SQL Server_查询整理
基于 SQL Server的查询整理!
SQL 逻辑流
Select 语法
- Select语句的From部分将所有数据源组装进一个结果集,然后由Select语句的剩余部分对结果集执行操作。
- Where子句作用于From组装的记录集,根据条件筛选某些行。
- 聚合函数对数据集执行求和操作。
- Group by 子句根据在该子句中指定的列将大量数据集分组成较小的数据集。
- Having 对较小的数据组执行聚合函数。
- Order by 子句确定结果子的排列顺序。默认为升序;
Select [Distinct] [Top(n)] *, columns, or expressions
[From data source(s)]
[Join data source
ON condition] (may include multiple joins)
[Where conditions]
[Group by columns]
[Having conditions]
[Order by columns];
查询语句的逻辑流
数据源(From) —— 条件(Where) —— 列/表达式 (col/exp) —— Order by — 谓词
-
From,查询首先组装初始数据集。
-
Where,筛选;筛选过程实际上是选择符合标准的行的where子句。
-
Group by,组合数据的子集
-
聚合,Aggregations,选择性地对数据进行聚合;如求平均值,按列中的值对数据分组以及筛选组;
-
Having,筛选数据的子集
-
列表达式:处理Select列,并计算任何表达式 [ 这个时候才涉及到列 ]
-
Order by,排序
-
Over,窗口函数和排名函数通过与其他聚合函数一起提供结果的单独排序的视图
-
Distinct,从结果集中删除任何重复的行
-
Top,选定行后,执行计算,并按所需的顺序排序
-
Insert,Update,Delete,最后一个逻辑步骤是将数据修改操作应用到查询结果。
-
Output,选择插入和删除的虚拟表,并返回给客户端
-
Union,堆叠或合并多个查询的结果
SQL编写语句标准
- 若出现多个主条件,先将主条件的区分变量统一到一个表中
-
其他表与这个表进行联接
- 先把各个字段单独用Select写出来
- 再合并为一个Select语句
运算符介绍
优先级
Not > 算术运算符(+-) > 条件运算符(where) > And > Or
电脑中字符优先级: 数字>字母
1a > a1 > a11 > aa1
通配符
| 运算符 | 含义 | 示例 |
|---|---|---|
| % | 任意长度的字符串 | Email Like ‘%@%.com’ |
| ‘_’ | 任意一个字符 | AuthorName Like ‘张_’ |
| [ ] | 在指定范围内的任意一个字符 | A Like ‘A6C8[1-5]’ |
| [^] | 不在指定范围内的任意一个字符 | A Like ‘A6C8[^1-6]’ |
查找含通配符的表达式:
- 必须使用Like字符
- 把通配符放入方括号[ ] 内
- 在其之前放一个转义符
注意事项与通用规则
方括号 [ ]
- why :表名或字段名如果引用了sql server中的关键字,数据库会不识别这到底是关键字还是表名(还是字段名)时就必须要加;
- 查询语句的表中加上方括号[ ] , 目的是以声明其不是保留字 ;
- 如果表名不是关键字,不用加方括号
# 一个表名叫user,user在sqlserver中属于关键字,那么查询的时候必须要这样
select * from [user] ;
# 若表名user中没有user的列,则无需加方括号
select * from user ;
合并:字段+表格
# 字段合并 +
SELECT 机构+客户名称 FROM allzjb where 结算日期>'2015-11-15'
SELECT RTRIM(LastName) + ',' + SPACE(2) + LTRIM(FirstName) FROM Person.Person
--剪裁姓氏,并将逗号、两个空格和 Person 中的 AdventureWorks2012 表列出的人员名字串联起来
使用“ + ”连接多个字段,合并成一列
- 前后类型应兼容;
如果+连接数值类型,结果是数值之和
如果+连接字符串类型,结果是字符串的连接
# 表格合并 - insert into A1 select ...
INSERT INTO table2 SELECT * FROM table1; -- 把table1的数值插入到table2中
# 只插入某一列的值
INSERT INTO table2 (column_name)
SELECT column_name FROM table1 ;
# 合并为一个字符串 - concat()
Select Concat(Null, 'Patrick ', 1, ' LeBlacn')
--隐式地将所有值转换为字符串,将空值转为空字符串
Where条件
- 最佳实践:找到事物的最好办法就是查找,而不是先排除不是该事物的所有东西。即where条件,声明肯定的限制条件优于否定的限制条件;
where col >= 10 ; 优于 where col !< 9
惊叹号! ,不是ANSI标准的SQL;
- 布尔逻辑运算的优先次序: NOT > AND > OR
Where name Like 'Chain%' or ProductID Between 320 And 324
And name Like '%s%'
--1. 先执行And,即找出name中 带有 s 的名字;
--2. 再在其中寻找 name中有Chain 或者 ProduceID在[320,324]
------------------
Where (name Like 'Chain%' or ProductID Between 320 And 324 )
And name Like '%s%'
--1. 先执行括号,即先找出name中有Chain 或者 ProduceID在[320,324]
--2. 再在其中找出name中 带有 s 的名字;
Between and
# 使用带有日期时间值的 BETWEEN
WHERE RateChangeDate BETWEEN '2001-12-12' AND '2002-01-05';
----下面的示例检索所在的行【datetime值】可以介于'20011212'和'20020105'(含) 之间;因为在查询中的日期值和datetime值存储在RateChangeDate而无需在日期的时间部分中指定了列。
-- 下面是结果集:
BusinessEntityID RateChangeDate
----------- -----------------------
3 2001-12-12 00:00:00.000
4 2002-01-05 00:00:00.000
----未指定时间部分时,将默认使用 12:00 A.M。
--请注意,若某行的时间部分晚于 2002-01-05 12:00 A.M., 则由于它处于范围之外,因此此查询不返回该行。
ALL、SOME、ANY
- ALL,相当于And;如果子查询可能返回一个空值,那么使用ALL会判断为fasle,使用时要小心;
循环
- while,break,continue的使用
--首先计算所有数的平均价格,如果低于30的话进入循环让所有的price翻倍,
--里面又有个if来判断如果最大的单价还大于50的话,退出循环,否则继续循环,知道最大单价大于50就break出循环,呵呵,
--我分析的应该对吧.
use pubs
go
while (select avg(price) from titles) <$30
begin
update titles
set price=price*2
select max(price) from titles
if(select max(price) from titles) >$50
break
else
continue
end
print 'too much for the marker to bear'
插入、更新、删除、合并数据
插入数据
# 插入简单的值行
Insert [Into] schema.table [ (colums, ...) ]
Values (value,...),
(value,...);
# 在标识列中插入数据,要使用Set Identity_insert on / off关键字
Set Identity_insert dbo.address On
Insert Into dbo.address (AddreddID, Addressl, city, state, county)
Valuse(999, )
Set Identity_insert dbo.address Off
------------------------------------------------------------------------------------
# 从Select语句中插入结果集
Insert [Into] schema.table [ (colums,...)]
