Design Efficient Deep Learning D
Design Efficient Deep Learning Data Loading Module
数据的加载是机器学习系统很重要的一部分. 特别是数据量很大, 无法整体加载到内存的时候. 数据加载模块比较普遍的设计目标是获得更高的加载效率,花费更少的精力在数据预处理,简洁和灵活的接口.
这个教程按照下面的方式来组织: 在 IO Design Insight 部分, 我们介绍了关于数据加载模块的设计的思考和指导原则; 在 Data Format 部分, 我们介绍了基于 dmlc-core 的二进制格式 recordIO 的具体实现; 在 Data Loading 部分, 我们介绍了利用了 dmlc-core 提供的 Threadediter 来掩盖 IO 开销的方法; 在 Interface Design 部分, 我们展示如何用几行 python 代码简单的方法来构建 MXNet 的数据迭代器; 在 Future Extension 部分, 我们讨论了如何让数据加载的过程更加灵活来支持更多的学习任务.
我们会涉及下面提到的重要需求,详细的介绍在这部分内容的后半部分.
List of Key Requirements
- Small file size.
- Allow parallel(distributed) packing of data.
- Fast data loading and online augmentation.
- Allow quick read arbitrary parts in distributed setting.
Design Insight
IO design 部分通常涉及两种工作: 数据预处理和数据加载. 数据预处理会影响数据的离线处理花费时间, 而数据加载会影响在线处理的性能. 在这部分, 我们将会介绍我们在 IO design 中涉及的这两个阶段的思考.
Data Preparation
数据预处理是将数据打包成后面处理过程中需要的确定的格式. 当数据量非常庞大的时候, 比如说 ImageNet, 这个过程是非常耗时的. 因为如此, 我们需要在几个方法多多花点心思:
- 将数据集打包成小数量的文件. 一个数据集可能包含百万的样本数据. 打包好的数据在机器之间的很容易地分发;
- 只打包一次. 当运行环境的设置变化的时候, 不需要重新对数据进行打包 (通常就是修改了运行的机器的数量);
- 并行打包来节省时间;
- 容易地读任意部分. 这一点对于引入并行机器学习训练的时候非常重要. 把数据打包整数量很少的几个物理文件会让事情变得很麻烦. 我们理想的状态是: 打包好的数据集可以逻辑上分成任意的
partition而不用关心有多少物理数据文件. 比如说我们把 1000 张图片均匀地打包成四个物理文件, 每个物理文件包含 250 张图片. 然后我们用 10 个机器来训练 DNN 模型, 我们应该可以让每台机器加载大约 100 张图片. 所以有些机器需要从不同的物理文件中读取数据.
Data Loading
数据加载的工作是将打包好的数据加载到内存中. 一个最终的目标就是加载的尽可能的快速. 因此有几件事情是需要我们注意的:
- 连续读取数据. 这是为了避免从硬盘上随机读数据;
- 减小读取数据的大小. 可以通过压缩数据的方式达到目的, 比如将数据用 JPEG 格式存储;
- 加载数据和训练模型用多线程来做. 这样可以通过计算掩盖数据加载的时间开销;
- 节省内存. 如果数据很大, 我们不想要把整个数据集加载进入内存中.
Data Format
因为训练深度模型需要海量的数据, 所以我们选择的数据格式应该高效和方便.
为了实现我们想到的目标, 我们需要打包二进制位一个可分割的格式. 在 MXNet 中我们使用 dmlc-core 实现的二进制格式 recordIO 作为我们基本的数据存储格式.
