Python学习记录-tensorflow ...
2018-10-17 本文已影响23人
听风轻咛
numpy
- np.identity
返回一个单位矩阵 - np.concatenate
https://img-blog.csdn.net/20180414163140310?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0tvbF9tb2dvcm92/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70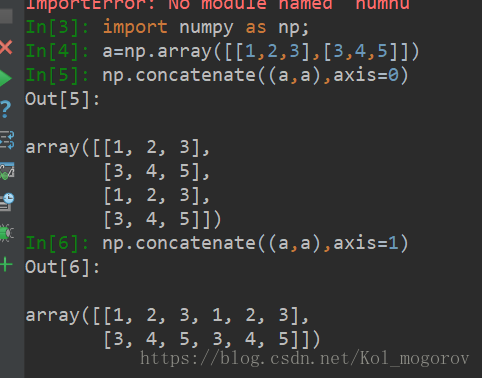 image_1cptvo746g3farv1glq14v31kos9.png-36.3kB
image_1cptvo746g3farv1glq14v31kos9.png-36.3kB
axis = i, 则在第i维上发生变化; - np.transpose
转置
python
- callable
callable() 函数用于检查一个对象是否是可调用的。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
对于函数, 方法, lambda 函式, 类, 以及实现了__call__方法的类实例, 它都返回 True。
tensorflow
-
nn.conv2d
tf.nn.conv2d(input_batch, kernel,\ strides=[image_batch_size_stride, \ image_height_stride, \ image_width_stride,\ image_channels_stride], padding='SAME') -
tf.variable_scope
tf.variable_scope, 用于定义创建变量(层)的操作的上下文管理器;with tf.variable_scope("foo"): with tf.variable_scope("bar"): v = tf.get_variable("v", [1]) assert v.name == "foo/bar/v:0" -
tf.summary
tf.summary.histogram(tags, values, collections=None, name=None) # 用来显示直方图信息,一般用来显示训练过程中变量的分布情况 tf.summary.scalar(tags, values, collections=None, name=None) # 用来显示标题信息,一般在画loss,accuary时会用到 -
tf.cast
将x的数据格式转化成dtype.例如,原来x的数据格式是bool,
那么将其转化成float以后,就能够将其转化成0和1的序列。反之也可以a = tf.Variable([1,0,0,1,1]) b = tf.cast(a,dtype=tf.bool) sess = tf.Session() sess.run(tf.initialize_all_variables()) print(sess.run(b)) #[ True False False True True] -
tf.ConfigProto
# tf.ConfigProto()的参数 log_device_placement=True : 是否打印设备分配日志 allow_soft_placement=True : 如果你指定的设备不存在,允许TF自动分配设备 tf.ConfigProto(log_device_placement=True,allow_soft_placement=True) -
tf.truncated_normal_initalizer
这是神经网络权重和过滤器的推荐初始值。tf.truncated_normal_initializer 从截断的正态分布中输出随机值。 生成的值服从具有指定平均值和标准偏差的正态分布, 如果生成的值大于平均值2个标准偏差的值则丢弃重新选择。 -
sess.run
-
tf.train.Coordinator()
TensorFlow提供了两个类来实现对Session中多线程的管理:tf.Coordinator和 tf.QueueRunner,这两个类往往一起使用。
Coordinator类用来管理在Session中的多个线程,可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常,该线程捕获到这个异常之后就会终止所有线程。使用 tf.train.Coordinator()来创建一个线程管理器(协调器)对象。# -*- coding:utf-8 -*- import tensorflow as tf import numpy as np # 样本个数 sample_num=5 # 设置迭代次数 epoch_num = 2 # 设置一个批次中包含样本个数 batch_size = 3 # 计算每一轮epoch中含有的batch个数 batch_total = int(sample_num/batch_size)+1 # 生成4个数据和标签 def generate_data(sample_num=sample_num): labels = np.asarray(range(0, sample_num)) images = np.random.random([sample_num, 224, 224, 3]) print('image size {},label size :{}'.format(images.shape, labels.shape)) return images,labels def get_batch_data(batch_size=batch_size): images, label = generate_data() # 数据类型转换为tf.float32 images = tf.cast(images, tf.float32) label = tf.cast(label, tf.int32) #从tensor列表中按顺序或随机抽取一个tensor准备放入文件名称队列 input_queue = tf.train.slice_input_producer([images, label], num_epochs=epoch_num, shuffle=False) #从文件名称队列中读取文件准备放入文件队列 image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=2, capacity=64, allow_smaller_final_batch=False) return image_batch, label_batch image_batch, label_batch = get_batch_data(batch_size=batch_size) with tf.Session() as sess: # 先执行初始化工作 sess.run(tf.global_variables_initializer()) sess.run(tf.local_variables_initializer()) # 开启一个协调器 coord = tf.train.Coordinator() # 使用start_queue_runners 启动队列填充 threads = tf.train.start_queue_runners(sess, coord) try: while not coord.should_stop(): print '************' # 获取每一个batch中batch_size个样本和标签 image_batch_v, label_batch_v = sess.run([image_batch, label_batch]) print(image_batch_v.shape, label_batch_v) except tf.errors.OutOfRangeError: #如果读取到文件队列末尾会抛出此异常 print("done! now lets kill all the threads……") finally: # 协调器coord发出所有线程终止信号 coord.request_stop() print('all threads are asked to stop!') coord.join(threads) #把开启的线程加入主线程,等待threads结束 print('all threads are stopped!')