Select columns From data [Where conditions];
--1. schema.table 必须存在
--2. into schema.table中的列必须与之后Select中的列相同
--3. 若schema.table中有5列,只选取其中3列插入,则其他2列的观测值对NULL
------------------------------------------------------------------------------------
# 从存储过程插入结果集
Insert [Into] schema.table [ (colums,...)]
Execute storedprocedure;
--
# 在插入数据时创建表
Select colums
Into newtable From data [where conditions];
SQL中合并列,只要选择对应的列即可
Select a.*, b.* From a Full Join b
更新数据
# 更新单个表
Update schema.table
Set column = expression,
column = value
[From data]
[Where conditions];
----------------------------------------------------------------------------------
# 执行全局搜索与替代
# replace(data, 'aaa', 'bbb')
Update address
Set county = Replace(county, 'sun', 'dark') -- 将county列中所有的sun替换为dark
Where county Like '%shine' ;
删除数据
# delete
Delete [From] schema.table
/*[From data] SQL Server 特有的T-SQL扩展,用来进行联接;正常情况下应在where子句中创建子查询*/
[Where conditions];
# 删除所有行
Delete From schema.table
--不删除表的情况下删除所有的行。这意味着表的结构、属性和索引都是完整的:
---------------------------------------------------------------------------------
# 删除表中所有行 - truncate
Truncate Table dbo.address
---------------------------------------------------------------------------------
# 删除整个表
Drop table schema.table
truncate 、delete与drop区别
- 相同点
- truncate和不带where子句的delete、以及drop都会删除表内的数据drop、truncate都是DDL语句(数据定义语言),执行后会自动提交。Delete是DML语句(数据库操作语言)
- 不同点
-
truncate 和 delete 只删除数据不删除表的结构(定义);drop 语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index);依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。
-
delete 语句是数据库操作语言(dml),这个操作会放到 rollback segement 中,事务提交之后才生效;如果有相应的 trigger,执行的时候将被触发。truncate、drop 是数据库定义语言(ddl),操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。
-
delete 语句不影响表所占用的 extent,高水线(high watermark)保持原位置不动。drop 语句将表所占用的空间全部释放。truncate 语句缺省情况下见空间释放到 minextents个 extent,除非使用reuse storage;truncate 会将高水线复位(回到最开始)。
-
速度:drop> truncate > delete
- TRUNCATE TABLE在功能上与不带WHERE子句的DELETE语句相同:二者均删除表中的全部行。但TRUNCATE TABLE 比DELETE速度快,且使用的系统和事务日志资源少。DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
-
安全性:
- 想保留表而将所有数据删除,如果和事务无关,用truncate即可。如果和事务有关,或者想触发trigger,还是用delete。
- 小心使用 drop 和 truncate,尤其没有备份的时候
- 使用上,想删除部分数据行用 delete,注意带上where子句. 回滚段要足够大
- 想删除表,当然用 drop
-
对于由FOREIGN KEY 约束引用的表,不能使用TRUNCATE TABLE,而应使用不带WHER 子句的DELETE语句。由于 TRUNCATE TABLE不记录在日志中,所以它不能激活触发器。
-
TRUNCATE TABLE不能用于参与了索引视图的表。
合并数据
- Meger语句。使用 MERGE 语句在一条语句中执行插入、更新或删除操作。
-
有条件地在目标表中插入或更新行。
- 如果目标表中存在相应行,则更新一个或多个列;否则,会将数据插入新行。
- 同步两个表。根据与源数据的差别在目标表中插入、更新或删除行。
-
有条件地在目标表中插入或更新行。
Meger flightpassengers As f -- MERGE 子句用于指定作为插入、更新或删除操作目标的表或视图
Using checkin as c --USING 子句用于指定要与目标联接的数据源
On c.lastname = f.lastname --ON 子句用于指定决定目标与源的匹配位置的联接条件
And c.firstname = f.firstname
And c.flightcode = f.flightcode
And c.flightdate = f.flightdate
When Matched
Then Update Set f.seat = c.seat
When Not Matched By Target --当Soucre表与Target表(基准表)不匹配时,对Target表进行操作
Then Insert (Firsrname, Lastname, Flightcode, flightdate, seat)
When Not Matched By Source --当Target表与Soucre表(基准表)不匹配时,对Target表进行操作【相同】
Then Delete;
--WHEN 子句(WHEN MATCHED、WHEN NOT MATCHED BY TARGET 和 WHEN NOT MATCHED BY SOURCE)基于 ON 子句的结果和在 WHEN 子句中指定的任何其他搜索条件指定所要采取的操作。
--OUTPUT 子句针对插入、更新或删除的目标中的每一行返回一行。
--必须由分号进行终止
--必须是一对一匹配;一对多匹配是不允许的
--联接条件必须是确定性的,也就是可重复的
返回修改后的数据
- Output子句可以访问插入的和删除的虚拟表,以及任何在From自引用的数据源来选择要返回的数据。
Output子句有一个较为高级的应用,可以把输出数据传输到外查询。
# 从插入返回数据
Insert Into personlist
Output Inserted.* -- Inserted.
Valuse(7777, 'Jane', 'Doe');
# 从更新返回数据 -- 可同时返回更新前、更新后的数据
Update personlist
Set firstname = 'Jane', Lastname = "Doe"
Output Deleted.firstname oldfirstname, Deleted.lastname oldflastname, --Deleted.column oldcolumn
Inserted.firstname newfirstname, Inserted.lastname newlastname
Where businessentityID = 7777
# 从删除返回数据
Delete From personlist
Output Deleted.*
Where ...
# 从合并返回数据
...
