Swift 中的尾递归和蹦床
作者:uraimo,原文链接,原文日期:2016-05-05
译者:aaaron7;校对:numbbbbb;定稿:shanks
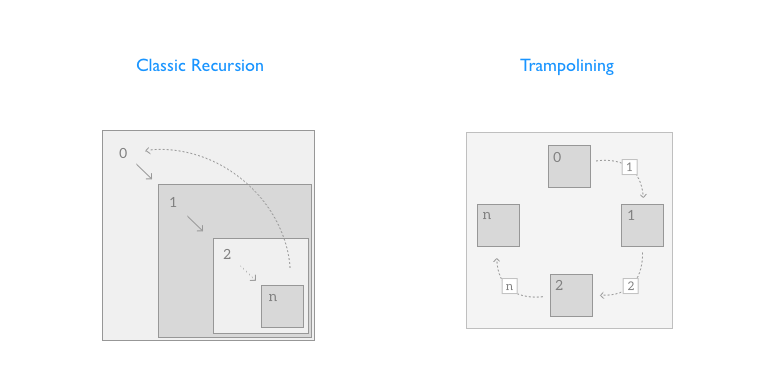
通过递归来实现算法往往比基于循环的实现来得更加清晰,但递归的实现会因为每次方法调用的时候都需要分配和管理栈帧而导致额外的开销,这会导致递归的实现很慢而且有可能很快就耗尽了栈空间(也就是栈溢出)。
为了避免栈溢出,一个推荐的做法是把程序重写成尾递归的形式来利用一些编译器的尾递归优化的功能来避免溢出。
但我们不仅会想,普通递归和尾递归的区别到底是什么?编译器的尾递归优化到底是做了怎样的事情?
尾递归和普通的递归不同之处在于,尾递归函数的返回值是简单的递归调用,没有任何额外的运算。实际运算的过程是通过一个累加器变量一路传递到后继的调用中,直到递归执行完毕。
上面的定义可能不太好懂,下一节会有一个例子来提供更清晰的解释。现在你唯一需要知道的就是,有一种特殊的递归可以被编译器优化成更高效的基于循环的实现,不会受到栈大小的影响。
但是在 Swift 里,我们不能指望编译器会在所有情况下都执行尾递归优化。
这个缺陷之前已经在 Natasha 的博客 被讨论过,现在已经有人为此做了一些工作并提交了一份提案。提案主要提出了添加一些属性来让优化器的行为更加可验证,并允许明确地指定哪些尾递归是可以被优化的(如果没有被优化,则应该抛出异常。)
这篇文章我们会讲解如何使用蹦床 (trampolines) 机制来解决 Swift 尾递归优化方面的不足,同时会给出一些递归的替代方案。
译者注:为什么叫做蹦床呢?是因为蹦床机制本质上就是把递归调用转化为循环调用。递归会先连续的压栈(递归调用),返回的时候再连续地出栈。而蹦床的话,每次执行调用压栈一次(函数调用),然后马上出栈(函数返回)。循环往复这个过程。如果把栈比作蹦床的话,这个过程就像在跳蹦床一样。落下就是压栈,弹起就是出栈。交替进行。
用递归计算三角数
让我们来看一个用递归的方式来计算第 n 个三角形数的算法:
func tri(n:Int)->Int{
if n <= 0 {
return 0
}
return n+tri(n-1)
}
tri(300) //45150
在这个简单的递归的例子中,递归调用的执行结果和参数相加就是结果。我们最初的 tri(300) 的结果就是对所有这样的数,通过递归链式地求和。
把上述代码改为尾递归的形式,我们添加一个累加器变量来把累加值传递到下一层调用。
func ttri(n:Int, acc:Int=0)->Int {
if n<1 {
return acc
}
return ttri(n-1,acc:acc+n)
}
ttri(300) //45150
注意上述算法中结果是如何通过累加器实现的,最后一步就是简单的返回累加值来完整整个计算过程。
但是当输入参数很大时,上面两个方案都会 crash。我们来看一下如何用蹦床算法来解决这个问题。
蹦床
蹦床背后的原理其实很简单。
蹦床形式的基本定义是循环的执行一个函数,这个函数要么返回的是一个用于下一次执行函数(以 thunk 或者“连续”的形式,具体说就是一个数据结构,其中包含用于某次方法调用所必须的信息), 要么返回的是一个其他类型的值(在这个例子中就是累加值)来标识迭代的结束。
如果我们要用蹦床来顺序的执行我们的尾递归函数,我们需要对其进行一些简单的修改,修改成连续传递的形式 (continuation-passing style).
