递给请求的回调函数
之前我们有提到过要实现请求缓存需要客户端和服务器端共同的支持才行。
请求缓存
之前我们说过,缓存机制是需要客户端和服务器端共同支持的。从客户端的角度来说:需要实现 Http 缓存相关的语义;从服务器的角度来说:需要允许请求的资源被缓存;我们先来看一些有关于 Http 请求头和响应头的概念:
HTTP 响应头
Cache-Control:指明当前资源的有效期,用来控制从缓存中取数据,还是需要将请求发送到服务器进行验证,重新取回数据,该头部有以下几个值:
- no-cache:使用缓存前必须先向服务器确认其有效性
- no-store:不缓存响应的任何内容,相同的请求都会发送给服务器
- max-age:缓存有效性的最长时间
- must-revalidate:可缓存,但是使用的时候必需向源服务器验证
- proxy-revalidate:要求中间缓存服务器对缓存的有效性进行确认
- stale-while-revalidate:在这段时间内,允许先使用缓存,但需要向服务器验证缓存的有效性
Expires:资源失效的日期,如果和 max-age 同时存在,以 max-age 时间为准
ETag:可将资源以字符串形式做唯一性标识的方式,服务器会为每份资源分配对应的 Etag 值
Last-Modified:资源最终被修改的时间
HTTP 请求头
If-None-Match:如果上一次响应的的响应头部中带有 ETag 响应头,再次请求的时候会将 ETag 的值作为 If-None-Match 请求头的值,当 If-None-Match 的值与请求资源的 Etag 不一致时,服务器会处理该请求,该字段用来获取最新的资源
If-Modified-Since:如果上一次响应的响应头部中带有 Last-Modified 响应头,那么再次请求的时候会将 Last-Modified 的值作为 If-Modified-Since 请求头的值,在If-Modified-Since 字段指定的之后,资源发生了更新,服务器会接受该请求,否则返回 304 响应
Entry
Cache接口中的内部类,代表着缓存实体
- data,这是一个字节数组,其实也就是我们响应的 Content 部分
- etag,用来验证缓存一致性的标记
- serverDate,数据从服务器返回的时间
- lastModified,访问的服务器资源上次被修改的时间
- ttl,数据的过期时间,在(softTtl-ttl)这段时间内我们可以使用缓存,但是必须向服务器验证缓存的有效性
- softTtl,数据的新鲜时间,缓存再次之前一直有效
- responseHeaders,响应头部
- boolean isExpired(),判断是否过期,ttl代表的时间小于当前时间就意味着过期了
- boolean refreshNeeded(),顾名思义,当softTtl代表的时间小于当前时间,就代表数据不新鲜了,需要刷新数据
下面我们来看看 Volley 中是怎么利用这些头部信息来对响应结果进行缓存处理的:
在 NetworkDispatcher 的 run() 方法中有这样一样代码
if (request.shouldCache() && response.cacheEntry != null) {
mCache.put(request.getCacheKey(), response.cacheEntry);
request.addMarker("network-cache-written");
}
想要缓存响应结果需要满足两个条件,第一条该请求允许缓存,我们创建的每一条请求都是默认支持缓存的;第二条就是响应对象中的缓存实体不为空。那么我们需要看一下缓存实体是在什么时候被创建的,在执行上述的 if 语句判断之前会执行这么一句代码 Response<?> response = request.parseNetworkResponse(networkResponse); 通过parseNetworkResponse 方法将 NetworkResponse 对象转化为 Response 对象,parseNetworkResponse 方法是一个抽象方法,我们看一下 StringRequest 中是如何重写该方法的:
@Override
protected Response<String> parseNetworkResponse(NetworkResponse response) {
String parsed;
try {
parsed = new String(response.data, HttpHeaderParser.parseCharset(response.headers));
} catch (UnsupportedEncodingException e) {
parsed = new String(response.data);
}
return Response.success(parsed, HttpHeaderParser.parseCacheHeaders(response));
}
在代码的最后一行,我们会发现 Response 中的 cacheEntry 字段的值来自于 HttpHeaderParser.parseCacheHeaders(response)方法的返回值,下面我们来看看该方法的内部实现:
