# Flume - 初用Flume 1.8.0
Flume - 初用Flume
在Flume中,最重要的三个部件分别为:
- source
- channels
- sink
在本例中我们使用如图的架构来进行Flume数据采集:
<center> FlumeDemo.png-7.5kB
FlumeDemo.png-7.5kB
</center>
当前使用的flume版本号为1.8.0,如果相对其他类别的配置有更详细的了解,可查看:http://flume.apache.org/FlumeUserGuide.html
对于flume中的使用主要是对于配置文件的使用,本文所使用的的配置文件名为flume安装目录下的conf/flume-conf.properties
一、总体配置
agent.sources = dirSrc
agent.channels = memoryChannel
agent.sinks = kafkaSink
在这里面我们总共做了如下几个事情:
- 定义该flume应用的名称为agent
- 该应用的sources名称为dirSrc
- 该应用的channels名称为memoryChannel
- 该应用的sinks名称为kafkaSink
二、定义sources
我们使用的 sources 类型为Spooling Directory Source。
其作用是:监听一个文件夹,收集文件夹下新文件数据,收集完新文件数据会将文件名称的后缀改为.COMPLETED,缺点是不支持老文件新增数据的收集,并且不能够对嵌套文件夹递归监听。
我们配置文件的内容为:
agent.sources.dirSrc.type = spooldir
agent.sources.dirSrc.spoolDir=/mnt/vdb/bigdata/flume/data
agent.sources.dirSrc.fileHeader=true
agent.sources.dirSrc.channels = memoryChannel
关键参数说明:
- type:source类型为spooldir。
- spoolDir:source监听的文件夹。
- fileHeader:是否添加文件的绝对路径到event的header中,默认值false。
- fileHeaderKey:添加到event header中文件绝对路径的键值,默认值file。
- selector.type:选择器类型,默认replicating(可选值为replicating或multiplexing)。
- fileSuffix:收集完新文件数据给文件添加的后缀名称,默认值:.COMPLETED。
- channels:Source对接的Channel名称。
三、定义channels
Memory Channel读写速度快,但是存储数据量小,Flume进程挂掉、服务器停机或者重启都会导致数据丢失。部署Flume Agent的线上服务器内存资源充足、不关心数据丢失的场景下可以使用。
我们配置文件的内容为:
agent.channels.memoryChannel.type=memory
agent.channels.memoryChannel.capacity=10000
agent.channels.memoryChannel.transactionCapacity=10000
关键参数说明:
- type:channel类型memory。
- capacity:channel中存储的最大event数,默认值100。
- transactionCapacity:一次事务中写入和读取的event最大数,默认值100。
- keep-alive:在Channel中写入或读取event等待完成的超时时间,默认值3(单位秒)。
- byteCapacityBufferPercentage:缓冲空间占Channel容量(byteCapacity)的百分比,为event中的头信息保留了空间,默认值20(单位:百分比)。
- byteCapacity:Channel占用内存的最大容量,默认值为Flume堆内存的80%,如果该参数设置为0则强制设置Channel占用内存为200G。
四、定义Sinks
Kafka是一款开源的分布式消息队列,在消息传递过程中引入Kafka会从很大程度上降低系统之间的耦合度,提高系统稳定性和容错能力。Flume通过Kafka Sink将Event写入到Kafka中的主题,其他应用通过订阅主题消费数据。Flume1.7开始支持Kafka0.9及以上版本。
我们配置文件的内容为:
agent.sinks.kafkaSink.channel=memoryChannel
agent.sinks.kafkaSink.type=org.apache.flume.sink.kafka.KafkaSink
agent.sinks.kafkaSink.kafka.topic=sensor_data
agent.sinks.kafkaSink.kafka.bootstrap.servers=master:9092
agent.sinks.kafkaSink.kafka.flumeBatchSize=100
agent.sinks.kafkaSink.kafka.producer.acks=1
agent.sinks.kafkaSink.kafka.producer.linger.ms=10
agent.sinks.kafkaSink.kafka.producer.compression.type=lz4