Output deleted.column, deleted.column,
$action, -- 显示数据库操作的行为(为Insert、Delete、Update)
inserted.column, inserted.column ;
# 把数据库返回到表中
Declare @Deletedperson Table(
businessentityID Int Not Null Primary Key,
lastname Varchar(50) Not Null,
firstname Varchar(50) Not Null
)
Delete dbo.personlist
Output Deleted.colunm, Deleted.column
Into @Deletedperson
Where bussinessentityID = 2;
1. 查询:字符串
| 函数名 | 功能描述 | 举例 |
|---|---|---|
| LEN | 返回指定字符串的字符个数(而不是字节),其中不包含尾随空格 | SELECT LEN('李丽然作者') 返回:5 |
| DATALENGTH | 返回指定字符串的字节数 | SELECT DATALENGTH('中国人') 返回:6 |
| UPPER | 将小写字符转换成大写字符 | SELECT UPPER('book图书表') 返回:BOOK图书表 |
| LTRIM | 返回去掉左侧空格的字符串 | SELECT LTRIM(' Authors') 返回: Authors |
| CHARINDEX | 查找一个指定的字符串在另一个字符串中的起始位置 | SELECT CHARINDEX('L', 'HELLO', 1) 返回:3 |
| LEFT | 返回字符串中从左边开指定个数的字符 | SELECT LEFT('zhangsan', 2) 返回:zh |
| Substring | 返回字符串的一部分:从字符串串的起始位置连续取指定个数的子串 | SELECT SUBSTRING('我爱我的家乡',3, 2) 返回:我的 |
| Replace | 替换一个字符串中的字符 | SELECT REPLACE('我爱我的家乡家乡', '家乡', '学校') 返回: 我爱我的学校学校 |
| Stuff | 将一个字符中删除指定数量的字符,并插入另一个字符 | |
| Concat | 将多个字符串组合为单个字符串 |
使用字符串字面量时,通过输入两个单引号转化为一个单引号
Replace(name, '''', '') ; Life''s Great! 被解释为 Life's Great!
行数&字符数
# 返回观测值的行数 - count [非空值的个数]
SELECT COUNT(name) FROM my_contacts;
# 返回字符串的字符个数 - len
SELECT LEN('中国人') ; # 返回:3
# 返回字符串的字节数 - datalength
SELECT DATALENGTH('中国人'); # 返回:6
去空格
# 去空格 - ltrim / rtrim
select ltrim(rtrim(' "左右都没有空格" ')); # 左右去空格
# 生成空格 - space
select space(2); # 生成2个空格
SELECT RTRIM(LastName) + ',' + SPACE(2) + LTRIM(FirstName) FROM Person.Person
# 剪裁姓氏,并将逗号、两个空格和 Person 中的 AdventureWorks2012 表列出的人员名字串联起来
取子串
# 取子串:特定位置 - substring
select substring(name,1,2); # 返回na;
# 取子串:左/右 - left /right
select left(ltrim( name), 3); # 返回nam;
返回特定位置
# 返回位置:起始位置 - charindex
select charindex('L', 'HELLO', 1); # 返回:3; 1表示第一次出现
--charindex(serach string, string ,starting position) ;第三个参数默认为1,可不写
# 返回位置:表达式中某模式第一次出现的起始位置 - patindex
patindex('%123%','abc123def'); # 返回4
--允许通配符的使用
替换
# 替换 - replace
select replace('abcdef','cde','xxx'); 返回 abxxxf
Select replace(colname, 'aaa', 'bbb'); --colname列中每个单元格的aaa值替换为bbb值,并返回colname列
# 删除&替换 - stuff()
Select stuff('abcdef', 3, 2, '123') -- 返回ab123ef;从第三个位置开始删除2个字符,并插入123
--stuff(string, insertion position, delete count, string inserted);
合并
# 合并为一个字符串 - concat()
Select Concat(Null, 'Patrick ', 1, ' LeBlacn')
--隐式地将所有值转换为字符串,将空值转为空字符串
格式转换
# 转换:大小写 - upper/lower
select upper('abc'); # 返回 ABC
# 转换:反转 - reverse
select reverse('abc'); # 返回'cba'
# 转换:字符形式 - char
select char(213);
# 转换:字符串形式 - str
select str(123.45, 6,1); # 把数值转换成字符串格式
--返回123.5; 将123.45转为6个位置的字符串,数字的小数部分舍入为1为小数;
# 转换:ascii码 - ascii
select ascii(123) as '123'
# 格式的转换、显示 - convert : 将第2个参数转换为第1个参数所指定的类型 / 用不同的格式显示日期/时间数据。
-- CONVERT (data_type[(length)], expression [, style]) ;
-- [,style] 日期格式样式
SELECT CONVERT(DateTime, '2020-09-09'); # 返回: 2020-09-09 00:00:00.000
SELECT CONVERT(varchar(5), 92.89); # 返回:92.89
SELECT CONVERT(varchar(11), GETDATE(), 121); # 返回:2010-03-24
常用日期格式:
- 23 :日期格式 yy-mm-dd
- 111:日期格式 yy/mm/dd
- 120:日期格式 yyyy-mm-dd hh:mi:ss(24h)
- 121:日期格式 yyyy-mm-dd hh:mi:ss.mmm(24h)
- 105:日期格式 dd-mm-yy
- 110:日期格式 mm-dd-yy
Data_type : INT / DECIMAL(10,2) / CHAR() / VARCHAR() /
2. 查询:数字相关
| 函数名 | 功能描述 | 举例 |
|---|---|---|
| ABS | 返回表达式绝对值 | SELECT ABS(-90) 返回:90 |
| ROUND | 按指定的精度进行四舍五入 | SELECT ROUND(56.629, 2) 返回:56.630 |
| SQRT | 返回指定表达式的平方根 | SELECT SQRT(9) 返回:3 |
| FLOOR | 返回小于或等于指定数值表达式的最大整数 $\le$ | SELECT FLOOR(23.9) 返回: 23 |
| CEILING | 返回大于或等于指定数值表达式的最小整数 $\ge$ | SELECT CEILING(23.9) 返回:24 |
| POWER | 次方;返回x的y次方 | SELECT POWER(2,3) ; 返回8 |
| EXP | 指数;e的x次方 | SELECT EXP(2) 返回e$^2$ |
| LN /LOG(x,y) | 对数; | SELECT LN(e) ;返回1 |
| MOD | 返回x除以y的余数 | SELECT MOD(9,2); 返回1 |
| SIGN | 判断正负;若x为正返回1;若x为负 返回-1 ; 若x为0 返回0 | SELECT SIGN(2); 返回1 |
3. 查询:聚合函数
- 聚合是在对From和Where子句筛选后的数据集进行聚合计算;即运营逻辑是在其之后执行
- 聚合函数,它的对象是多个观测值,但只返回一个值;若要出现多个观测值的聚合值,需要用到Group by 函数
-
一旦查询包含了聚合函数,那么每一列必须参与到聚合函数中。
- SELECT语句中除聚合函数外,所有列应写在Group By语句后面。否则将出现错误
| 函数名 | 功能描述 |
|---|---|
| AVG | 平均值 |
| SUM | 求和 |
| MAX/MIN | 求最大值/最小值 |
| COUNT | 计算非空单元格( 返回 int 数据类型值) |
| count_big | 计算非空单元格(返回 bigint 数据类型值) |
| VAR | 方差 # 平方 |
| varp | 总体方差 |
| STDEV | 标准差 |
| stdevp | 总体标准差 |
除Count(*)外,所有聚合函数均忽略空值NULL;
avg( ) $\ge$ $sum( ) \over count(*)$
Count(*),计数时也将NULL计入;
其他所有聚合函数,包括Count(col_name)的形式,计算时均已排除了NULL表a,观测值10行,其中2个NULL;
Count(*) # 返回10;Count(列名) # 返回8
除非,可用 isnull() 函数进行转换,来计算;
例如,对表a求平均值,若直接用avg() ,其分母为8;
若想使得其分母变成10,应添加 case when isnull(col_name,0) then col_name else end
4. 查询:日期相关
| 函数名 | 描述 |
|---|---|
| Getdate | 返回当前服务器的日期和时间 |
| Current_timestamp | 除了ANSI标准,等同于Getdate |
| Getutcdate | 返回当前服务器的日期和时间,并转化为格林威治标准时间 |
| Sysdatetime | 返回当前服务器的日期和时间 |
| Sysutcdatetime | 返回当前服务器日期,并转化为格林威治标准时间 |
| Sysdatetimeoffset | 返回Datetimeoffset值 |
- 日期处理函数
| 函数名 | 描述 | |
|---|---|---|
| Dateadd | 在指定的日期上累加数值得到新的日期;dateadd(datepart,number,date) | SELECT DATEADD(yyyy, 4, '01/09/2003') 返回:2007-01-09 |
| datepar是参数的格式:datepart=yy(年),mm(月),qq(季度);date 参数是合法的日期表达式。number 是您希望添加的间隔数;对于未来的时间,此数是正数,对于过去的时间,此数是负数。 | ||
| DATEDIFF | 返回两个日期的差值 ; datediff(datepart,startdate,endate) | SELECT DATEDIFF(dd, '02/05/2003', '02/09/2005') 返回:735 |
| DATEPART | 返回指定日期部分的整数(整数形式) | SELECT DATEPART(dd, '01/09/2003') 返回:9 |
| DATENAME | 返回指定日期部分的字符串(字符串形式);工作日(dw)、周(wk)、日(dd)、月(mm) | SELECT DATENAME(dw, '02/02/2009') 返回: 星期一 |
| YEAR | 返回指定日期“年”部分整数 | SELECT YEAR(GETDATE()) 返回:当前年份整数 |
| MONTH | 返回指定日期“月”部分整数 | SELECT MONTH(GETDATE()) 返回:当前月份整数 |
| DAY | 返回指定日期“日”部分整数 | SELECT DAY(GETDATE()) 返回:当前日期整数 |
查询:日期的应用
# 获取当前时间 - getdate
select getdate();
# 返回指定的时间 - dateadd
select dateadd(dd, 3, '2017-01-31');
# datepart:yy/qq/mm/ww/dd/hh/mi/ss/ms ;
# num为正或为负;
--dateadd()仅接受提取日期部分
# 计算两个时间差 - datediff
select datediff(dd,'2016-06-01', '2017-01-31'); # yy/qq/mm/ww/dd/hh/mi/ss/ms
--datediff(date_type,startdate , enddate)
# 取出时间的某一部分 - datename/datepart
select datename(dd, '2017-01-31'); # datename 字符串形式
select datepart(dd, '2017-01-31'); # datepart 整数形式
# 获取日期的年份/季度/月度/日期等
select year(getdate()); quarter/month/day
参考:日期缩写参考
- datediff / datename / datepart /dateadd
| 日期部分 | 缩写 |
|---|---|
| year | yy, yyyy |
| quarter | qq, q |
| month | mm, m |
| dayofyear | dy, y # 查询date在当年是第多少天. 一年中的第几天; |
| day | dd, d |
| week | wk, ww # 查询date在当年中是第几周 / 以周为单位的间隔数 |
| weekday | **dw **# 一周中的第几天(星期几) |
| Hour | hh |
| minute | mi, n |
| second | ss, s |
| millisecond | ms |
- convert - style的参考值
- 一位或两位数字样式提供两位数的年份;3位数字样式提供4位数字的年份;
| 代码 | Style 格式 |
|---|---|
| 100 或者 0 | mon dd yyyy hh:miAM (或者 PM) |
| 101 | mm/dd/yy |
| 102 | yy.mm.dd |
| 103 | dd/mm/yy |
| 104 | dd.mm.yy |
| 105 | dd-mm-yy |
| 106 | dd mon yy |
| 107 | Mon dd, yy |
| 108 | hh:mm:ss |
| 109 或者 9 | mon dd yyyy hh:mi:ss:mmmAM(或者 PM) |
| 110 | mm-dd-yy |
| 111 | yy/mm/dd |
| 112 | yymmdd |
| 113 或者 13 | dd mon yyyy hh:mm:ss:mmm(24h) |
| 114 | hh:mi:ss:mmm(24h) |
| 120 或者 20 | yyyy-mm-dd hh:mi:ss(24h) |
| 121 或者 21 | yyyy-mm-dd hh:mi:ss.mmm(24h) |
| 126 | yyyy-mm-ddThh:mm:ss.mmm(没有空格) |
| 130 | dd mon yyyy hh:mi:ss:mmmAM |
5. 查询:表格相关
限定行数 - TOP
# TOP n( 前n行 )
SELECT TOP 5 * FROM allzjb; # 查询所有数据的中前5个
------------------------
TOP n PERCENT ( 按百分比取数据 )
SELECT Top 30 PERCENT * FROM allzjb ;
With Ties
- 允许最后的位置包含多行,但这多行是完全相同的
Select top (10) With Ties listprice From ...