public static Cache.Entry parseCacheHeaders(NetworkResponse response) {
long now = System.currentTimeMillis();
//提取响应头部信息
Map<String, String> headers = response.headers;
long serverDate = 0;//资源返回时间
long lastModified = 0;//资源上一次被修改的时间
long serverExpires = 0;//资源的有效时间,以maxAge为主
long softExpire = 0;//资源的新鲜时间,如果在该时间内,发起相同的请求,那么可以允许使用缓存的信息,不需要将请求发送给服务器。
long finalExpire = 0;//缓存过期时间,在该时间之后的请求,都将发送给服务器,无法使用缓存。
long maxAge = 0;//资源的有效时间,
//在 staleWhileRevalidate 时间内,我们可以先用缓存数据展示给用户,在向服务器验证缓存的有效性
long staleWhileRevalidate = 0;
boolean hasCacheControl = false;//代表是否有 Cache-Control 头部
boolean mustRevalidate = false;
String serverEtag = null;//资源在服务器中的标识
String headerValue;
headerValue = headers.get("Date");
if (headerValue != null) {
serverDate = parseDateAsEpoch(headerValue);
}
//获取 Cache-Contral 头部的相关信息
headerValue = headers.get("Cache-Control");
if (headerValue != null) {
hasCacheControl = true;
String[] tokens = headerValue.split(",");
for (int i = 0; i < tokens.length; i++) {
String token = tokens[i].trim();
if (token.equals("no-cache") || token.equals("no-store")) {
//如果出现了 no-cache,no-store指令,代表服务器不允许缓存响应,返回的 entry 对象为空
return null;
} else if (token.startsWith("max-age=")) {
//如果出现了 max-age指令,那么服务器允许缓存该响应,并且给出响应的过期时间
try {
maxAge = Long.parseLong(token.substring(8));
} catch (Exception e) {
}
} else if (token.startsWith("stale-while-revalidate=")) {
//这段时间处于新鲜时间和过期时间之间,在这段时间内发起的请求,都可以利用之前的缓存信息,但是需要将请求发送给服务器做验证,如果是304 响应,则请求结束,不然将重新传递响应结果。
try {
staleWhileRevalidate = Long.parseLong(token.substring(23));
} catch (Exception e) {
}
} else if (token.equals("must-revalidate") || token.equals("proxy-revalidate")) {
//代表不区分新鲜时间与过期时间,到了max-age指定的时间之后,请求都将发送给服务器用来验证缓存的有效性。
mustRevalidate = true;
}
}
}
headerValue = headers.get("Expires");
if (headerValue != null) {
serverExpires = parseDateAsEpoch(headerValue);
}
headerValue = headers.get("Last-Modified");
if (headerValue != null) {
lastModified = parseDateAsEpoch(headerValue);
}
serverEtag = headers.get("ETag");
// 在 Cache-Control 和 Expires 头部都存在的情况下,以Cache-Control为准
if (hasCacheControl) {
softExpire = now + maxAge * 1000;
finalExpire = mustRevalidate
? softExpire
: softExpire + staleWhileRevalidate * 1000;
} else if (serverDate > 0 && serverExpires >= serverDate) {
// Default semantic for Expire header in HTTP specification is softExpire.