关键参数说明:
- type:Sink类型,值为KafkaSink类路径org.apache.flume.sink.kafka.KafkaSink。
- kafka.bootstrap.servers:Broker列表,定义格式host:port,多个Broker之间用逗号隔开,可以配置一个也可以配置多个,用于Producer发现集群中的Broker,建议配置多个,防止当前Broker出现问题连接失败。
- kafka.topic:Kafka中Topic主题名称,默认值为flume-topic。
- flumeBatchSize:Producer端单次批量发送的消息条数,该值应该根据实际环境适当调整,增大批量发送消息的条数能够在一定程度上提高性能,但是同时也增加了延迟和Producer端数据丢失的风险。默认值为100。
- kafka.producer.acks:设置Producer端发送消息到Borker是否等待接收Broker返回成功送达信号。0表示Producer发送消息到Broker之后不需要等待Broker返回成功送达的信号,这种方式吞吐量高,但是存在数据丢失的风险,“retries”配置的发送消息失败重试次数将失效。1表示Broker接收到消息成功写入本地log文件后向Producer返回成功接收的信号,不需要等待所有的Follower全部同步完消息后再做回应,这种方式在数据丢失风险和吞吐量之间做了平衡。all(或者-1)表示Broker接收到Producer的消息成功写入本地log并且等待所有的Follower成功写入本地log后向Producer返回成功接收的信号,这种方式能够保证消息不丢失,但是性能最差。默认值为1。
- useFlumeEventFormat:默认情况下,Producer只会将Event主体信息以字节形式发送到Kafka Topic中。如果设置为true,Producer发送到Kafka Topic中的Event将能够保留Producer端头信息,以Flume Avro二进制形式存储,结合下游Kafka Source或者Kafka Channel中的parseAsFlumeEvent属性一起使用。默认值为false。
五、启动命令
进入到flume的解压目录下:
bin/flume-ng agent -n agent -c conf -f conf/flume-conf.properties
运行,之后可以使用 jps 里面查看服务有无启动,服务名称为Application。
<center>
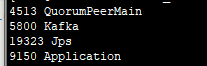 进程查看.png-2.8kB
</center>
进程查看.png-2.8kB
</center>
六、运行结果
在定义 Source 的时候,我们定义的路径为/mnt/vdb/bigdata/flume/data,在程序运行之前我们可以查看到该目录下的文件:
<center>
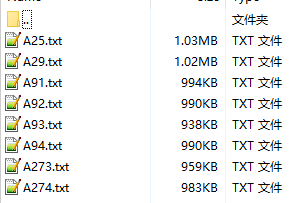 输入数据.png-5.7kB
</center>
输入数据.png-5.7kB
</center>
在 Flume 程序运行之后,我们可以看到文件发生了改变:
<center>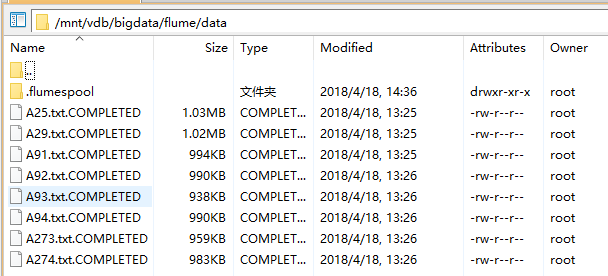 输出数据.png-27.3kB
输出数据.png-27.3kB
</center>
同时在定义kafkaSink的时候,我们定义的topic为 sensor_data,进入到kafka的安装目录下,我们可以使用如下命令来查看主题列表:
bin/kafka-topics.sh --list --zookeeper localhost:2181/kafka
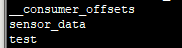 kafka主题.png-1.3kB
kafka主题.png-1.3kB
</center>
同时我们可以启动 窗口消费者 去查看主题中是否存有数据:
bin/kafka-console-consumer.sh --zookeeper localhost:2181/kafka --topic sensor_data --from-beginning
 kafka主题数据.png-1.2kB
kafka主题数据.png-1.2kB
</center>
从图片中我们可以看到,已经消费完所有数据进入阻塞态,等待新数据的接入。
七、启动时Trouble shooting
当应用启动时没有得到对应的结果时,应该首先查看flume安装目录下的logs文件夹,查看flume.log文件,用于判断应用启动失败的原因:
比如我在启动时遇到了这样的一个异常:
org.apache.flume.FlumeException: Unable to create sink: kafkaSink, type: org.apache.flume.source.kafka.KafkaSource, class: org.apache.flume.source.kafka.KafkaSource
这是因为我在定义agent.sinks.kafkaSink.type属性时,把类路径写错了,因此无法正常启动。
八、如何关闭Flume
使用kill命令
kil pid
九、Flume - 启动命令详解
https://blog.csdn.net/qianshangding0708/article/details/48088611