随机行选择
- 使用Top(1) 返回单行,且用Newid()随机排序结果;每次将返回一个随机值
- 涉及到较大的表时,可用Tablesample( n Percent/Rows)选项
- 由于是随机选择,可通过Repeatable()来指定 [效果同R语言中的set.seed()]
Select top(1) Lastname From person.person Tablesample(10 Percent) -- 随机选择10%的
Repeatable(1234)
Order by Newid(); --随机排序结果集
分组&排序
分组
- Group by 会根据某一列的值将数据集自动分成子集。
- 对分组集来说,汇总行是每个子集中的每个唯一值组成的行
- 数据集被分成子组之后,聚合函数在每一个子组上执行。
- 对于Group by子句,空值NULL被认为是相等的,并被分组到单个结果行
- Group by不局限于对列分组,也可以对表达式执行分组(但该表达式必须与Select中的相同)
分组后筛选
HAVING
- what :指定组或聚合的搜索条件;HAVING 通常在 GROUP BY 子句中使用,对Group by 之后的表单进行条件筛选;但针对的是所有group by 的字段,而非第一个
Select 交易账号,建平仓,[交易间隔(s)] From #b11 where [交易间隔(s)] < '60'
group by 交易账号,建平仓,[交易间隔(s)]
having count([交易间隔(s)]) >= 2
--指的是对满足所有group by字段的观测值进行计数统计;因为每个观测值都已经按照分组划分为不完全相同的观测值(每行中必定有一个不相等),所以结果为0
- 如果不使用 GROUP BY 子句,则 HAVING 的行为与 WHERE 子句一样。
--HAVING 子句从 SalesOrderID 表中检索超过 SalesOrderDetail 的每个 $100000.00 的总计
SELECT SalesOrderID, SUM(LineTotal) AS SubTotal
FROM Sales.SalesOrderDetail
GROUP BY SalesOrderID
HAVING SUM(LineTotal) > 100000.00
ORDER BY SalesOrderID ;
排序
- Select 指定的每一列都应该出现在Group By子句中,除非对这一列使用了聚合函数;
-
排序:Order by
- 可以使用表达式来指定顺序
- 可以使用列别名指定顺序
- 可以使用列的顺序位置来进行排序
# 按某个组分组并排序
group by name
order by name;
---------------------------------
GROUP BY name
ORDER BY first_name, last_name DESC, SUM(age); # 默认为升序排序(ASC)
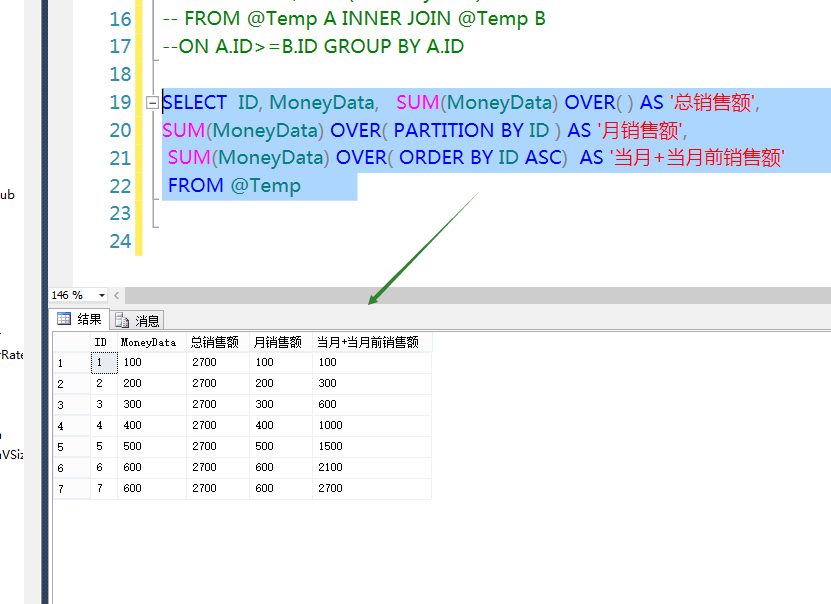
窗口函数 - Select Over()
聚合子句
Sum(cola) Over(partition by col1 order by col2)
--其他聚合函数:avg/max/min /count
# 根据分组求和
Over(Partition by col) --根据col1的分组对cola进行求和; [若同一组别有多个维度,则求和的值是相同的]
# 根据排名求累计和
Over(Order by col2)--根据col2的顺序对cola列累计求和; [若同一组有多个维度,求和的值是累加的]
# 根据分组后的排名,求累积和
Over(Partition by col1 order by col2) --根据Col1的分组进行排名得出Col2的次序,并按col2的次序对cola进行分组求和
# 移动平均
CONVERT(varchar(20),AVG(SalesYTD) OVER (ORDER BY DATEPART(yy,ModifiedDate)),1) AS MovingAvg
在窗口内分区:Partition by
- 执行逻辑:先对查询结果进行排序,之后通过Partition by的列进行分区;
- 窗口函数只能在Select 或者 Group by 子句中
排名 - rank子句
# 排名:无重复排名 - Row_number(组内连续的唯一的)
row_number() over (order by col2); # 对所有进行排名
row_number() over (partition by col1 order by col2); # 根据COL1分组,在分组内部根据 COL2排序
-------------------------------------------------
# 排名:有重复排名 - Rank (若出现字段值相同,序号一样,下一个跳过1位[排名是非连续的])
rank() over([partion by col1] order by col2); 对所有进行排名
ProductID Name LocationID Quantity Rank
494 Paint - Silver 3 49 1
495 Paint - Blue 3 49 1
493 Paint - Red 3 41 3
-------------------------------------------------
# 排名:有重复排名 - Dense_rank (若出现字段值相同,序号一样,后一个不跳过[排名是连续的])
dense_rank() over([partion by col1] order by col2)
ProductID Name LocationID Quantity Rank
494 Paint - Silver 3 49 1
495 Paint - Blue 3 49 1
493 Paint - Red 3 41 2
-------------------------------------------------
# 排名:对序号进行分组处理 - Ntile
ntile (4) over ([partion by col1] order by col2); # (4)表示分为4组
ntile函数的分组依据(约定):
首先系统会去检查能不能对所有满足条件的记录进行平均分组,若能则直接平均分配就完成分组了;若不能,则会先分出一个组,这个组分多少条记录呢?就是 (总记录数/总组数)+1 条,之所以分配 (总记录数/总组数)+1 条是因为当不能进行平均分组时,总记录数%总组数肯定是有余的,又因为分组约定1,所以先分出去的组需要+1条。
分完之后系统会继续去比较余下的记录数和未分配的组数能不能进行平均分配,若能,则平均分配余下的记录;若不能,则再分出去一组,这个组的记录数也是(总记录数/总组数)+1条。
举个例子,将53条记录分配成5组,53%5 = 3不能平均分配,则将余数3平均分配到前3组 (余数 = 分配的组数),然后比较余下的 53-(113)=20 条记录能否平均分配给未分配的2组,能平均分配,则剩下的2组,每组各20/2=10 条记录,分配完成,分配结果为:11,11,11,10,10。*
分页
# Offset & Fetch 必须结合使用
Select ... From
Order by
Offset n rows # 表示跳过n行
Fetch Next 20 rows only # 表示返回之后的20行
条件查询
-
case when
-
最大的优点是可以与Select语句“内联”
-
若else缺失,表示其他值返回NULL
-
Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略;
- 所以,如果根据金额大小来判定等级,必须要最高的金额写在最前面;
-
## 两者区别
1. 输入表达式,只能用于等同性(=)检查
2. 布尔表达式,不局限于等同行(=)检查
--用输入表达式,将与每个where子句中的值比较
Case <input expression> --只能用于等同性检查,而不进行其他比较
when <when exp> then <result exp>
[n...]