softExpire = now + (serverExpires - serverDate);
finalExpire = softExpire;
}
Cache.Entry entry = new Cache.Entry();
entry.data = response.data;
entry.etag = serverEtag;
entry.softTtl = softExpire;
entry.ttl = finalExpire;
entry.serverDate = serverDate;
entry.lastModified = lastModified;
entry.responseHeaders = headers;
return entry;
}
这是一个静态工具方法,用于提取响应头部的信息,来构建一个 Cache.Entry 类型的缓存对象,针对该方法的分析都已经写在注释当中。现在我们已经了解了将响应转化为缓存的部分,下面我们来看看,Volley 是如何使用缓存的,在上面我们介绍 CacheDispatcher 工作流程的时候已经大致看过了处理缓存请求的过程,下面我再针对缓存的部分具体分析一下,下面是 CacheDispatcher run() 方法的部分代码:
Cache.Entry entry = mCache.get(request.getCacheKey());
if (entry == null) {
mNetworkQueue.put(request);
continue;
}
if (entry.isExpired()) {
request.addMarker("cache-hit-expired");
request.setCacheEntry(entry);
mNetworkQueue.put(request);
continue;
}
Response<?> response = request.parseNetworkResponse(
new NetworkResponse(entry.data, entry.responseHeaders));
if (!entry.refreshNeeded()) {
mDelivery.postResponse(request, response);
} else {
request.setCacheEntry(entry);
response.intermediate = true;
mDelivery.postResponse(request, response, new Runnable() {
@Override
public void run() {
try {
mNetworkQueue.put(request);
} catch (InterruptedException e) {
}
}
});
}
先从缓存中取出缓存实体,然后通过 isExpired() 判断该缓存有无过期,内部是通过 return this.ttl < System.currentTimeMillis(); 的形式来进行比较,ttl 的含义,在👆的代码中我们已经介绍过了,之后通过 return this.softTtl < System.currentTimeMillis();的方式来判断实体是否需要刷新,softTtl的值我们同样已经介绍过了,如果不需要刷新,那么我们就可以直接使用缓存,不然的话就需要向服务器验证缓存的有效性。那么如何通知服务器来进行验证呢,接下来我们看看执行请求的时候,在 BasicNetwork # performRequest() 中调用 HttpStack 执行请求执行,会调用 addCacheHeaders(headers, request.getCacheEntry()); 方法,用来附加请求头部信息,我们看看该方法内部的实现:
private void addCacheHeaders(Map<String, String> headers, Cache.Entry entry) {
// If there's no cache entry, we're done.
if (entry == null) {
return;
}
if (entry.etag != null) {
headers.put("If-None-Match", entry.etag);
}
if (entry.lastModified > 0) {
Date refTime = new Date(entry.lastModified);
headers.put("If-Modified-Since",DateUtils.formatDate(refTime));
}
}
结合我们上面对请求头的介绍,大家很容易明白这段代码的意思,如果资源没有发生改变,就会返回 304 响应码,告诉我们可以使用之前的缓存,对缓存的分析就到这里。
Byte[] 缓存
再次看一下下面这段代码:
// Some responses such as 204s do not have content. We must check.
if (httpResponse.getEntity() != null) {
responseContents = entityToBytes(httpResponse.getEntity());
} else {
// Add 0 byte response as a way of honestly representing a
// no-content request.
responseContents = new byte[0];
}
这段代码位于 BasicNetwork 的 performRequest() 方法中,用于将返回的 HttpEntity 对象转化为 byte[] 对象,这个字节数组最后将用于被转化为 T 类型的对象,也就是请求期望的对象,我们之所以没有直接返回 HttpEntity 对象,而把它解析成 byte[] 就是为之后 Request 的子类进行解析提供便利。
接下来,我们看一下用于转换数据的方法:
private byte[] entityToBytes(HttpEntity entity) throws IOException, ServerError {
PoolingByteArrayOutputStream bytes =
new PoolingByteArrayOutputStream(mPool, (int) entity.getContentLength());
byte[] buffer = null;
try {
InputStream in = entity.getContent();
if (in == null) {
throw new ServerError();
}
buffer = mPool.getBuf(1024);
int count;
while ((count = in.read(buffer)) != -1) {
bytes.write(buffer, 0, count);
}
return bytes.toByteArray();
} finally {
try {
// Close the InputStream and release the resources by "consuming the content".
entity.consumeContent();
} catch (IOException e) {
// This can happen if there was an exception above that left the entity in
// an invalid state.