更新
像 oisdk 所说,我们在下面修改后的函数只是有一点点像真正的 CPS(译注:也就是上面提到的连续传递形式)。
在这里,闭包可以让你通过模拟延迟计算 (Lazy Evaluation) 来实现一种伪尾递归优化。在连续传递形式中,你将“连续”以函数的额外参数的形式传到递归函数中,“连续”定义了函数主体执行完毕以后该做什么(译注:本质上来说,“连续”也是一个函数)。简单的说,先执行函数主体,然后执行“连续”的部分,通常在最开始,你传入的是一个元函数。这个机制可以让你把普通递归函数变换为尾递归函数。但显然,Swift 并不保证进行尾递归优化,所以其实这个机制也没什么用处。
先不管这些。下面是三角数计算的 CPS 形式:
func triCont(n: Int, cont: Int -> Int) -> Int {
return n <= 1 ? cont(1) : triCont(n-1) { r in cont(r+n) }
}
func id<A>(x: A) -> A { return x }
triCont(10, cont: id) // 55
感谢棒棒哒的解释。
和直接执行递归调用不同的是,我们的 ttri 函数将会返回一个封装了真实的调用的对象,并且一旦到达执行应该结束的点,我们会返回一个包含累加结果的哨兵值,来标识执行结束。
我们从定义一个 Result 枚举来表示我们修改后的递归函数可能返回的值:.Done 表示递归执行完毕,并且其中包含最后的累加值。.Call 会包含下一步要执行的方法的闭包。
enum Result<A>{
case Done(A)
case Call(()->Result<A>)
}
现在我们就可以来定义新的函数,包括一个修改版的 ttri 以及一些实现蹦床机制的代码。最后一个部分一般放在单独的函数中。但是在本例里把都放到一起,为了更加可读:
func tritr(n:Int)->Int {
func ttri(n:Int, acc:Int=0)->Result<Int> {
if n<1 {
return .Done(acc)
}
return .Call({
()->Result<Int> in
return ttri(n-1,acc: acc+n)
})
}
// Trampoline section
let acc = 0
var res = ttri(n,acc:acc)
while true {
switch res {
case let .Done(accu):
return accu
case let .Call(f):
res = f()
}
}
}
tritr(300)
仔细想一下上面的步骤,实现蹦床的部分也就不难理解了。
在初始调用 ttri 方法启动蹦床之后,.Call 枚举中包含的函数就被顺序的执行,累加值也在每一步中被更新:
return .Call({
()->Result<Int> in
return ttri(n-1,acc: acc+n)
})
虽然代码不一样了,但是行为仍然和我们最开始的递归版本是一样的。
一旦计算完成,ttri 函数就返回一个包含最终结果的 .Done 枚举。
虽然这个实现比最开始的版本要慢,因为所有代码都需要操作蹦床。但这个版本已经解决了栈溢出这个最大的问题,我们现在已经可以计算任意大小三角数了,直到超过整数的限制。
Update: @oisdk 建议说。ttri函数的实现可以通过一个快被遗忘的属性修饰符 @autoclosure 来简化。
func call<A>(@autoclosure(escaping) c: () -> Result<A>) -> Result<A> {
return .Call(c)
}
func ttri(n: Int, acc:Int=1) -> Result<Int> {
return n <= 1 ? .Done(acc) : call(tri(n-1, acc: acc+n))
}
在我们继续之前,再多说一点例子的问题。把代码包在 while true 中并不是一个好习惯,一个更好的循环检查应该是这样:
while case .Call(_) = res {
switch res {
case let .Done(accu):
return accu
case let .Call(f):
res = f()
}
}
if case let .Done(ac) = res {
return ac
}
return -1
当然还有更好的做法,因为我们用枚举来关联值,我们应该针对该枚举实现一个比较运算符并在循环的开头来检查是否完成。
现在,蹦床的基本原理已经解释了,我们现在可以构建一个通用的函数来实现:给定一个返回 .Result 枚举的函数,返回一个闭包来在蹦床中执行原始函数。用该函数可以将执行细节封装起来。
func withTrampoline<V,A>(f:(V,A)->Result<A>) -> ((V,A)->A){