[else <result exp>]
End
--给每个when子句提供一个布尔表达式,求值为TRUE或FALSE [布尔值是“真” True 或“假” False 中的一个]
Case
when <Boolean exp> then <result exp>
[n...]
[else <result exp>]
End
## 1.简单Case语句
# 在SELECT语句中,CASE 简单表达式只能用于等同性检查,而不进行其他比较
SELECT ProductNumber, Category =
CASE ProductLine --表示如果 ProductLine = R 则返回 Road; Case之后的变量,为比较的变量
WHEN 'R' THEN 'Road'
WHEN 'M' THEN 'Mountain'
WHEN 'T' THEN 'Touring'
WHEN 'S' THEN 'Other sale items'
ELSE 'Not for sale'
END,
Name
FROM Production.Product ;
--
Select top 10 SalesOrderID % 10 As 'OrderLastDigit',ProductID % 10 As 'ProductLastDigit',
"How Colse ?" = CASE SalesOrderID % 10
WHEN ProductID % 1 THEN 'Exact Match' -- 可在When子句中引用第二个列来做判断
WHEN ProductID % 1-1 THEN 'Within 1'
WHEN ProductID % 1+1 THEN 'Within 1'
ELSE 'More Than One Apart'
END
FROM Sales.SalesOrderDetail ;
-- % 表示返回余数; 5%2 返回1
-- 变量名在Case之前使用双引号(“”)说明,该变量是新创建的变量;但不建议如此;
------------------------------------------------------
## 2. 搜索Case语句
-- 没有输入表达式(即Case关键字与第一个When之间的部分)
-- When表达式必须求值为一个 布尔值;(Case简单语句中,When的表达式可以为1、3、Price+1[含运算])
Select top 10 SalesOrderID % 10 As 'OrderLastDigit',ProductID % 10 As 'ProductLastDigit',
"How Colse ?" = CASE -- 没有输入表达式
WHEN (SalesOrderID % 10) < 3 THEN 'Ends With Less Than Threes'
WHEN ProductID =6 THEN 'ProductID is 6' -- 可在When子句中引用第二个列来做判断
WHEN ABS(SalesOrderID % 10 - ProductID) <= 1 THEN 'Within 1'
ELSE 'More Than One Apart'
END
FROM Sales.SalesOrderDetail ;
# Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略
# 可在条件表达式中混合搭配的字段
# 可执行为任何表达式,只要最后的结果为布尔值
- 搭配其他函数用法
# SELECT CASE WHEN 用法
select userID ,
count(CASE WHEN letterType='干部介绍信' then '1' end)干部介绍信数,
count(CASE WHEN letterType='转递档案通知单' then '1' end)转递档案通知单数
from T_LettersRecord GROUP BY userID
------------------------------------------------------
# WHERE CASE WHEN 用法
SELECT l.letterType, u.realName
FROM T_LettersRecord as l, T_User as u
WHERE (CASE
WHEN l.letterType = '干部介绍信' AND u.userID = '1' THEN 1
WHENl.letterType = '干部介绍信' AND u.userID <> '1' THEN 1
ELSE 0
END) = 1
------------------------------------------------------
# 在 ORDER BY 子句中使用 CASE
--计算 SalariedFlag 表中 HumanResources.Employee 列的值。SalariedFlag 设置为 1 的员工将按 BusinessEntityID 以降序顺序返回。 SalariedFlag 设置为 0 的员工将按 BusinessEntityID 以升序顺序返回
SELECT BusinessEntityID, SalariedFlag
FROM HumanResources.Employee
ORDER BY CASE SalariedFlag WHEN 1 THEN BusinessEntityID END DESC
,CASE WHEN SalariedFlag = 0 THEN BusinessEntityID END;
------------------------------------------------------
# GROUP BY CASE WHEN 用法
SELECT
CASE WHEN salary <= 3000 THEN 'T1'
WHEN salary > 3000 AND salary <=8000 THEN'T2'
WHEN salary > 8000 AND salary <=12000 THEN'T3'
WHEN salary > 12000 AND salary <= 20000 THEN 'T4'
ELSE NULL END 级别名称, -- 别名命名
COUNT(*)
FROM t_userSalary
GROUP BY
CASE WHEN salary <= 3000 THEN 'T1'
WHEN salary > 3000 AND salary <=8000 THEN'T2'
WHEN salary > 8000 AND salary <=12000 THEN'T3'
WHEN salary > 12000 AND salary <= 20000 THEN 'T4'
ELSE NULL END;
联接与联合
- what:将两个数据集相乘,并对结果进行限制。这样只返回两个数据集的交集。
- why :横向合并两个数据集,并通过匹配一个数据源的行与另一个数据源的行,从组合中产生新的数据集。
当涉及多个联接时
一定要用较小规模的数据对查询进行单元测试;
并坚持使用左外联接
内联接
Inner Join
-
在连接条件中使用等于号(=)运算符,其查询结果中列出被连接表中的所有列,包括其中的重复列。
-
在连接条件中使用除等于号之外运算符(>、<、<>、>=、<=、!>和!<)
-
多个数据源的联接(顺序并不重要)
- 所要获得字段的表要写在最前面;即From之后;
- 可实现A联接B,B联接C,C联接D;
Select cst.companyname, prod.name From Customre As cst Inner join salesorderhead As soh On cst.customerid = soh.customerid Inner join salesorderdetail As sod On soh.salesorderid = sod.salesorderid Inner join product As prod On sod.productid = prod.productid
外联接
-
what:以一个表为基准表,进行联接;
- 若使用外联接,顺序非常重要
-
how :无论是否匹配,外联接都包含所有数据
-
外联接中的条件设置(执行逻辑)
- 当条件位于Join子句中,先包括外表的所有行,然后用条件包括第二个表中的行
- 当条件位于Where子句中,先执行联接,然后将条件应用于联接行
# 条件位于Join子句
Select a.col, b.col
From table As a
Left join table2 As b
On a.id = b.id
And a.Lastname = 'Adams' --该条件限制的是第二个表中的行
[And a.Lastname = b.name] --也可以再进行限制
------------------------------------------
# 条件位于Where子句中
Select a.col, b.col
From table As a
Left join table2 As b
On a.id = b.id
