浏览器渲染机制
1. 一些必要的背景知识
目前使用的主流浏览器有五个:Internet Explorer、Firefox、Safari、Chrome 浏览器和 Opera。本文中以开放源代码浏览器为例,即 Firefox、Chrome 浏览器和 Safari(部分开源)。根据 StatCounter 浏览器统计数据,目前(2017 年 3 月)Firefox、Safari 和 Chrome 浏览器的总市场占有率已达70%+。由此可见,如今开放源代码浏览器在浏览器市场中占据了非常坚实的部分。
浏览器的作用,从本质上来讲,就是响应请求,从服务器获取内容,然后通过浏览器窗口呈现给用户。获取的内容包括 HTML、CSS、JS,以及图片、文字、音频视频等内容信息。
浏览器的7大核心组成
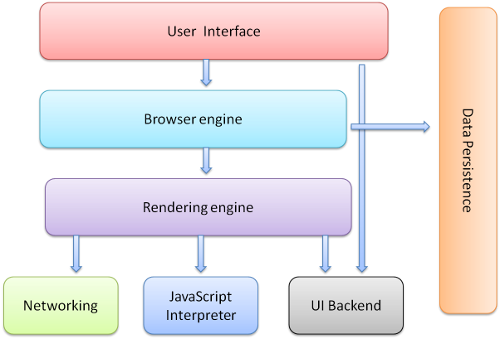
- 用户界面 - 包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
- 浏览器引擎 - 在用户界面和渲染引擎之间传送指令。
- 渲染引擎 - 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
- 网络 - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端 - 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
- JavaScript 解释器 - 用于解析和执行 JavaScript 代码。
- 数据存储 - 这是持久层。浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。
2. 现在让我们集中于“渲染引擎”
本文所讨论的浏览器(Firefox、Chrome 浏览器和 Safari)是基于两种渲染引擎构建的。Firefox 使用的是 Gecko,这是 Mozilla 公司“自制”的。Safari 和 Chrome 使用的是 WebKit。
WebKit 是一个开源渲染引擎,起初用于 Linux 平台,随后由 Apple 公司进行修改,从而支持苹果机和 Windows。详情参阅 webkit.org。
主流程
渲染引擎一开始会从网络层获取请求文档的内容,内容的大小一般限制在 8000 个块以内。然后会按照一个基本流程进行渲染:

- 渲染引擎解析 HTML 文档,形成一个“DOM(Document Object Model)”树,每个 HTML 标签都是一个 DOM 节点。
与此同时,渲染引擎也会解析 CSS 样式数据(包括内联及外部引入样式)。这些样式信息将会创建另一个树结构:CSSOM树。
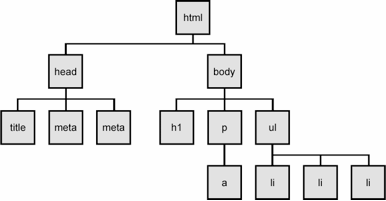
- 构建渲染树,Rendering Tree。

需要着重指出的是,这是一个渐进的过程。为达到更好的用户体验,渲染引擎会力求尽快将内容显示在屏幕上。它不必等到整个 HTML 文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,渲染引擎会将部分内容解析并显示出来。
渲染流程示例
WebKit 渲染流程

Mozilla 的 Gecko 引擎渲染流程

WebKit 和 Gecko 的整体渲染流程是基本相同,HTML+CSS 部分会有小的区别。
更加详细的内容,可以通过下面两篇文章,进一步了解。
参考:


