[译]用深度学习获取语义含义
同步至我的博客 UqRai`s
当我看到好的文章后我就会把它翻译下来放在博客里,一方面方便回顾,另一方面在翻译地过程中学习,可能有不准确的地方以原文为主
这篇内容是使用深度学习获取语义意义,了解如何以分布式方式处理大型自然语言文本,其中包括搭建spark的自然语言理解管道。原文地址:《Capturing semantic meanings using deep learning》
词嵌入是一种将词作为相对相似性与语义相似性相关的向量的技术。这种技术是无监督学习最成功的应用之一。自然语言处理(NLP)系统传统上将字编码为字符串,它们是任意的,并且不向系统提供关于可能存在于不同单词之间的关系的有用信息。词嵌入是NLP中的替代技术,其中来自词汇表的词或短语相对于词汇大小被映射到低维空间中的实数向量,并且向量之间的相似性与词语义相关。
例如,让我们来说,女人,男人,女王和王。我们可以得到它们的向量表示,并使用基本的代数运算来发现语义相似性。使用诸如余弦相似度的度量可以测量向量之间的相似性。所以,当我们减去这个词的矢量男子从词的矢量女人,那么它的余弦距离将接近字之间的距离女王减去单词王(见图1)。
W("woman")−W("man") ≃ W("queen")−W("king")
 Figure 1. Gender vectors. Source: Lior Shkiller
Figure 1. Gender vectors. Source: Lior Shkiller
提出了许多不同类型的模型来表示单词作为连续向量,包括潜在语义分析(LSA)和潜在的Dirichlet分配(LDA)。这些方法背后的想法是,相关的词通常会出现在相同的文档中。例如,背包, 学校, 笔记本和老师可能会一起出现。但学校,老虎,苹果和篮球可能不会一起出现。为了将单词表示为向量 - 使用类似单词将在类似文档中出现的假设 - LSA创建一个矩阵,其中行表示唯一的单词,列表示每个段落。然后,获得O'Reilly的每周数据通讯.
而不是计算和存储大量的数据,我们可以尝试创建一个神经网络模型,以便能够学习单词之间的关系,并有效地进行。
Word2Vec
最流行的一个词嵌入模型word2vec,通过创建Mikolov等。,2013年。该模型显示出巨大的效果和效率的提高。Mikolov等人提出了负采样方法作为一种更有效的方法来推导字嵌入。您可以在这里阅读更多。
该模型可以使用两种架构中的任一种来生成分布式表示的单词:连续的单词(CBOW)或连续的跳过。
接下来我们来看这两种架构。
CBOW模式
在CBOW架构中,该模型预测了周围环境词窗口中的当前单词。Mikolov等人因此使用目标词w之前和之后的n个词预测它。