Where a.Lastname = 'Adams' --该where条件是对联接后的表进行限制
Left [Outer] Join
- 返回左表中的所有行,如果左表中行在右表中没有匹配行,则结果中右表中的列返回空值。
必须要表基准表放在左侧,非常重要!否则会产生大量NULL值。
Right [Outer] Join
- 恰与左连接相反,返回右表中的所有行,如果右表中行在左表中没有匹配行,则结果中左表中的列返回空值。
建议左/右外联接不要混合使用
Full [Outer] Join
- 返回左表和右表中的所有行。即返回两个数据集的所有数据。当某行在另一表中没有匹配行,则另一表中的列返回空值
交叉联接
Cross Join
- 不带WHERE条件子句,它将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积
- (例如:T_student和T_class,返回4*4=16条记录)
- 如果带where,返回或显示的是匹配的行数。
差集查询
- what:分析两个数据集之间相关性的查询;
- why :用于查找不存在或不匹配的数据
- how :一般需分两步来执行
- 联接
- 设置第二个数据集的主键为NULL
# 左差集查询
--不在右表中的左表数据集;【可用Inner Join 中不等号为条件进行联接 <>】
Select c.customerid, so.ordernumber
From customer As c
Left join salesorder As so On c.customerid = so.customerid
Where so.ordernumer Is Null; --设置第二个表的主键为NULL
# 全差集查询
Select c.customerid, so.ordernumber
From customer As c
Left join salesorder As so On c.customerid = so.customerid
Where so.customerid Is Null
or c.customerid Is Null
--设置两个表的的主键为NULL
联合 - Union
- 返回每个结果集中的所有行
- Union ,表示删除重复行
- Union ALL ,表示不考虑是否存在重复行
- 每个Select必须具有相同的数量、类型;
- 列名或别名由第一个Select确定
- Order by子句放在最后,并且对所有结果进行排序,且列名必须是第一个Select语句中存在的
- 可用Select Into,但Into必须放在第一个Select语句中
列的xml数据类型必须为等效。
所有的列必须类型化为 XML 架构或是非类型化的。 如果要类型化,这些列必须类型化为相同的 XML 架构集合。
子查询
非相关子查询
-
what:子查询是独立运作的;
-
how :运行逻辑
- 非相关子查询被执行一次
- 结果传输到外查询
- 外查询被执行一次
Select (Select 3) As subqueryvalue;
公用表表达式
- what:CTE (Comman Table Expression )
- why :确定查询结果可当做临时视图来使用;即后续的查询可以引用公共表表达式中的表及字段;
- how :CTE使用With子句,而With子句定义了CTE;在With子句内分别是名称、别名、AS、括号、Select查询语句
- CTE自身只是一个不完整的SQL语句
- 一旦With子句中定义了CTE,查询的主要部分就可以使用其名称引用CTE;就像CTE是其他任何表源一样;
- 若将多个CTE包含在相同的查询中,在主查询之前确定CTE的顺序,并用逗号分隔;并且后面的CTE可以引用在它之前定义的任何CTE
- CTE不能嵌套
# With子句的表达式格式
With CTEname [Col Aliases]
As (Select ...From ...
)
------------------------------------------------------
With
CTEname1 (col names) As (Select) ,
Ctename2 (col names) As (Select)
Select ...
From CTEname1
Inner join CTEname2 On
相关子查询
- what:先执行外查询,相关子查询的运行要引用外查询中的列
- why :对于复杂的Where条件来说很有用
- how :执行逻辑
- 先执行一次外查询
- 在外查询中对每一行执行一次子查询,把外查询中的值取代为子查询的每一次执行
- 子查询的结果要整合到结果集中
子查询可出现在Select子句中,也可以出现在Where 子句中;
判断是否为相关子查询的标准为是否引用了外查询中的列;
没有引用外查询中的列,为非相关子查询;先于外查询运行
引用了外查询中的列,为相关子查询,后于外查询运行
批处理
- what :同时从应用程序发送到 SQL Server 并得以执行的一组单条或多条 Transact-SQL 语句;SQL Server 将批处理的语句编译为单个可执行单元,称为执行计划。执行计划中的语句每次执行一条。
- how :
- 在遇到运行时错误的语句之前执行的语句不受影响。
- 唯一例外的情况是批处理位于事务中并且错误导致事务回滚。在这种情况下,所有在运行时错误之前执行的未提交数据修改都将回滚。
- 批处理终止批处理分隔关键字是GO。批处理关键字必须是这一行的唯一关键字;
- 关键字GO之后可添加一个注释
- 切换数据库:把USE命令插入到批处理中
GO(Transact-SQL)
- what :向 SQL Server 实用工具发出一批 Transact-SQL 语句结束的信号
- how :当前批语句由上一 GO 命令后输入的所有语句组成,如果是第一条 GO 命令,则由即席会话或脚本开始后输入的所有语句组成。
- GO 命令和 Transact-SQL 语句不能在同一行中。但在 GO 命令行中可包含注释
# GO [count] ; # count 一个正整数,GO 之前的批处理将执行指定的次数
-
语句终止:在每个命令的末尾放置一个分号(;)
- 在CTE前面必须要放一个分号(当CTE不是批处理的第一条语句时)
- 不要把分号放在If 或者 While 条件之后
- 不要把分号缝在 End Try 之后
- 语句终止符必须跟在Meger之后
声明:DECLARE
- DECLARE;制定某个变量为特定的数据类型,并可指定具体内容;
- Declare变量跟 变量名 和 数据类型,并用分号结尾;
- 单个Declare 声明中用逗号隔开多个变量
- 变量赋值用分号隔开;
- 变量是在批处理或过程的主体中用 DECLARE 语句声明的,并用 SET 或 SELECT 语句赋值。 游标变量可使用此语句声明,并可用于其他与游标相关的语句。 除非在声明中提供值,否则声明之后所有变量将初始化为 NULL
Declare @test Int, @testtwo Varchar(20) ;
Set @test = 1 ;
Set @testtwo = 'a value' ;
使用Set 和 Select 命令
- Set 与 Select 对比
| 命令 | 描述 |
|---|---|
| Set | 限制在从表达式中检索数据; |
| 一次只能设置一个变量 | |
| Select | 可从数据源中检所数据,还可包括其他Select子句(From、Where等);可使用函数 |
| 一次课设置多个变量 |
Set命令可以使用访问数据源的标量子查询(一个变量)
如果你希望在确保没有行的情况下将变量设置为NULL,以及在不止一行的情况下获得一个错误,这是最佳做法;
Select 命令在检索多行时,只会将最后一行的值存储在变量中
Use adventureworks2012
GO
Declare @productID Int, @producename varchar(25);
Set @productID = 782; --声明一个变量
Select
@productID = productID, -- 声明多个变量;
@productname = @productID + name --声明变量可叠加使用
From production.product
Order by productID;
Select 声明,即将 @var = value 作为一个整体,当做Select查询中的列去看待即可
声明变量可叠加使用
- 如果Select语句没有返回行,Select语句不会影响变量
GO
Declare @productID Int, @producename varchar(25);
Set @productID = 999;
Select
@productID = productID, -- 声明多个变量;
@productname = @productID + name --声明变量可叠加使用
From production.product
Where productID = 1000; -- 由于ProductID 没有1000,故ProductID仍未NULL
- 声明示例
