Java并发编程-线程池
参考资料:《Java高并发程序设计》
1.线程池
1.线程池简介
- 为了避免系统频繁地创建和销毁线程,可以通过线程池来复用线程。
- 使用了线程池后,创建线程变成了从线程池中获得空闲线程,关闭线程变成了向池子归还线程。
2.JDK对线程池的支持
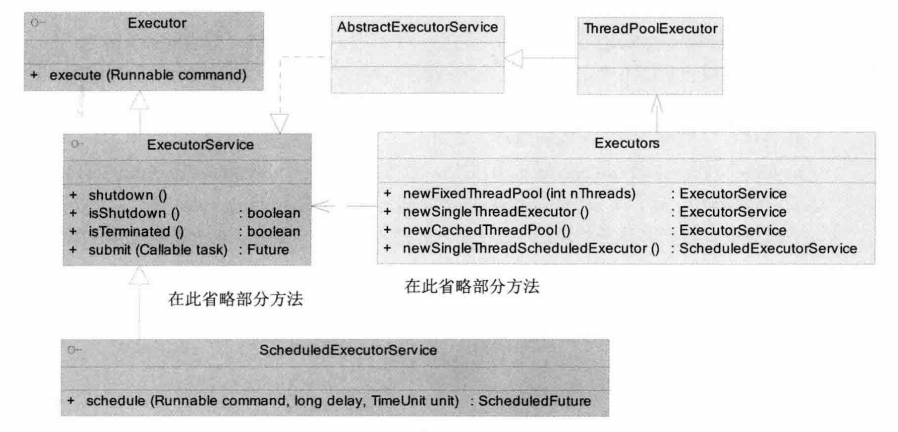
1.Executor框架类图
-
JDK提供了一套Executor框架,帮助开发人员有效地进行线程控制,其本质就是一个线程池。
-
Executor框架的核心成员类图如下:
 Executor框架.png-190.9kB
Executor框架.png-190.9kB
-
ThreadPoolExecutor表示一个线程池。ThreadPoolExecutor实现了Executor接口,因此通过该接口,任何Runnable的对象都可以被ThreadPoolExecutor线程池调度。
-
Executors则扮演者线程池工厂的角色。通过Executors可以取得一个拥有特定功能的线程池。
2.Executor框架提供的各种类型的线程池
- 通过Exectors的几个不同的静态方法,可以获得不同类型的线程池
1.newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor()
- 该方法返回一个只有一个线程的线程池。若多于一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
2.newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads)
- 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。否则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务
3.newCachedThreadPool
public static ExecutorService newCachedThreadPool()
- 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程把当前任务执行完毕后,将返回线程池进行复用。
4.newSingleThreadScheduledExecutor
public static ScheduledExecutorService newSingleThreadScheduledExecutor()
- 该方法返回一个ScheduledExecutorService对象,线程池大小为1。ScheduledExecutorService接口在ExecutorService接口之上扩展了在给定时间执行某任务的功能。如在某个固定的延时之后执行,或者周期性执行某个任务。
5.newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
- 该方法也返回一个ScheduledExecutorService对象,但该线程池可以指定
3.线程池的使用
1.ExecutorService
- 这里以newFixedThreadPool为例,展示ExecutorService线程池的使用:
public class Test {
private static final Runnable myTask = () -> {
System.out.println(System.currentTimeMillis() + ":Thread ID:" +
Thread.currentThread().getId());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
};
public static void main(String[] args) throws Exception {
ExecutorService es = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
es.submit(myTask);
}
}
}
// 输出:
// 1536546327052:Thread ID:11
// 1536546327051:Thread ID:10
// 1536546327053:Thread ID:12
// 1536546327053:Thread ID:13
// 1536546327053:Thread ID:14
// 1536546328053:Thread ID:11
// 1536546328053:Thread ID:10
// 1536546328053:Thread ID:12
// 1536546328053:Thread ID:13
// 1536546328053:Thread ID:14
- 上面的代码,在线程数为5的线程池中,提交了10个任务。从输出可以看到,这10个任务分两个批次执行,前后相差1秒,且前5个任务和后5个任务的线程ID也是完全一致的。
2.ScheduledExecutorService
- ScheduledExecutorService并不一定会立即安排执行任务,它起到的是计划任务的作用。主要方法如下:
// 在给定的时间对任务进行一次调度