Binary Record
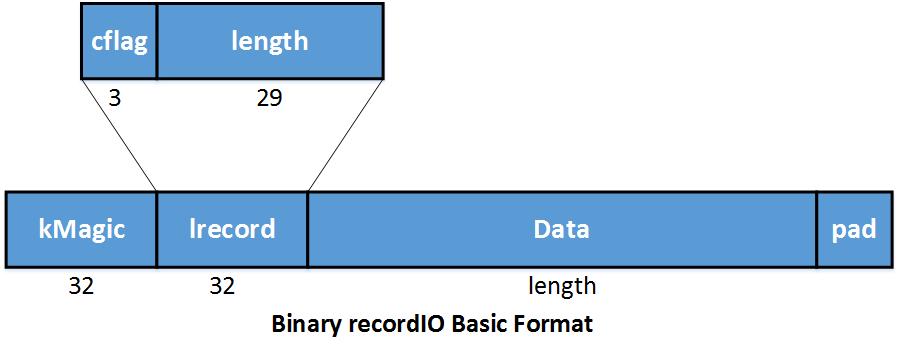 baserecordio
baserecordio
在 recordIO 中每个样本被存储为一条 record. kMagic 是指示样本开始的 Magic Number. Lrecord 编码了长度 (length).
在 lrecord 中,
- 如果
cflag == 0: 这是一个完整的 record; - 如果
cflag == 1: 这是multiple-rec的开始部分; - 如果
cflag == 2: 这是multiple-rec的中间部分; - 如果
cflag == 3: 这是multiple-rec的结束部分.
Data 是存储数据的空间. Pad 为了4 bytes 对齐 做的简单的填充.
当对数据打包之后, 每个文件包含多条 record. 通过连续硬盘读的方式加载数据. 这个可以有效的避免随机硬盘读的低效.
将每条数据储存为 record 的特别很大的好处就是每个 record 的长度是可以不同. 这样我们可以根据不同类型的数据特性采用不同的压缩算法来压缩数据. 比如说我们可以用 JPEG 格式来存储图像数据. 这样打包好的数据会比直接用 RBG 格式存储的情况紧凑很多. 我们拿 ImageNet_1K 数据集举个例子, 如果按照 3*256*256 原始的 RGB 格式存储, 数据集大小超过 200G, 当我们将数据集用 JPEG 格式存储, 只需要 35G 的硬盘空间. 它会极大的降低读取硬盘的开销.
下面拿存储图像的二进制格式 recordIO 举个例子:
我们首先将数据 resize 成 256*256 大小, 然后压缩成 JPEG 格式, 接着我们将标志着图像的 index 和 label 的 header存储下来, 这个 header 对重建数据很有用. 我们用这种格式将几个图像打包到一个文件中.
Access Arbitrary Parts Of Data
我们想要的数据加载部分的行为: 打包好的数据逻辑上可以划分为任意数目的 partition, 而不需要考虑实际上有多少个物理的打包好的文件.
既然二进制的 recordIO 可以很容易的通过 Magic Number 来定位一条 record 的起始, 我们可以使用 dmlc-core 提供的 InputSplit 功能来实现这一点.
InputSplit 需要下面的几个参数:
- FileSystem *filesys: dmlc-core 封装了不同文件系统的 IO 操作, 比如 hdfs, S3, local. 用户不需要关心这些文件系统具体的不同之处;
- Char *uri: 文件的 uri. 需要注意的是, 这个参数可以是一个文件列表, 我们可以将数据打包到几个不同的文件中. File uris 使用 ';' 来分割;
- Unsigned nsplit: 逻辑分片的数目. Nsplit 可以和物理文件数目不同;
- Unsigned rank: 表示当前进程要加载的数据部分;
下面是切分过程的演示:
- 统计每个物理分块的大小. 每个文件包含若干 record;
 beforepartition
beforepartition
- 根据文件的大小, 粗略地切分. 需要注意的是, 可能切分的边界在某个 record 中间;
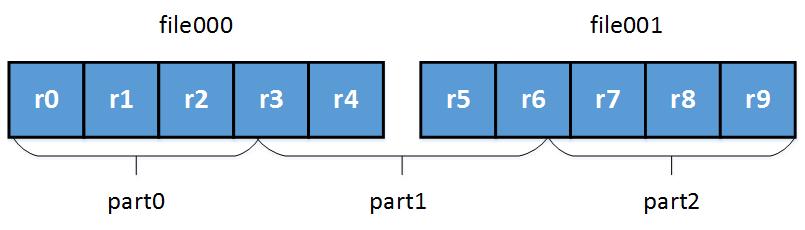 approxipartition
approxipartition
- 找到 record 的起始位置, 避免切分之后 record 不完整;
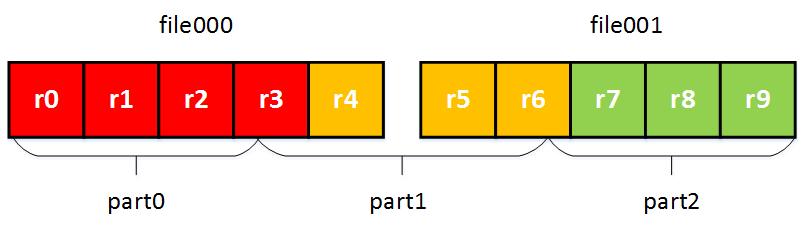 afterpartition
afterpartition
通过执行以上的操作, 我们可以将不同的 record 划分到不同的分区中, 以及每个逻辑分区部分对应的一个或者多个物理文件. InputSplit 极大的降低了数据并行的难度, 每个进程只需要读取自己需要的那部分数据.
因为逻辑分区不依赖于物理文件的数目, 我们可以上面提到的技术来处理像 ImageNet_22K 这样的海量数据集. 我们不需要关心数据预处理阶段的分布式加载, 只需要根据数据集的大小和你拥有的计算资源来选择最合适的物理文件的数目大小.
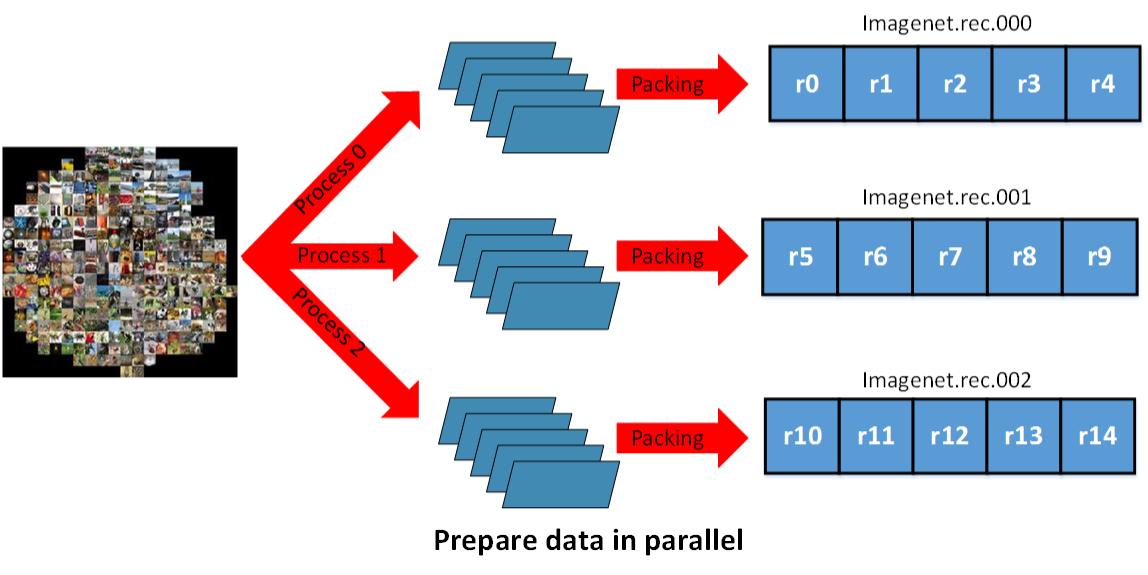 parellelprepare
parellelprepare
Data Loading and Preprocessing
当数据加载和数据预处理的速度无法赶上模型训练或者模型评估的速度, IO 就会成为整个系统的瓶颈. 在这部分, 我们将会介绍几个我们在追求数据加载和预处理的机制高效的过程中用到的几个技巧. 在我们的 ImageNet 的实践中, 我们使用普通的 HDD 可以获得 3000 image/s 的速度.