# DECLARE @local_var data_type [= value]
# 直接声明
declare @mycounter int;
DECLARE @find varchar(30) = 'Man%'; # 使用名为 @find 的局部变量检索所有姓氏以 Man 开头的联系人信息
--Select ... WHERE LastName LIKE @find;
# 使用select声明
DECLARE @var1 varchar(30)
SELECT @var1 = (SELECT Name FROM Sales.Store WHERE CustomerID = 1000)
# 用声明并赋值过的变量构建一个Select语句并查询
Select lastname,firstname,title
From employees
where firstname= @firstnamevariable or region=@regionvariable
# 声明日期,并应用
DECLARE @起始日期 date set @起始日期 = dateadd(dd,-3,getdate())
Select top 100 * From [exchange].[YTX].[v_allcj] where 结算日期 = @起始日期
------------------------------------------------
# 声明多个变量
declare @last_name varchar(30),@fname varchar(20);
DECLARE @起始日期 datatime, @截止日期 datatime
set @起始日期 = '2017-03-07';
set @截止日期 = '2017-03-07';
# 给多个变量赋值
declare @firstnamevariable varchar(20), @regionvariable varchar(30)
set @firstnamevariable='anne'
set @regionvariable ='wa'
------------------------------------------------------------
全局变量
select @@version --返回数据库版本
select @@error --返回最后的一次脚本错误
select @@identity --返回最后的一个自动增长列的id
过程流
- 使用条件T-SQL的If命令
- 一个if,一个命令的执行;并且没有Then和End来终止if命令;
If condition
Statement;
If 1=0
Print 'Line one';
Print 'Line two';
--结果返回Line two;
--if语句之后没有分号; if语句实际上是后面语句的提前;
----------------------------------------------------------------------------------
# 使用Begin / End 有条件地执行多条语句
If condition
Begin;
Multipie Line;
End; --每个都有分号
- 使用If Exists()作为基于存在性的条件
- If Exists() 结构使用从SQL Select语句返回的每一行作为条件。
- 因为If Exists() 结构会查找每一行,所以Select语句应当选择所有的列。一旦一个单行满足了If Exists(),查询就会继续执行
If Exists
(Select * From production.product Where quantity = 0)
Begin;
Print 'Relpenish Inventory';
End;
- 使用If / Else 执行替换语句
- 可选的Else定义了if条件为False时的执行代码;Else可控制下一个单个命令,后者Begin/End块
If condition
Single line or Begin/End block of code;
Else
Single line or Begin/End block of code;
--
使用While循环
- what :当条件为ture时循环代码;
数据清洗
去重复值
--Distinct # 去除完全重复的值
SELECT DISTINCT 机构 FROM allzjb ;
--Row_number() over(partation by col1 order by col2) 某个字段有重复值
--【先根据某相同字段分组,根据其他字段排序,创建临时表;在提取排序=1的信息】
# 对于相同的交易账号,取激活时间最前面的那一个账户的相关信息;
Select *, Row_number() Over(partition by 交易账号 order by 激活时间) as 排序 Into #11
From exchange.ytx.ext_激活客户归属表;
Select * Into #2 From #11 where 排序 = '1';
NULL
- what:空值NULL表示不存在的值,是一个未知值;并不表示0;
- how :包含空值的任何表达式结果均是一个未知值
- Null + 1 = Null
聚合函数中SUM( ) 与AVG( ) 会自动排除NULL进行计算;
Count( * ) 会计算空值;但Count( col )会排除空值
# 测试空值 - IS NULL
SELECT * FROM allzjb where 机构 is null ;
-------------------------------------------------------
# ISNULL 将NULL替换为某个值
SELECT AVG(ISNULL(Weight, 50)) FROM Production.Product; # 将Weight中的NULL替换为50
--
## 处理空值
# Isnull() --将NULL替换为某个值
Select Isnull(col, 0) -- 对col列进行搜索,并将空值NULL转换为0;也可以是其他任意值/字符串
--isnull(soucre_expression, prlacement_value) # isnull是T-SQL特有的函数
-----------------------------------------------------------------------------
# Coalesce()
Select Coalesce(Null, Null+1, 1+2, "abc") 返回3
--Coalesce(expression, expression,... ) # 接受一系列表达式或列,返回第一个非空值
-----------------------------------------------------------------------------
# Nullif()
NULL :未定义的值 / 不存在
NA :缺失数据
NaN :无意义的数,比如sqrt(-2), 0/0。
Inf :正无穷大
-Inf :负无穷大
数据运算
两行观测值相减
# 根据某个字段先排序进行编号,创建为#a1;复制为另一个表#a2;通过联合,使得联合的条件为 #a1.rank+1 = #a2.rank
Select *, order by 成交时间 as rank into #a1 From [exchange].[YTX].[v_allcj] as cj;
Select * into #a2 From #a1;
Select a1.*, datediff(ss,#a1.成交时间,#a2.成交时间) s [交易间隔(s)] From #a1
Left join #a2 On #a1.rank = #a2.rank +1
# 根据某个字段【分组】后排序编号;再通过唯一列联接,再设置条件 a.rank+1=b.rank 进行相减【理论上应该是 a.rank=b.rank+1】
Select *, Row_number() over(partition by 交易账号 order by 成交时间) as [rank] into #a1
From [exchange].[YTX].[v_allcj] as cj;
Select * into #a2 From #a1;
Select #a1.*, datediff(ss,#a1.成交时间,#a2.成交时间) as [交易间隔(s)] From #a1
Left join #a2 On #a1.交易账号 = #a2.交易账号
where #a1.rank+1 = #a2.rank
and datediff(ss,#a1.成交时间,#a2.成交时间) < '60'
注释
-
--双连字符;从开始到行尾均为注释;对于多行注释,必须在每一个开头多使用 -
/*……*/正斜杠 星号;- 可在同一行,可另起一行;在这之间的全部内容均为注释(可跨行);
- 可在代码内执行
参照文档
select * from #100
pivot(
sum(人数) for 资金等级 in ([100万以下])) as B 转置