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit);
// 周期性调度——以上一个任务开始时间为起点后延
// 若任务花费时间长于周期,则任务结束后立即开始下次调度
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
// 周期性调度——以上一个任务的结束时间为起点后延
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
- 代码演示:以scheduleAtFixedRate()方法调度一个任务,任务执行时长为1秒,调度周期为2秒:
public class Test {
public static void main(String[] args) throws Exception {
ScheduledExecutorService ses = Executors.newScheduledThreadPool(5);
ses.scheduleAtFixedRate(() -> {
try {
Thread.sleep(1000);
System.out.println(System.currentTimeMillis() / 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, 0, 2, TimeUnit.SECONDS);
}
}
// 部分输出:
// 1536547666
// 1536547668
// 1536547670
// 1536547672
- 另外需要注意的是:如果任务遇到 异常,那么后续的所有子任务都会停止调度,因此,必须保证异常被 及时处理,为周期性任务的 稳定调度 提供条件。
3.线程池的内部实现
1.ThreadPoolExecutor
- 上文提到的newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()虽然看起来功能特点完全不同,但内部实现均使用了 ThreadPoolExecutor。代码如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
- 由此可见,它们都只是ThreadPoolExecutor类的封装。为何ThreadPoolExecutor有如此强大的功能呢?来看一下它两个最重要的构造函数:
// newFixedThreadPool等使用的构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
// 最底层的构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- 最底层构造函数的参数含义如下:
- corePoolSize:线程池中的默认线程数量
- maximumPoolSize:线程池中的最大线程数量
- keepAliveTime:当线程池线程数量超过corePoolSize时,多余的空闲线程的存活时间。即超过corePoolSize的空闲线程,在多长时间内,会被销毁
- unit:keepAliveTime的单位
- workQueue:任务队列,被提交但尚未被执行的任务
- threadFactory:线程工厂,用于创建线程,一般用默认的即可
- handler:拒绝策略。当任务太多来不及处理,如何拒绝任务
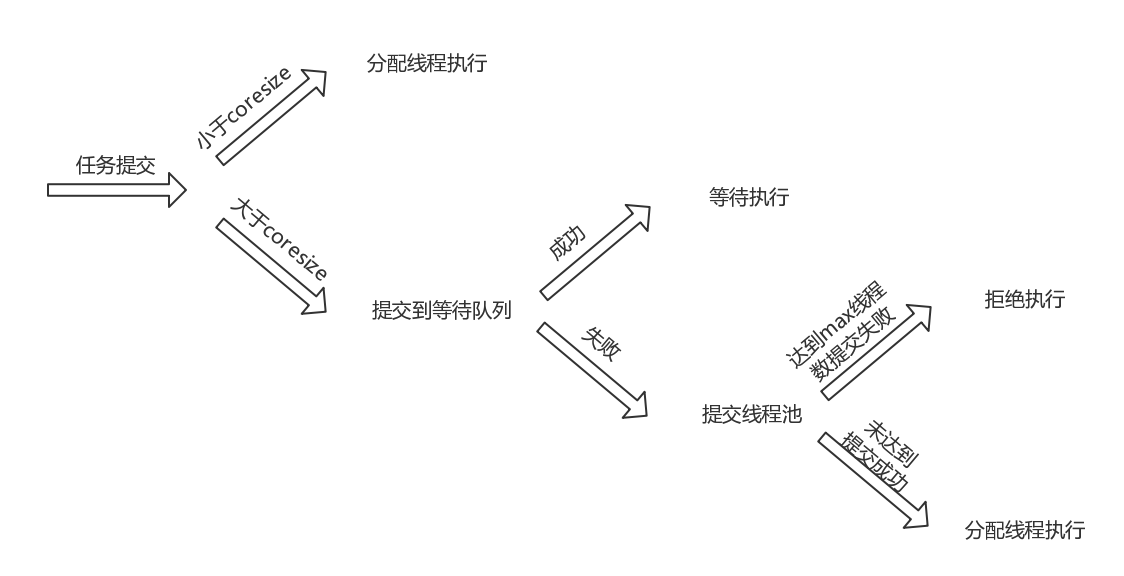
2.任务队列
- 参数workQueue指被提交但未执行的任务队列,它是一个BlockingQueue接口的对象,仅用于存放Runnable对象。根据队列功能分类,在ThreadPoolExecutor的构造函数中可使用以下几种BlockingQueue:
1.直接提交的队列:SynchronousQueue
- SynchronousQueue是一个特殊的BlockingQueue,它 没有容量,每一个插入操作都要等待一个相应的删除操作,反之,每一个删除操作都要等待对应的插入操作。
- 使用SynchronousQueue,提交的任务不会被真实的保存,而总是将新任务提交给线程执行,如果没有空闲线程,则尝试创建新的线程,如果线程数量已经达到最大值,则执行 拒绝策略。
- 因此使用SynchronousQueue,通常 要设置很大的maximumPoolSize,否则很容易执行拒绝策略。
2.有界的任务队列:ArrayBlockingQueue
- ArrayBlockingQueue的构造函数必须带一个 容量参数,表示该队列的最大容量:
public ArrayBlockingQueue(int capacity)
- 使用ArrayBlockingQueue时,若有新的任务需要执行,如果线程池的实际线程数小于corePoolSize,则会优先创建新的线程,若大于corePoolSize,则会将新任务加入等待队列。若等待队列已满,无法加入,则在总线程数不大于maximumPoolSize的前提下,创建新的线程执行任务。若大于maximumPoolSize,则执行拒绝策略
- 因此,ArrayBlockingQueue仅当任务队列装满时,才可能将线程数提升到corePoolSize之上,换言之,除非系统非常繁忙,否则确保核心线程数维持在corePoolSize。
3.无界的任务队列:LinkedBlockingQueue
