集成科大讯飞语音功能之语音听写
2017-04-04 本文已影响606人
lzyup
集成科大讯飞语音功能
标签: Android Speech
1.简介##
这次集成科大讯飞的语音功能主要是下面这三个方面:
- 语音听写,语音听写主要指将连续语音快速识别为文字的过程,科大讯飞语音听写识别通常常见的语句、词汇,而且不限制说法。
- 语音识别,只要指基于命令词的识别,识别指定关键词组合的词汇,或者固定说法的短句。语法识别分云端识别和本地识别,云端识别和本地识别分别采用ABNF和BNF语法格式。
- 语义理解,这里我讲的是语义提取部分就是能理解你说的话,帮你提出你要的信息,需要先设置具体场景,比如查天气,这里我设置的场景是查航班。
2.语音听写的集成与实现##
- 毫无疑问, 第一步当然是申请Appid了,下载相应的SDK了。点击这里申请,这里我要说的是,申请的Appid和对应下载的SDK具有一致性,请确保在使用过程中规范导入。一个Appid对应一个平台下的应用,如在多个平台开发同款应用,还需申请对应平台的Appid。而且开发集成阶段的服务量为500次/日,如果你要解除这个限制,开发者需要提交应用上线审核,审核通过后将不再有服务次数的限制。
- 申请好了Appid(几乎是秒申请),接下就是下载好相应的SDK,下载好SDK后将相应的jar包和.so放到对应的项目文件夹下,.so文件放在armeabi目录下
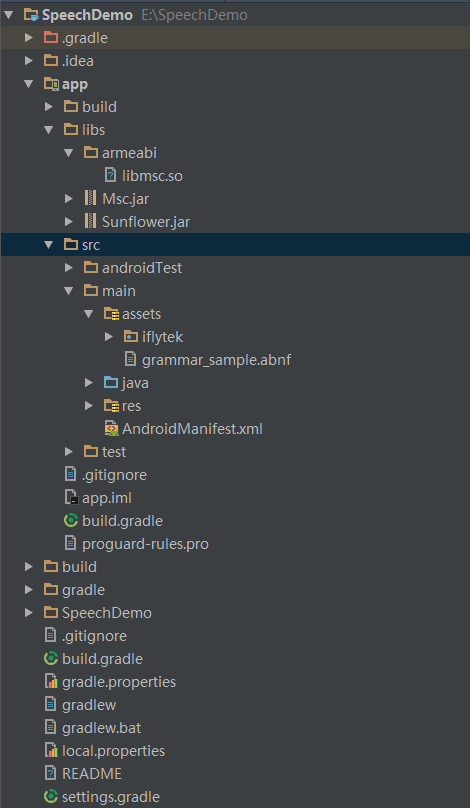 如图所示添加到相应的目录
如图所示添加到相应的目录
别以为添加就完事了,一定注意要引用!!!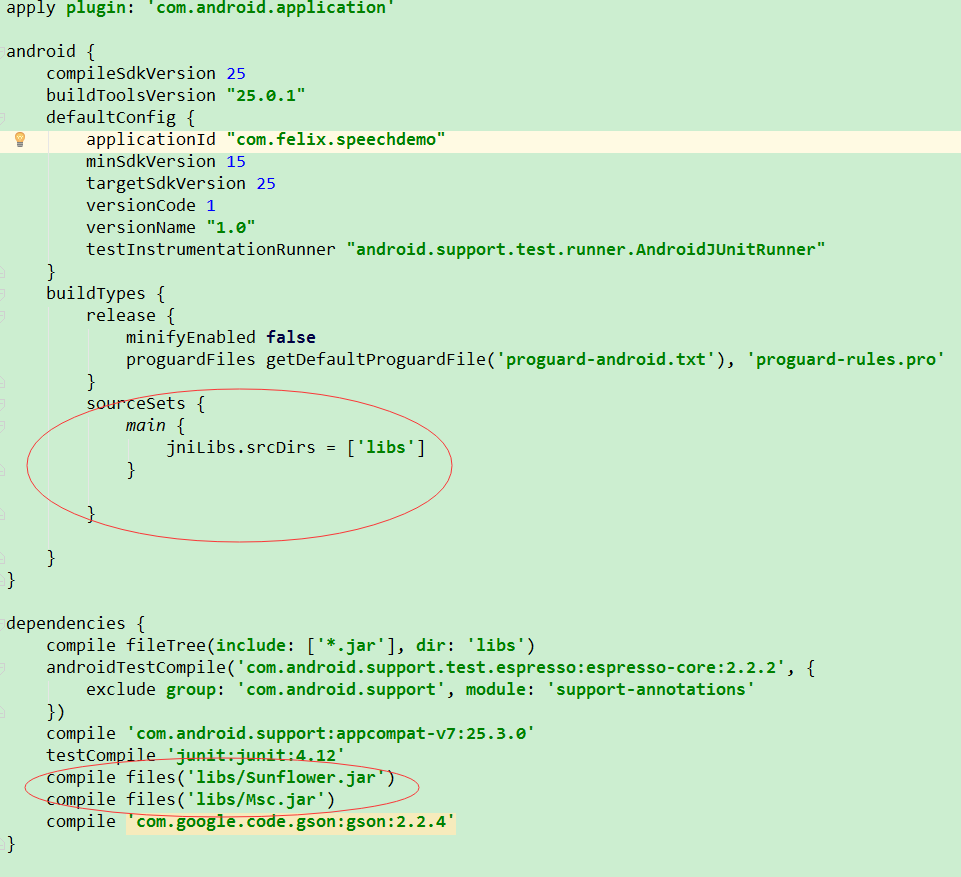 如图所示进行引用
如图所示进行引用
- 另外记得添加相关权限
<!--连接网络权限,用于执行云端语音能力 -->
<uses-permission android:name="android.permission.INTERNET"/>
<!--获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 -->
<uses-permission android:name="android.permission.RECORD_AUDIO"/>
<!--读取网络信息状态 -->
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/>
<!--获取当前wifi状态 -->
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/>
<!--允许程序改变网络连接状态 -->
<uses-permission android:name="android.permission.CHANGE_NETWORK_STATE"/>
<!--读取手机信息权限 -->
<uses-permission android:name="android.permission.READ_PHONE_STATE"/>
<!--读取联系人权限,上传联系人需要用到此权限 -->
<uses-permission android:name="android.permission.READ_CONTACTS"/>
<!--外存储写权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
<!--外存储读权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
<!--配置权限,用来记录应用配置信息 -->
<uses-permission android:name="android.permission.WRITE_SETTINGS"/>
<uses-permission android:name="android.permission.WRITE_SETTINGS" />
<!-- 在SDCard中创建与删除文件权限 -->
<uses-permission android:name="android.permission.MOUNT_UNMOUNT_FILESYSTEMS"></uses-permission>
<!-- SD卡权限 -->
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"></uses-permission>
<!-- 允许程序读取或写入系统设置 -->
<uses-permission android:name="android.permission.WRITE_SETTINGS"></uses-permission>
- 接下来我讲讲语音听写的关键对象了,SpeechRecognizer对象,这个其实是用来做语音识别,但是也可以做语音听写,还有一个是RecognizerDialog对象,这个准确的说是语音听写的UI,就是说当我们说话的时候可以提供交互的的动画,这个是科大讯飞为我们做的动画,要是要用的话需要将下载的SDK目录下的assets下的iflytek文件放到自己的项目的资源目录下,如果你只需要听写而且需要这个交互动画的话,那么你可以只需要用到RecognizeDialog对象就行了。当然如果你要自定义这个交互动画的话,要用到SpeechRecognize对象,我这里是主要讲SpeechRecognizer对象,具体的这两个对象我最后提供的Demo里面都有用到。下面直接上代码。