Loading and preprocessing on the fly
在训练深度神经网络的时候, 我们有时只能加载和预处理训练需要的一小部分数据, 主要是因为以下的原因:
- 整个数据集的大小已经超出了内存的大小, 我们不能提前将它们加载到内存中;
- 如果我们需要在训练的过程中引入随机性的话, 数据预处理的流水线可以在不同 epoch 中会对同一份数据产生不同的输出;
为了获得极致的高效性, 我们在相关的处理过程中引入了多线程技术. 拿 ImageNet 的训练过程作为例子, 当加载了一批数据之后, 我们使用了 多线程来做数据解码和数据扩充, 下面的图示清楚的说明了该过程:
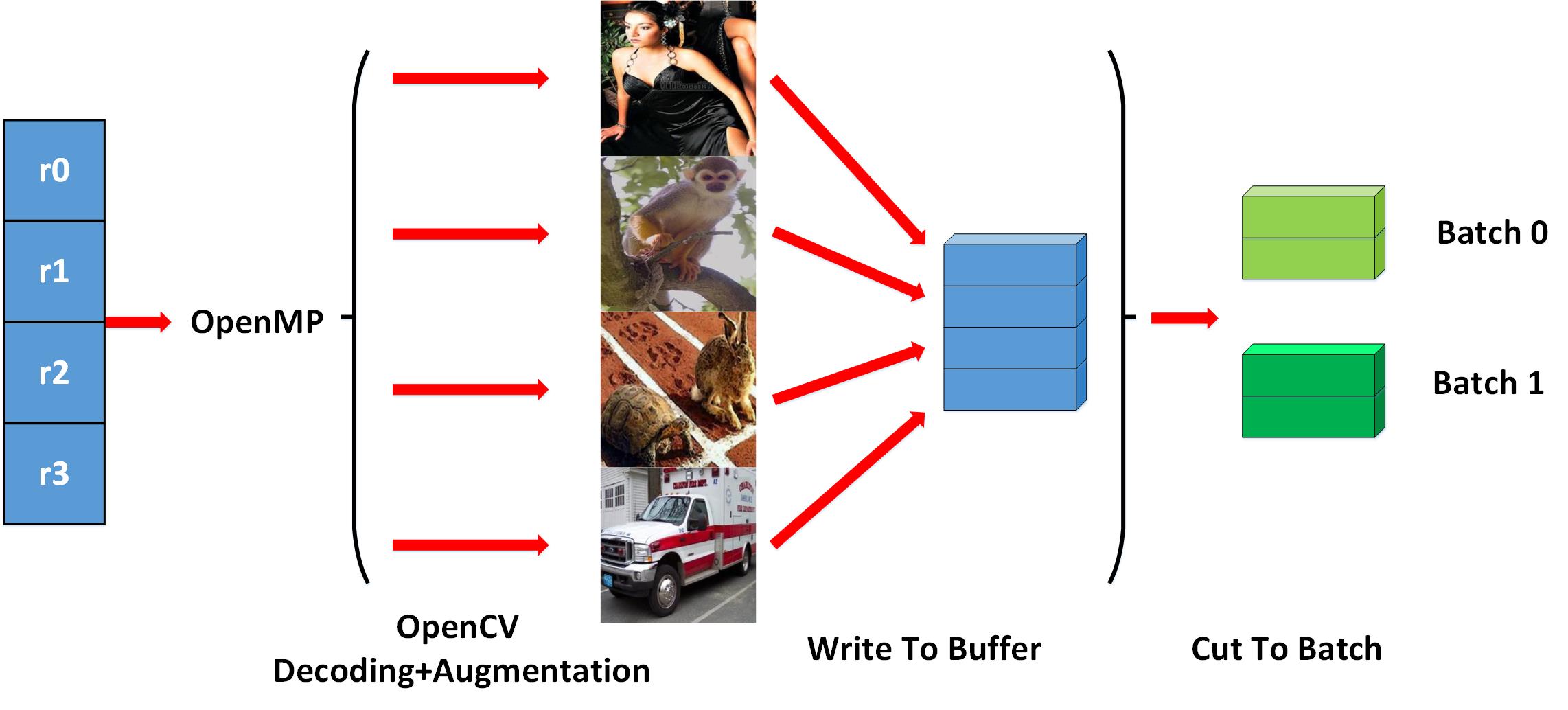 process
process
Hide IO Cost Using Threadediter
掩藏 IO 开销的一种方式是主线程在做 feed-forward 和 backward 的时候, 使用一个独立的现成做数据预取操作. 为了支持更加复杂的训练方案, MXNet 提供了基于 dmlc-core 的 threadediter 更加通用的 IO 处理流水线.