- 与ArrayBlockingQueue相比,除非系统资源耗尽,否则LinkedBlockingQueue不存在任务入队失败的情况。
- 当有新的任务到来,系统的线程数小于corePoolSize时,线程池会生成新的线程执行任务,但当系统的线程数达到corePoolSize后,就不会继续增加。若后续仍有新的任务加入,而又没有空闲的线程资源,则任务直接进入队列等待。若任务创建和处理的速度差异很大,无界队列会保持快速增长,直到耗尽系统内存。
- LinkedBlockingQueue 用不到maximumPoolSize参数。
4.优先任务队列:PriorityBlockingQueue
- PriorityBlockingQueue是带有执行优先级的队列,可以控制任务的执行先后顺序。它是一个特殊的无界队列。之前介绍的无论是有界队列还是无界队列,都是安装先进先出算法处理任务的。而PriorityBlockingQueue则可以根据任务自身的优先级顺序先后执行。
使用自定义线程池时,要根据应用的具体情况,选择合适的并发队列作为任务的缓冲。当线程资源紧张时,不同的并发队列对系统行为和性能的影响均不同。
-
任务调度的逻辑可总结如下:
 任务调度.png-86.9kB
任务调度.png-86.9kB
3.拒绝策略
- 拒绝策略可以说是系统超负荷运行时的补救措施,通常由于压力太大而引起,也就是线程池中的线程已经用完了,无法继续为新任务服务,同时,等待队列中也已经排满了,再也塞不下新任务了。这是,就需要一套机制,合理地处理这个问题。
-
JDK内置了四种拒绝策略,也可进行自定义:
 四种拒绝策略.png-92kB
四种拒绝策略.png-92kB
1.AbortPolicy策略
- 该策略会直接抛出异常,阻止系统正常工作。
2.CallerRunsPolicy策略
- 只要线程池未关闭,该策略直接在调用者线程中运行当前被丢弃的任务。显然这样做不会真的丢弃任务,但是,任务提交线程的性能极有可能会急剧下降。
3.DiscardOledestPolicy策略
- 该策略将丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务。
4.DiscardPolicy策略
- 该策略默默地丢弃无法处理的任务,不予任何处理。如果允许任务丢失,这可能是最好的一种方案。
5.自定义拒绝策略
- 如果以上内置策略仍无法满足实际应用需要,完全可以自己扩展RejectedExecutionHandler接口。RejectedExecutionHandler定义如下:
public interface RejectedExecutionHandler {
// r:请求执行的任务
// executor:当前的线程池
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
- 下面的代码演示了如果自定义线程池和拒绝策略:
public class Test {
public static final Runnable myTask = () -> {
System.out.println(System.currentTimeMillis() + ":Thread ID:" +
Thread.currentThread().getId());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
};
public static void main(String[] args) throws Exception {
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingDeque<>(10),
Executors.defaultThreadFactory(),
((r, executor) -> System.out.println(r.toString() + " is discard")));
for (int i = 0; i < Integer.MAX_VALUE; i++) {
es.submit(myTask);
Thread.sleep(10);
}
}
}
// 部分输出:
// 1536576123894:Thread ID:11
// 1536576123915:Thread ID:13
// 1536576123919:Thread ID:14
// java.util.concurrent.FutureTask@17ed40e0 is discard
// java.util.concurrent.FutureTask@50675690 is discard
// java.util.concurrent.FutureTask@31b7dea0 is discard
- 可以看到在执行几个任务后,拒绝策略就开始生效了。在实际应用中,我们可以将更详细的信息记录到日志中,来分析系统的负载和任务丢失的情况。
4.自定义线程创建:ThreadFactory
- ThreadFactory是一个接口,只有一个方法,用来创建线程:
Thread newThread(Runnable r);
- 当线程池需要新建线程时,就会调用这个方法。
- 自定义线程可以帮助我们做不少事,比如:
- 可以跟踪线程池究竟在何时创建了多少线程
- 可以自定义线程的名称、组以及优先级等信息
- 可以任性地将所有线程设置为守护线程
- ...