单词序列相当于一组项目。因此,也可以替换术语单词和项目,这允许对协作过滤和推荐系统应用相同的方法。CBOW比跳过式模型快几倍,对频繁出现的单词的准确度略高一些(见下图)。
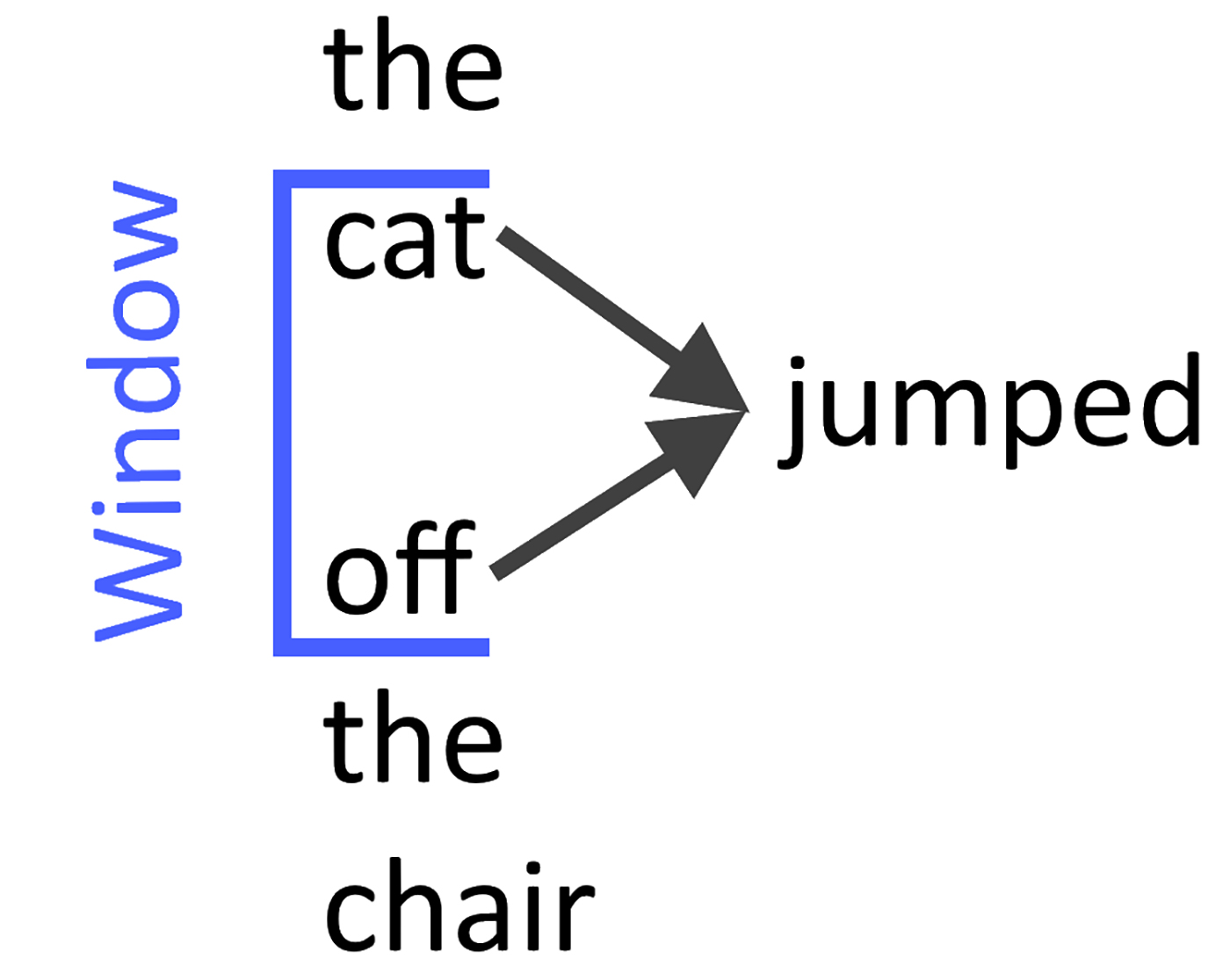 F2
F2
连续跳转模型
在跳格式模型中,不是使用周围的单词来预测中心词,而是使用中心词来预测周围的单词(见图3)。根据Mikolov等人的说法,skip-gram与少量的训练数据就可以工作得很好,并且很好地表达了罕见的单词和短语。
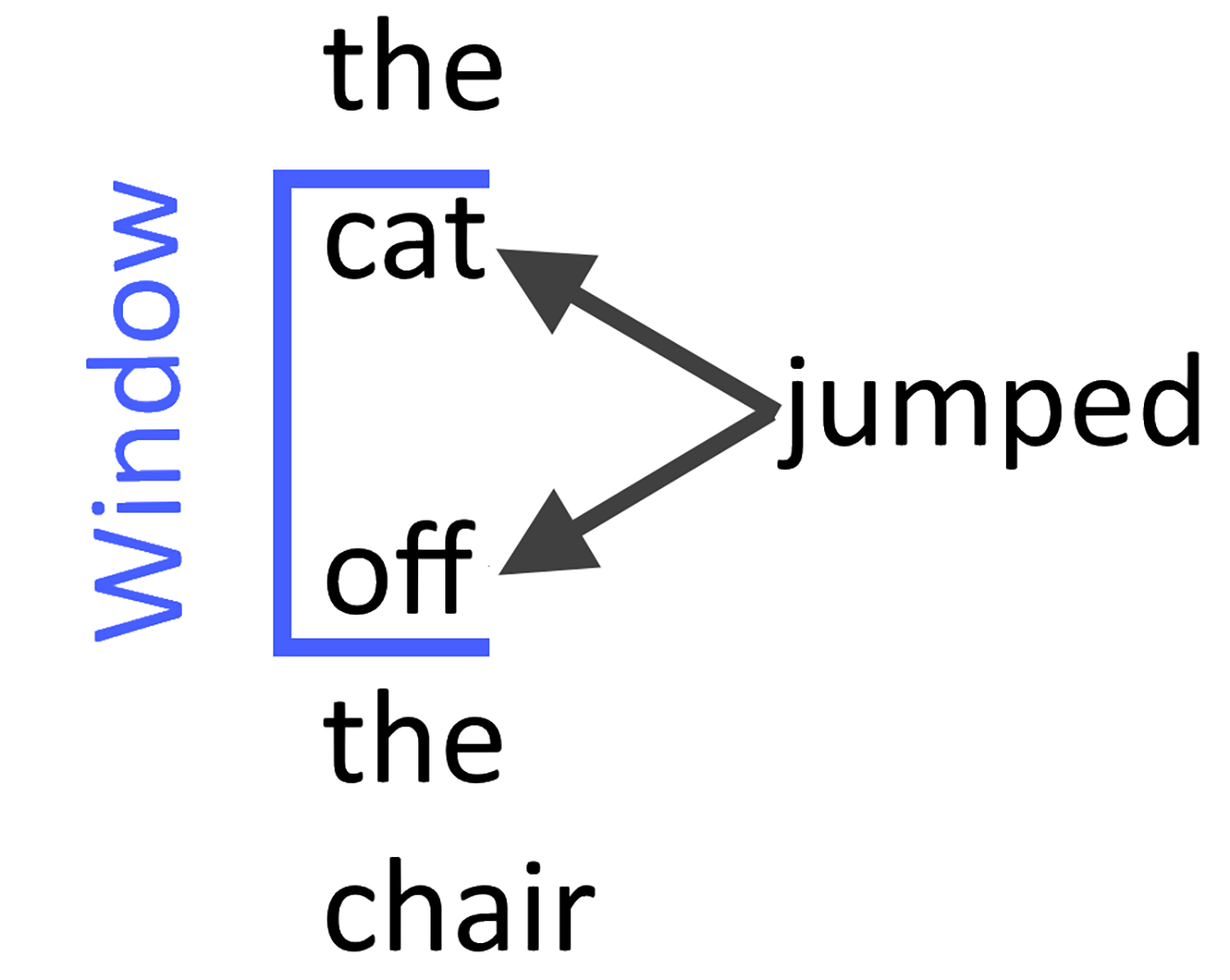
编码
这个模型的伟大之处在于,它可以很好地支持多种语言。
我们所要做的就是为我们需要的语言下载一个大数据集。
寻找维基百科的大数据集
我们可以寻找任何给定语言的维基百科。要获取大数据集,请按照下列步骤操作:
查找所需语言的ISO 639代码:ISO 639代码列表
转到:(https://dumps.wikimedia.org/维基/最新/)
下载 wiki-latest-pages-articles.xml.bz2
接下来,为了方便起见,我们将安装gensim,一个实现word2vec的Python包。
pip install --upgrade gensim
我们需要创建维基百科的语料库,我们将用它来训练word2vec模型。以下代码的输出是“wiki”.text“ - 其中包含维基百科中所有文章的所有单词,由语言分隔。
from gensim.corpora import WikiCorpus
language_code = "he"
inp = language_code+"wiki-latest-pages-articles.xml.bz2"
outp = "wiki.{}.text".format(language_code)
i = 0
print("Starting to create wiki corpus")
output = open(outp, 'w')
space = " "
wiki = WikiCorpus(inp, lemmatize=False, dictionary={})
for text in wiki.get_texts():
article = space.join([t.decode("utf-8") for t in text])
output.write(article + "\n")
i = i + 1
if (i % 1000 == 0):
print("Saved " + str(i) + " articles")
output.close()
print("Finished - Saved " + str(i) + " articles")
训练模型