VolleyLog.v("Error occurred when calling consumingContent");
}
mPool.returnBuf(buffer);
bytes.close();
}
}
上面的代码中有两种类型对象我们需要注意,一个是 PoolingByteArrayOutputStream 对象 bytes,另一个是 ByteArrayPool 对象 mPool。我们先说一下没有这两个对象之前的转化方式,首先我们从 HttpEntity 打开是一个输入流,然后构建一个缓冲字节数组 buffer,不断的将输入流的数据写入 buffer 中,在通过 ByteArrayOutputStream 不断的将 buffer 中的数据输入到 ByteArrayOutputStream 中的 buf 字节数组中,如果 buf 的大小不够,将会 new 出新的 byte[] 对象,赋值给 buf
在这个过程中,byte[] 对象被不断的创建和销毁,内存不断的分配和回收,如果处理不断可能会造成内存泄漏,消耗了系统资源,Volley 通过 ByteArrayPool 和 PoolingByteArrayOutputStream 来解决这个问题,先看一下 ByteArrayPool 的代码:
public class ByteArrayPool {
private final List<byte[]> mBuffersByLastUse = new LinkedList<byte[]>();//按照使用顺序排列的Buffer缓存
private final List<byte[]> mBuffersBySize = new ArrayList<byte[]>(64);//按照 byte[]大小排列的Buffer缓存
/** 当前缓存池中缓存的总大小 */
private int mCurrentSize = 0;
/**
* 缓存池上限,达到这个限制之后,最近最长时间未使用的 byte[] * 将被丢弃
*/
private final int mSizeLimit;
/** 通过 buffer 的大小进行比较 */
protected static final Comparator<byte[]> BUF_COMPARATOR = new Comparator<byte[]>() {
@Override
public int compare(byte[] lhs, byte[] rhs) {
return lhs.length - rhs.length;
}
};
public ByteArrayPool(int sizeLimit) {
mSizeLimit = sizeLimit;
}
// 从缓存池中获取所需的 byte[],如果没有大小合适的 byte[],将新new一个 byte[] 对象
public synchronized byte[] getBuf(int len) {
for (int i = 0; i < mBuffersBySize.size(); i++) {
byte[] buf = mBuffersBySize.get(i);
if (buf.length >= len) {
mCurrentSize -= buf.length;
mBuffersBySize.remove(i);
mBuffersByLastUse.remove(buf);
return buf;
}
}
return new byte[len];
}
// 将使用后的 byte[] 返还给 缓存池
public synchronized void returnBuf(byte[] buf) {
if (buf == null || buf.length > mSizeLimit) {
return;
}
mBuffersByLastUse.add(buf);
int pos = Collections.binarySearch(mBuffersBySize, buf, BUF_COMPARATOR);
if (pos < 0) {
pos = -pos - 1;
}
mBuffersBySize.add(pos, buf);
mCurrentSize += buf.length;
trim();
}
// 对缓存池数据进行修剪
private synchronized void trim() {
while (mCurrentSize > mSizeLimit) {
byte[] buf = mBuffersByLastUse.remove(0);
mBuffersBySize.remove(buf);
mCurrentSize -= buf.length;
}
}
}
简单的来说就是,ByteArrayPool 通过在内存中维护了两组 byte[] 对象,来减少重复创建 byte[] 的次数。当我们需要使用 byte[] 的时候,通过 Pool 来获取一个 byte[],当使用完毕的时候,再将该字节数组返回给 Pool。
在来看看 PoolingByteArrayOutputStream 的代码,他是 ByteArrayOutputStream 的子类,内部使用了 ByteArrayPool 来代替 new Byte[]操作,提高性能:
public class PoolingByteArrayOutputStream extends ByteArrayOutputStream {
/**
* 默认的 buf 大小
*/
private static final int DEFAULT_SIZE = 256;
private final ByteArrayPool mPool;
/**
* 如果写入的数据超出 buf 的大小,将会扩展 buf 的大小,之前通过 new Byte[] 来分配更大的空间,现在通过 ByteArrayPool 提供,避免创建对象