Threadediter 的重点是使用一个独立的线程作为数据提供者, 主线程作为数据消费者, 图示如下.
Threadediter 会持有一个确定大小的 buffer, 当 buffer 为空的时候会自动填满. 当作为数据消费者的主线程消费了数据之后, Threadediter 会重复利用这部分 buffer 来存储接下来要处理的数据.
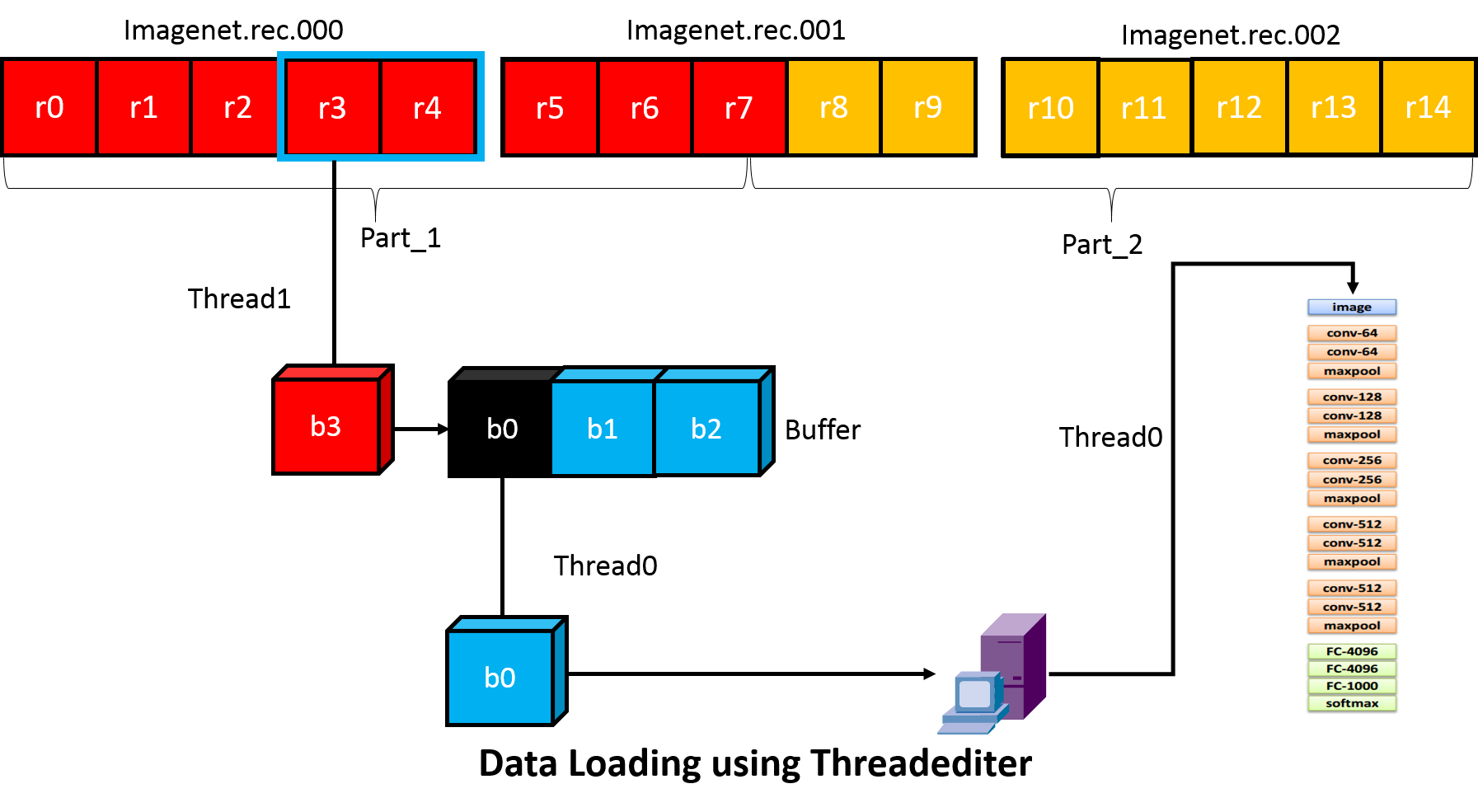 threadediter
threadediter
MXNet IO Python Interface
我们把 IO 对象看做 numpy 中的迭代器. 为了达到这一点, 用户可以 for 循环或者调用 next() 函数来读取数据. 定义一个数据迭代器和在 MXNet 中定义一个符号化 Operator 很相似.
下面的代码给出了创建一个 cifar 数据集的迭代器的例子.
dataiter = mx.io.ImageRecordIter(
# Dataset Parameter, indicating the data file, please check the data is already there
path_imgrec="data/cifar/train.rec",
# Dataset Parameter, indicating the image size after preprocessing
data_shape=(3,28,28),
# Batch Parameter, tells how many images in a batch
batch_size=100,
# Augmentation Parameter, when offers mean_img, each image will substract the mean value at each pixel
mean_img="data/cifar/cifar10_mean.bin",
# Augmentation Parameter, randomly crop a patch of the data_shape from the original image
rand_crop=True,
# Augmentation Parameter, randomly mirror the image horizontally
rand_mirror=True,
# Augmentation Parameter, randomly shuffle the data
shuffle=False,