- 总之,使用自定义线程可以让我们更加自由地设置池子中所有线程的状态。
- 下面的代码演示了使用自定义的ThreadFactory,一方面记录了线程的创建,另一方面将所有线程都设置为守护线程,这样,当主线程退出后,将会销毁线程池:
public static void main(String[] args) throws Exception {
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new SynchronousQueue<>(),
(r) -> {
Thread t = new Thread(r);
t.setDaemon(true);
System.out.println("create " + t);
return t;
});
for (int i = 0; i < Integer.MAX_VALUE; i++) {
es.submit(myTask);
}
Thread.sleep(2000);
}
4.线程池的AOP
-
ThreadPoolExecutor是一个可以扩展的线程池,它提供了beforeExecute()、afterExecute()、terminated()三个接口对线程池进行控制。
-
对于beforeExecute()、afterExecute(),在ThreadPoolExecutor.Worker.runTask()方法内部提供了这样的实现:
 runTask.png-307.4kB
runTask.png-307.4kB
-
注意runTask()会同时被多个线程访问,因此beforeExecute()、afterExecute()也将同时被多线程访问,注意线程安全。
-
默认的beforeExecute()、afterExecute()是空实现,在实际应用中,可以对其扩展来实现对线程运行状态的跟踪,输出一些调试信息以便系统诊断。例如:
public class Test {
public static class MyTask implements Runnable {
public String name;
public MyTask(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("正在执行" + System.currentTimeMillis() +
":Thread ID:" + Thread.currentThread().getId() +
",Task Name=" + name);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws Exception {
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingDeque<>()) {
// 任务开始时执行
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行:" + ((MyTask) r).name);
}
// 任务结束时执行
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("执行完毕:" + ((MyTask) r).name);
}
// 整个线程池退出时执行
@Override
protected void terminated() {
System.out.println("线程池退出");
}
};
for (int i = 0; i < 5; i++) {
es.execute(new MyTask("TASK-" + i));
Thread.sleep(10);
}
es.shutdown();
}
}
// 输出:
// 准备执行:TASK-0
// 正在执行1536637265198:Thread ID:10,Task Name=TASK-0
// 准备执行:TASK-1
// 正在执行1536637265208:Thread ID:11,Task Name=TASK-1
// 准备执行:TASK-2
// 正在执行1536637265219:Thread ID:12,Task Name=TASK-2
// 准备执行:TASK-3
// 正在执行1536637265229:Thread ID:13,Task Name=TASK-3
// 准备执行:TASK-4
// 正在执行1536637265253:Thread ID:14,Task Name=TASK-4
// 执行完毕:TASK-0
// 执行完毕:TASK-1
// 执行完毕:TASK-2
// 执行完毕:TASK-3
// 执行完毕:TASK-4
// 线程池退出
- 上述代码中,将任务提交完成后,调用shutdown()方法关闭线程池。这是一个比较安全的方法。如果当前有线程在执行,shutdown()方法并不会立即暴力地终止所有任务,它会等待所有已提交任务执行完成后,再关闭线程池。但它并不会等待所有线程执行完后再返回,因此可以简单地理解成shutdown()只是发送了一个关闭信号而已。但在shutdown()执行后,这个线程池就不能再接受其他新的任务了。
5.线程池的线程数量
-
只要避免极大和极小两种情况,线程池的大小对系统的性能不会影响太大。
-
一般来说,确定线程池的大小需要考虑CPU数量、内存大小等因素。
-
在《Java Concurrency in Practice》一书中给出了一个估算线程池大小的经验公式:
 threadnum.png-132.5kB
threadnum.png-132.5kB
-
在Java中可以通过Runtime.getRuntime().availableProcessors()取得可用的CPU数量。
6.线程池中的异常堆栈
1.一个发生异常却没有任何错误提示的demo
public class Test {
public static class DivTask implements Runnable {
int a, b;
public DivTask(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
System.out.println(a / b);
}
}
public static void main(String[] args) throws Exception {
ThreadPoolExecutor pool = new ThreadPoolExecutor(0, Integer.MAX_VALUE,
0L, TimeUnit.SECONDS, new SynchronousQueue<>());