参数如下:
- 大小:向量的维数
- 较大的尺寸值需要更多的训练数据,但可以导致更准确的模型
- 窗口:句子中当前和预测词之间的最大距离
- min_count:忽略总频率低于此值的所有单词
import multiprocessing
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
language_code = "he"
inp = "wiki.{}.text".format(language_code)
out_model = "wiki.{}.word2vec.model".format(language_code)
size = 100
window = 5
min_count = 5
start = time.time()
model = Word2Vec(LineSentence(inp), sg = 0, # 0=CBOW , 1= SkipGram
size=size, window=window, min_count=min_count, workers=multiprocessing.cpu_count())
# trim unneeded model memory = use (much) less RAM
model.init_sims(replace=True)
print(time.time()-start)
model.save(out_model)
训练word2vec花了18分钟。
fastText
Facebook的人工智能研究(FAIR)实验室最近发布了fastText,这是一个基于Bojanowski等人在文章“ 丰富词汇向量与字词信息 ”中所报告的工作的库。fastText是从word2vec不同之处在于每个字被表示为一个字符Ñ -grams。矢量表示与每个字符相关联Ñ -gram,和字被表示为这些表示的总和。
使用Facebook的库很容易:
pip安装fasttext
pip install fasttext
start = time.time()
language_code =“he”
inp =“wiki。{} .text”.format(language_code)
output =“wiki。{}。fasttext.model”.format(language_code)
model = fasttext.cbow inp,output)
print(time.time() - start)
训练fastText的模型花了13分钟。
评估嵌入式:类比
接下来,我们通过对我们前面的例子进行测试来评估模型:
W("woman")−W("man") ≃ W("queen")−W("king")
以下代码首先计算正负字的加权平均值。
