svm简介
2013-10-06 本文已影响0人
一眼的笑意
1、 概念
svm(Support Vector Machine,支持向量机)是一种线性分类器,于1995年由Cortes和Vapnik提出,目前已经应用在手写体识别以及文本分类等领域。
svm建立在统计学习理论中的VC维理论和结构风险最小化的基础之上,在模型的复杂度和学习能力之间寻求最佳折衷,以期获得最好的推广能力,所得到的分类器一般是全局最优的。
2、特点
- 输入样本后将分类器的结果与1/-1比较,大于1或小于-1可确定类属,介于两者之间则不予分类
- 通过最大化几何间隔来训练分类器,只有支持向量会参数模型训练
- 对于线性不可分的样本通过映射到高维空间来实现线性可分,这个映射关系不好确定,核函数则很巧妙的解决了这个问题,也正是因为核函数的引入,svm有效的克服了维度之咒
The kernel trick is a method for computing similarity in the transformed space using the original attribute set.
为了克服少量离群点的干扰可在模型中加入松弛变量和惩罚因子,对于分布不均的样本,可通过惩罚因子来进行调节。每个样本都有一个松弛变量而惩罚因子则是固定的,需要由用户输入(核函数的参数也需要用户输入,这里就涉及一个参数寻优的问题(网格暴力法、粒子群、启发式))。
- SVM中的多分类的问题可通过DAG SVM来解决
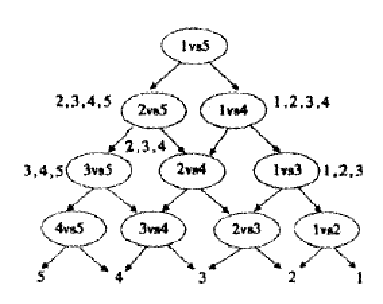 DAG SVM
DAG SVM
这样在分类时,我们就可以先问分类器“1对5”(意思是它能够回答“是第1类还是第5类”),如果它回答5,我们就往左走,再问“2对5”这个分类器,如果它还说是“5”,我们就继续往左走,这样一直问下去,就可以得到分类结果。好处在哪?我们其实只调用了4个分类器(如果类别数是k,则只调用k-1个),分类速度飞快,且没有分类重叠和不可分类现象
- 时间复杂度
最坏的是O(Nsv^3),这个还是挺高的