# Backend Parameter, preprocessing thread number
preprocess_threads=4,
# Backend Parameter, prefetch buffer size
prefetch_buffer=1)
为了创建一个数据迭代器, 通常你要提供五个参数:
- Dataset Param 给出了数据集的基本信息, 比如, 文件路径, 输入 shape.
- Batch Param 给出组成一个 batch 需要的信息, 比如, batch size.
- Augmentation Param 告诉迭代器你在输入数据上进行的扩充操作 ( 比如, crop, mirror).
- Backend Param 控制后端线程行为的参数, 这些线程用来掩藏数据加载开销.
- Auxiliary Param 提供可选项来做 checking 和 debugging.
通常 Dataset Param 和 Batch Param 是 必须的参数. 其他参数可以根据算法和性能的需要来提供, 或者使用我们提供的默认值.
理想情况下, 我们应该将 MXNet 的数据 IO 分成几个模块, 其中一些可能暴露给用户是有好处的:
- Efficient prefetcher: 允许用户来写数据加载器代码来读取他们自定义的二进制格式, 同时可以自动的享受多线程数据预取的支持.
- Data transformer: 图像随机 cropping, mirroring, 等等. 如果允许用户使用这些工具或者加载他们自定义的转换器(可能用户想要添加一些随机噪音,等等)是非常有用的.
Future Extension
我们可能要记住的几个通用应用的 data IO: Image Segmentation, Object localization, Speech recognition. 当这些应用运行在 MXNet 上的时候, 我们会提供更多的细节.
Contribution to this Note
This note is part of our effort to open-source system design notes
for deep learning libraries. You are more welcomed to contribute to this Note, by submitting a pull request.