-
private SpeechRecognizer mIat;//SpeechRecognizer对象
SpeechUtility.createUtility(this, SpeechConstant.APPID + "=58d9cd0a");//初始化
mIat = SpeechRecognizer.createRecognizer(this, mInitListener); - 初始化监听器
/**
* 初始化监听器
*/
private InitListener mInitListener = new InitListener() {
@Override
public void onInit(int code) {
Log.d(TAG, "SpeechRecognizer init() code = " + code);
if (code != ErrorCode.SUCCESS) {
showTip("初始化失败,错误码:" + code);
}
}
};
- 设置参数
public void setParam() {
// 清空参数
mIat.setParameter(SpeechConstant.PARAMS, null);
// 设置听写引擎
mIat.setParameter(SpeechConstant.ENGINE_TYPE, mEngineType);
// 设置返回结果格式
mIat.setParameter(SpeechConstant.RESULT_TYPE, "json");
String lag = mSharedPreferences.getString("iat_language_preference",
"mandarin");//普通话
if (lag.equals("en_us")) {
// 设置语言
mIat.setParameter(SpeechConstant.LANGUAGE, "en_us");//美式英文
} else {
// 设置语言
mIat.setParameter(SpeechConstant.LANGUAGE, "zh_cn");//简体中文
// 设置语言区域
mIat.setParameter(SpeechConstant.ACCENT, lag);
}
// 设置语音前端点:静音超时时间,即用户多长时间不说话则当做超时处理
mIat.setParameter(SpeechConstant.VAD_BOS, mSharedPreferences.getString("iat_vadbos_preference", "4000"));
// 设置语音后端点:后端点静音检测时间,即用户停止说话多长时间内即认为不再输入, 自动停止录音
mIat.setParameter(SpeechConstant.VAD_EOS, mSharedPreferences.getString("iat_vadeos_preference", "1000"));
// 设置标点符号,设置为"0"返回结果无标点,设置为"1"返回结果有标点
mIat.setParameter(SpeechConstant.ASR_PTT, mSharedPreferences.getString("iat_punc_preference", "1"));
// 设置音频保存路径,保存音频格式支持pcm、wav,设置路径为sd卡请注意WRITE_EXTERNAL_STORAGE权限
// 注:AUDIO_FORMAT参数语记需要更新版本才能生效
mIat.setParameter(SpeechConstant.AUDIO_FORMAT, "wav");
mIat.setParameter(SpeechConstant.ASR_AUDIO_PATH, Environment.getExternalStorageDirectory() + "/msc/iat.wav");
}
- 开始监听
ret=mIat.startListening(mRecognizerListener)
- 听写监听器
/**
* 听写监听器。
*/
private RecognizerListener mRecognizerListener = new RecognizerListener() {
@Override
public void onBeginOfSpeech() {
// 此回调表示:sdk内部录音机已经准备好了,用户可以开始语音输入
showTip("开始说话");
//mRecognitionProgressView.play();
}
@Override
public void onError(SpeechError error) {
// Tips:
// 错误码:10118(您没有说话),可能是录音机权限被禁,需要提示用户打开应用的录音权限。
// 如果使用本地功能(语记)需要提示用户开启语记的录音权限。
