Pandas QQ聊天记录分析
2016-07-05 本文已影响914人
心智万花筒
挖掘QQ聊天记录
主要联系pandas的基本操作
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.style.use('ggplot')
%matplotlib inline
/usr/local/lib/python2.7/site-packages/matplotlib/font_manager.py:273: UserWarning: Matplotlib is building the font cache using fc-list. This may take a moment.
warnings.warn('Matplotlib is building the font cache using fc-list. This may take a moment.')
# 数据初探
!head -n 4 qqdata.csv
id,time
8cha0,2011/7/8 12:11:13
2cha061,2011/7/8 12:11:49
6cha437,2011/7/8 12:13:36
!wc -l qqdata.csv #数据很小,才一万多行,直接读
11563 qqdata.csv
解析时间
直接读取的时间列是str类型,如果解析成时间类型,分析更方便。
# 默认的parse_dates = True不能有效地解析
# http://stackoverflow.com/questions/17465045/can-pandas-automatically-recognize-dates
dateparse = lambda x: pd.datetime.strptime(x, '%Y/%m/%d %H:%M:%S')
qq = pd.read_csv('qqdata.csv', parse_dates=['time'], date_parser=dateparse)
qq['time'][0] # 时间戳类型,而不是str
Timestamp('2011-07-08 12:11:13')
qq.head(3)
| id | time | |
|---|---|---|
| 0 | 8cha0 | 2011-07-08 12:11:13 |
| 1 | 2cha061 | 2011-07-08 12:11:49 |
| 2 | 6cha437 | 2011-07-08 12:13:36 |
基本信息获取
群聊人数
len(qq['id'].unique()) #群人数144人
144
时间戳是否唯一?有重复,暂时先不把其设为index
time = qq['time']
len(time) == len(time.unique())
False
找话唠
把话唠定义为发言次数最多的人
qq['count'] = 1 #添加一列
# 因为qq['count']设置为1,所以count()也可以替换为sum()
gp_by_id = qq['count'].groupby(qq['id']).count().sort_values(ascending=False)
type(gp_by_id) #返回一个Series
pandas.core.series.Series
gp_by_id[:5]
id
7cha1 1511
6cha437 1238
4cha387 1100
8cha08 695
4cha69 533
dtype: int64
plt.figure(figsize=(6,4))
ax = gp_by_id[:10].plot.bar()
ax.set_xticklabels(gp_by_id.index,rotation='45')
ax.set_xlabel('');
发现一个很怪的id: )chailed (104: Connection reset by pee,确认一下是不是在.
(qq['id'] == ')chailed (104: Connection reset by pee').any()
True
而且万年潜水党,只说过一句话,名字还这么难记,内个群主,踢人了可以。
gp_by_id.ix[')chailed (104: Connection reset by pee']
1
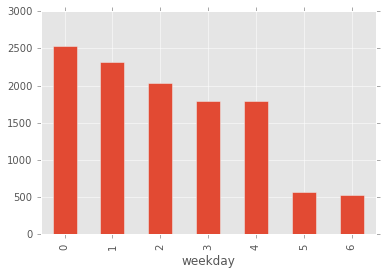
聊天密度周分布
看看大家聊天主要集中在周几
# 添加一列 weekday, derived from time
qq['weekday'] = qq['time'].map(lambda x : x.weekday())
gp_by_weekday = qq['count'].groupby(qq['weekday']).count()
gp_by_weekday.plot.bar(); # 不好好上班,平时话真多
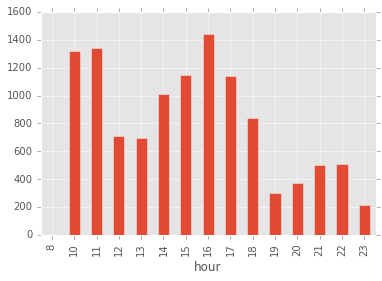
聊天密度小时分布
# 添加一列 hour, derived from time
qq['hour'] = qq['time'].map(lambda x : x.hour)
gp_by_hour = qq['count'].groupby(qq['hour']).count()
gp_by_hour.plot.bar();
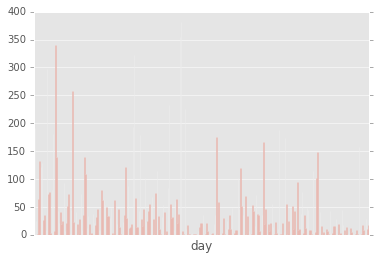
聊天密度历史分布
# 添加一列 day, derived from time
qq['day'] = qq['time'].map(lambda x : x.date())
gp_by_day = qq['count'].groupby(qq['day']).count()
ax = gp_by_day.plot.bar();
ax.set_xticks([])
ax.set_xticklabels([]);
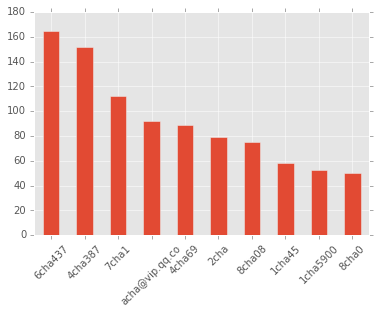
活跃天数最多的用户?
如果某天说话了,则定义为这一天活跃。
# qq.groupby('id') group by id
# .day we only interest in active day now
# .nunique() the number of unique active day
# 等价于 apply(lambda x: len(x.unique()))
gp_by_act_day = qq.groupby('id').day.nunique().sort_values(ascending=False)
plt.figure(figsize=(6,4))
ax = gp_by_act_day[:10].plot.bar()
ax.set_xticklabels(gp_by_act_day.index,rotation='45')
ax.set_xlabel('');
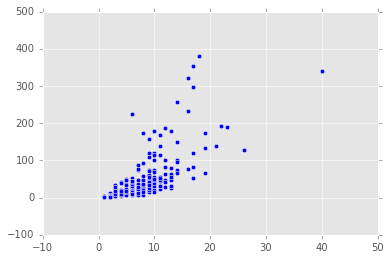
活跃用户数与发言量的关系
观察是否发言人数多,相应的发言量也增加了
# 活跃用户数
people = qq['id'].groupby(qq['day']).nunique()
# 发言量
speech = qq['count'].groupby(qq['day']).count()
# 可以看出正相关
plt.figure(figsize=(6,4))
ax = plt.scatter(people,speech)