return { (value:V,accumulator:A)->A in
var res = f(value,accumulator)
while true {
switch res {
case let .Done(accu):
return accu
case let .Call(f):
res = f()
}
}
}
}
在我们返回的闭包的主体基本上就是我们在之前例子中的蹦床部分,withTrampoline 函数接收一个类型为 (V,A)->Result<A> 函数作为参数。这个函数之前我们已经实现了。还有一点和之前的版本显著的不同的地方是,我们不能初始化泛型累加器 A 因为我们并不知道它具体的类型,所以我们将它暴露为我们返回的函数的参数,这里算一点小瑕疵。
下面就用一下我们刚才定义的通用函数:
var fin: (n:Int, a:Int) -> Result<Int> = {_,_ in .Done(0)}
fin = { (n:Int, a:Int) -> Result<Int> in
if n<1 {
return .Done(a)
}
return .Call({
()->Result<Int> in
return fin(n: n-1,a: a+n)
})
}
let f = withTrampoline(fin)
f(30,0)
这代码可能比你想象的要长一点。
因为我们在闭包内部需要使用当前的函数,所以我们必须在定义真正的闭包之前先定义一个该闭包类型的傀儡实现,来使得在闭包实现中对自身的引用合法化。
如果不用傀儡实现,而是直接声明 fin 闭包,会得到一个变量在它初始化过程中被使用的错误。 如果你喜欢冒险,可以尝试使用 Z 组合子 来替换这个丑陋的解决办法。
但是如果去掉传统的蹦床设计,我们可以简化 Result 枚举并且在蹦床内部来跟踪函数的执行,而不是把函数当做值存在枚举中:
enum Result2<V,A>{
case Done(A)
case Call(V, A)
}
func withTrampoline2<V,A>(f:(V,A)->Result2<V,A>) -> ((V,A)->A){
return { (value:V,accumulator:A)->A in
var res = f(value,accumulator)
while true {
switch res {
case let .Done(accu):
return accu
case let .Call(num, accu):
res = f(num,accu)
}
}
}
}
let f2 = withTrampoline2 { (n:Int, a:Int) -> Result2<Int, Int> in
if n<1 {
return .Done(a)
}
return .Call(n-1,a+n)
}
f2(30,0)
这样看起来更清晰,更紧凑。
Swift 中递归的替代方案
如果你有阅读过一些关于 Swift 函数式编程的文章的话那你应该知道 Swift 提供了一些有用的特性来替代递归来解决一些一般会使用递归来解决的问题。
比如,三角形数可以通过一行简单的函数式代码计算出来,使用 reduce:
(1...30).reduce(0,combine:+) //465
或者我们可以创建一个 Sequence 或 Generator 来生成所有可能的三角形数的序列:
class TriangularSequence :SequenceType {
func generate() -> AnyGenerator<Int> {
var i = 0
var acc = 0
return AnyGenerator(body:{
print("# Returning "+String(i))
i=i+1
acc = acc + i
return acc
})
}
}
var fs = TriangularSequence().generate()
for i in 1...30 {
print(fs.next())
}
以上就是我们可以用 Swift 实现的两种可能的替代方案。
结束语
这篇文章描述了 Swift 中递归处理的一些限制以及在 Swift 中如何实现蹦床(在缺乏尾递归优化的语言中一种常规的优化机制)。但是我提倡在代码中使用蹦床了吗?
绝壁没有。
在 Swift 中,考虑到它并不是纯函数式的语言,一般能够被复杂的蹦床解决的问题,我们总是可以通过一些语言特性以一个更好的方式去解决(代码更加可读,行为更加可理解)。不要对代码做过度的设计,未来的你会感谢你自己的。
再次感谢 @oisdk 极富洞察力的评论。
可以在 Twitter 上关注我。
本文由 SwiftGG 翻译组翻译,已经获得作者翻译授权,最新文章请访问 http://swift.gg。