showTip(error.getPlainDescription(true));
}
@Override
public void onEndOfSpeech() {
// 此回调表示:检测到了语音的尾端点,已经进入识别过程,不再接受语音输入
showTip("结束说话");
}
@Override
public void onResult(RecognizerResult results, boolean isLast) {
Log.d(TAG, results.getResultString());
printResult(results, mContent);
Log.d(TAG, results.getResultString());
if (isLast) {
// TODO 最后的结果
}
}
@Override
public void onVolumeChanged(int volume, byte[] data) {
showTip("当前正在说话,音量大小:" + volume);
Log.d(TAG, "返回音频数据:" + data.length);
// mRecognitionProgressView.onRmsChanged(volume);
}
@Override
public void onEvent(int eventType, int arg1, int arg2, Bundle obj) {
// 以下代码用于获取与云端的会话id,当业务出错时将会话id提供给技术支持人员,可用于查询会话日志,定位出错原因
// 若使用本地能力,会话id为null
// if (SpeechEvent.EVENT_SESSION_ID == eventType) {
// String sid = obj.getString(SpeechEvent.KEY_EVENT_SESSION_ID);
// Log.d(TAG, "session id =" + sid);
// }
}
};
- 在上面的OnResult()回调方法中对数据进行解析,解析得方法如下:
/**
* 显示结果,并赋值到EditText文本框中
*
* @param results
* @param editText
*/
private void printResult(RecognizerResult results, EditText editText) {
String text = JsonParser.parseIatResult(results.getResultString());
String sn = null;
// 读取json结果中的sn字段
try {
JSONObject resultJson = new JSONObject(results.getResultString());
sn = resultJson.optString("sn");
} catch (JSONException e) {
e.printStackTrace();
}
mIatResults.put(sn, text);
StringBuffer resultBuffer = new StringBuffer();
for (String key : mIatResults.keySet()) {
resultBuffer.append(mIatResults.get(key));
}
String content = resultBuffer.toString();
Log.d(TAG, content);
content = content.replace("。", "".trim()); //去掉最后面的 。
editText.setText(content);
editText.setSelection(content.length());
}
- 以上就是关于语音听写的集成与实现,语音识别和语义理解将在下篇进行讲解。源码在这里--源码传送门--需要强调的是这个Demo中包含了语音听写和语义理解,可能你会问了,为什么不将语音识不也写在一起,我想说,开始我也天真的以为是一个SDK,后来发现语音识别跟语音听写是两个SDK,而语义理解当你申请Appid时,科大讯飞就为你开放了,你只要直接下载语音听写的SDK,同时到产品服务中开放语义中开通语义服务并选择需要的场景即可。需要解释的是,这个Demo里面我其实是已经写了语音识别的,只是我没有集成语音识别的SDK所以就没有写在一个Demo里面了,简单的介绍一下Demo里面的关键类,ArsBasicActivity是语音识别的基类,IatBasicAcitvity是语音听写的基类,IatActivity是语音听写的实现,继承其基类。如果你想在一个Demo中还实现语音识别功能,只需要导入语音识别的SDK,然后模仿着IatActivity写一个ArsActivity相信聪明的你一定可以的。另外MainActivity是语义理解,我设置的航班的场景,而且用了自定义的交互动画,你也可以很方便的将这个自定义动画移植到语音听写和语音识别上,你可以参考,当然接下来我也会把我写的关于语音识别和语义理解部分的内容分享出来。