之后,它计算所有测试词的向量表示和加权平均值之间的点积。
在我们的例子中,测试词是整个词汇。最后,我们打印出具有最高余弦相似度的词与正和负词的加权平均值。
import numpy as np
from gensim.matutils import unitvec
def test(model,positive,negative,test_words):
mean = []
for pos_word in positive:
mean.append(1.0 * np.array(model [pos_word]))
for neg_word in negative:
mean.append(-1.0 * np.array(model [neg_word]))
#计算所有单词的加权平均值
mean = unitvec(np.array(mean).mean(axis = 0))
scores = {}
for在test_words中的单词:
如果单词不在正面+负面:
test_word = unitvec(np.array(model [word]))
#余弦相似度
分数[word] = np.dot(test_word,mean)
print(sorted(scores,key = scores.get,reverse = True)[:1])
接下来,我们要测试我们的原始示例。
测试它在fastText和gensim的word2vec:
positive_words = ["queen","man"]
negative_words = ["king"]
# Test Word2vec
print("Testing Word2vec")
model = word2vec.getModel()
test(model,positive_words,negative_words,model.vocab)
# Test Fasttext
print("Testing Fasttext")
model = fasttxt.getModel()
test(model,positive_words,negative_words,model.words)
结果
Testing Word2vec
[‘woman’]
Testing Fasttext
[‘woman’]
这些结果意味着该过程在fastText和gensim的word2vec上都有效!
W("woman") ≃ W("man")+ W("queen")− W("king")
正如你所看到的,这些向量实际上捕获了这些单词之间的语义关系。
通过我们描述的模型提出的想法,可用于许多不同的应用,使企业能够预测他们将需要在未来的应用,进行情感分析,代表生物序列,执行图像语义搜索等。