for (int i = 0; i < 5; i++) {
pool.submit(new DivTask(100, i));
}
}
}
// 输出:
// 33
// 50
// 100
// 25
- 从以上代码的for循环来看,应该会得到5个结果,分别是100除以给定的i后的商。但运行的结果却只有4个输出。而且没有任何异常信息,就好像一切正常一样。简单分析代码不难发现是因为作为除数的i取到了0。但在稍复杂的业务场景中,这种错误会变的极难排查。
2.可以得到部分异常堆栈的方法:
1.放弃submit(),改用execute()
- 将上述的任务提交代码改成:
pool.execute(new DivTask(100, i));
- 得到的控制台输出:
100
50
33
25
Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero
at com.daojia.khpt.util.base.Test$DivTask.run(Test.java:33)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2.改造对submit()的用法
- 将代码改成:
Future future = pool.submit(new DivTask(100, i));
future.get();
- 得到的控制台输出:
Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.ArithmeticException: / by zero
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.daojia.khpt.util.base.Test.main(Test.java:42)
Caused by: java.lang.ArithmeticException: / by zero
at com.daojia.khpt.util.base.Test$DivTask.run(Test.java:33)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
- 注意,这里所说的部分,指的是我们只能知道异常是在哪里抛出的,而至于任务到底是在哪里提交的,已经被线程池完全淹没了。如果想要将这两部分的堆栈都拿到,那只能扩展ThreadPoolExecutor线程池了。
3.得到完整异常堆栈的方法:扩展ThreadPoolExecutor线程池
- 代码如下:
public class Test {
public static class TraceableThreadPoolExecutor extends ThreadPoolExecutor {
public TraceableThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void execute(Runnable command) {
super.execute(wrapTask(command, getClientStack(), Thread.currentThread().getName()));
}
@Override
public Future<?> submit(Runnable task) {
return super.submit(wrapTask(task, getClientStack(), Thread.currentThread().getName()));
}
private Exception getClientStack() {
return new Exception("client stack trace");
}
private Runnable wrapTask(Runnable task, Exception clientStack, String clientThreadName) {
return () -> {
try {
task.run();
} catch (Exception e) {
System.out.println("clientThreadName:" + clientThreadName);
clientStack.printStackTrace();
throw e;
}
};
}
}
public static class DivTask implements Runnable {
int a, b;
public DivTask(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
System.out.println(a / b);
}
}
public static void main(String[] args) throws Exception {
ThreadPoolExecutor pool = new TraceableThreadPoolExecutor(0, Integer.MAX_VALUE,
0L, TimeUnit.SECONDS, new SynchronousQueue<>());
for (int i = 0; i < 5; i++) {
pool.execute(new DivTask(100, i));
}
}
}
- 控制台输出:
clientThreadName:main
java.lang.Exception: client stack trace
at com.daojia.khpt.util.base.Test$TraceableThreadPoolExecutor.getClientStack(Test.java:43)
at com.daojia.khpt.util.base.Test$TraceableThreadPoolExecutor.execute(Test.java:34)
100
at com.daojia.khpt.util.base.Test.main(Test.java:77)
50
Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero
33
25
at com.daojia.khpt.util.base.Test$DivTask.run(Test.java:69)
at com.daojia.khpt.util.base.Test$TraceableThreadPoolExecutor.lambda$wrapTask$0(Test.java:49)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
end