*/
public PoolingByteArrayOutputStream(ByteArrayPool pool) {
this(pool, DEFAULT_SIZE);
}
public PoolingByteArrayOutputStream(ByteArrayPool pool, int size) {
mPool = pool;
buf = mPool.getBuf(Math.max(size, DEFAULT_SIZE));
}
//关闭输出流,将使用的 buf 归还到缓冲池中
@Override
public void close() throws IOException {
mPool.returnBuf(buf);
buf = null;
super.close();
}
// GC 的时候调用,我们不能保证高方法的触发时机,所以最好手动调用 close 方法
@Override
public void finalize() {
mPool.returnBuf(buf);
}
/**
* 扩展 Buf 的大小
*/
private void expand(int i) {
// 判断 buffer 能否处理更多的byte,不能的话将要扩展 buffer 的大小
if (count + i <= buf.length) {
return;
}
byte[] newbuf = mPool.getBuf((count + i) * 2);
System.arraycopy(buf, 0, newbuf, 0, count);
mPool.returnBuf(buf);
buf = newbuf;
}
@Override
public synchronized void write(byte[] buffer, int offset, int len) {
expand(len);
super.write(buffer, offset, len);
}
@Override
public synchronized void write(int oneByte) {
expand(1);
super.write(oneByte);
}
}
内部的操作很简单,在每次写入的时候都会检查 buffer 大小是否合适,是否需要扩展,在输出流结束的时候,我们需要手动显示调用 close 方法,来归还从 ByteArrayPool 中扩展的 byte[]
请求重试
RetryPolicy
RetryPolicy 接口,代表着请求重试的行为:
public interface RetryPolicy {
//当前超时的时间
int getCurrentTimeout();
//当前重试的次数
int getCurrentRetryCount();
/**
* 准备重试
* 当抛出 VolleyError 即意味着停止重试
*/
void retry(VolleyError error) throws VolleyError;
}
在我们初始化 Request 的时候,会给 Request 设置一个默认的重试策略 DefaultRetryPolicy 下面我们来看看它的代码:
DefaultRetryPolicy
public class DefaultRetryPolicy implements RetryPolicy {
/** 当前超时毫秒数. */
private int mCurrentTimeoutMs;
/** 当前重试次数. */
private int mCurrentRetryCount;
/** 最大重试次数. */
private final int mMaxNumRetries;
/** 超时乘积因子,用来累计计算超时时间. */
private final float mBackoffMultiplier;
/** 默认超时时间 */
public static final int DEFAULT_TIMEOUT_MS = 2500;
/** 默认重试次数 */
public static final int DEFAULT_MAX_RETRIES = 1;
/** 默认超时乘积因子 */
public static final float DEFAULT_BACKOFF_MULT = 1f;
public DefaultRetryPolicy() {
this(DEFAULT_TIMEOUT_MS, DEFAULT_MAX_RETRIES, DEFAULT_BACKOFF_MULT);
}
public DefaultRetryPolicy(int initialTimeoutMs, int maxNumRetries, float backoffMultiplier) {
mCurrentTimeoutMs = initialTimeoutMs;
mMaxNumRetries = maxNumRetries;
mBackoffMultiplier = backoffMultiplier;
}
/**
* 返回当前超时时间
*/
@Override
public int getCurrentTimeout() {
return mCurrentTimeoutMs;
}
/**
* 返回当前重试次数.
*/
@Override
public int getCurrentRetryCount() {
return mCurrentRetryCount;
}
/**
* 返回超时乘积因子.
*/
public float getBackoffMultiplier() {
return mBackoffMultiplier;
}
/**
* 为下一次重试计算重试时间
* @param error 上一次请求的错误.
*/
@Override
public void retry(VolleyError error) throws VolleyError {
mCurrentRetryCount++;
//累计下一次重试的时间
mCurrentTimeoutMs += (mCurrentTimeoutMs * mBackoffMultiplier);
if (!hasAttemptRemaining()) {
throw error;
}
//抛出参数中传入的错误,就代表停止重试
}
/**
* 判断是否允许下一次重试
*/
protected boolean hasAttemptRemaining() {
return mCurrentRetryCount <= mMaxNumRetries;
}
}
默认的重试策略也挺简单的,每一次累计超时的时间,然后判断是否到达重试的上限,如果达到上限,就抛出入参的 VolleyError 代表停止重试,那么为什么抛出传入的参数,就可以停止重试了呢,我们继续看看 BasicNetwork 中的 performRequest() 方法:
public NetworkResponse performRequest(Request<?> request) throws VolleyError {
while (true) {
try{
//........省略
} catch (SocketTimeoutException e) {
attemptRetryOnException("socket", request, new TimeoutError());
} catch (ConnectTimeoutException e) {
attemptRetryOnException("connection", request, new TimeoutError());
} catch (MalformedURLException e) {
throw new RuntimeException("Bad URL " + request.getUrl(), e);
} catch (IOException e) {
int statusCode;
if (httpResponse != null) {
statusCode = httpResponse.getStatusLine().getStatusCode();
} else {
throw new NoConnectionError(e);
}
VolleyLog.e("Unexpected response code %d for %s", statusCode, request.getUrl());
NetworkResponse networkResponse;
if (responseContents != null) {
networkResponse = new NetworkResponse(statusCode, responseContents,responseHeaders, false, SystemClock.elapsedRealtime() - requestStart);
if (statusCode == HttpStatus.SC_UNAUTHORIZED ||
statusCode == HttpStatus.SC_FORBIDDEN) {
attemptRetryOnException("auth",
request, new AuthFailureError(networkResponse));
} else if (statusCode >= 400 && statusCode <= 499) {
// Don't retry other client errors.
throw new ClientError(networkResponse);
} else if (statusCode >= 500 && statusCode <= 599) {
if (request.shouldRetryServerErrors()) {
attemptRetryOnException("server",
request, new ServerError(networkResponse));
} else {
throw new ServerError(networkResponse);
}
} else {
// 3xx? No reason to retry.
throw new ServerError(networkResponse);
}
} else {
attemptRetryOnException("network", request, new NetworkError());
}
}
}
}
这部分的代码我们在上面分析 BasicNetwork 的代码的时候已经介绍过了,当时省略了 catch 块中的代码,catch 块中的代码就是用来实现请求重试的。
当捕获到 SocketTimeoutException 和 ConnectTimeoutException 异常的时候调用 attemptRetryOnException() 方法来进行重试,该方法中会调用 retryPolicy.retry(exception);方法,该方法我们已经分析过了,是用来计算请求超时时间,以及是否达到重试上限,如果可以重试,那么该方法执行完,会继续下一次循环,再次发起请求;当达到重试上线,无法进行重试的时候我们会抛出 VolleyError 的实例,在 BasicNetwork#performRequest() 中我们没有捕获 VolleyError 异常,因次会跳出循环,停止重试,该方法执行结束,在外部 NetworkDispatcher 的 run() 方法中捕获了该异常,将异常结果传递到主线程中供回调函数处理。
- ConnectTimeoutException 表示请求超时
- SocketTimeoutException 表示响应超时
在代码中同样对 AuthFailureError 以及服务器异常提供了重试操作。
一些总结
- Volley 可以帮助我们完成请求的自动调度处理,我们只需要将 Request 加入 RequestQueue 就可以了
- 提供了多个并发线程帮助处理请求,但是不适合大文件下载,因为在响应解析的过程中,会将所有响应的数据保存在内存中
- 提供了缓存(一定程度上符合 HTTP 语义)
- 支持请求的优先级,可以方便的取消请求(根据 Tag 或者自定义的过滤规则)
- 提供了请求重试机制,可以自定义重试机制(简单,方便)
- Volley 面向接口编程,采用组合(少用继承)的形式提供功能,可以自定义 Network,HttpStack,Cache 等实现,扩展性很高


