算法4(Algorithms4)- Part 1 算法分析(A

算法4(Algorithms4)- Part 1 算法分析(Analysis Of Algorithms)
注:由于简书不支持Latex语法,建议阅读此篇文章 。
本文分为5节,分别是:
- 介绍(introduction): 介绍算法分析的必要性和重要性
- 观察(observations): 通过分析一个经典问题 3 - SUM问题,逐渐引出算法分析的方法论
- 数学模型(mathematical models): 如何具体分析比较算法的优劣呢?我们需要对算法的运行时间进行分析并建立数学模型
- 增长级(order-of-growth classifications): 对算法运行时间进行分类
- 内存(memory): 算法使用了多大的内存?
本文贯穿始终的是3 - SUM 算法,其中也提到了二分查找(binary search)算法。
1. 介绍
1.1 人物介绍
在算法开发过程中,有这么几个角色
- 程序员(Programmer) : 需要开发出能解决问题的算法
- 用户(Client) : 想要高效的解决问题
- 理论家(Theoretician) : 想要搞清算法的原理
- *学生(Student) : 可能要扮演上述任一个角色

1.2 运行时间
1.3 为什么要分析算法?
- 可以对已知算法的性能进行预测
- 可以比较多个算法的优劣
- 可以对已知算法提供性能保证
- 可以理解基本的算法相关理论
本课会涉及前三点,后面的两点则是算法理论研究相关的方向。
基于实用性的原因:避免性能上的bug。
用户可能因为程序员不了解性能特性而获得很差性能的代码。
1.4 一些成功的算法
1. 离散傅里叶变换(Discrete Fourier transform)
- 将N个图样的波形分解成周期分量
- 应用 : DVD, JPEG, MRI(Magnetic Resonance Imaging, 核磁共振成像), 天体物理学...
- 暴力破解 : N ^ 2步
- FFT 算法 : N * log N 步, 使新技术成为可能
2. N体模拟(N - body simulation)
- 模拟N个物体间的引力相互作用
- 暴力破解 : N ^ 2
- Barnes-Hut算法(Barnes-Hut algorithm) : N * log N 步, 使新研究成为可能

1.5 我们面临的挑战
问题 : 我的算法能够解决大量的输入数据吗?
- 算法可能很慢
- 算法使用内存可能超标
如何对算法进行分析呢?
高德纳(Donald Knuth)在20世纪70年代提出: 使用 科学的方法(scientific methods) 来分析算法性能。

1. 应用于算法分析的科学方法
我们需要一个体系,满足以下两个条件:
- 可以预测算法的性能
- 能比较不同算法的优劣
2. 科学的方法
- 观察(Observe) : 观察自然界的特性
- 假设(Hypothesize) : 假设一个和观察结果一致的模型
- 预测(Predict) : 根据假设进行预测未发生的情况
- 验证(Verify) : 进行更多的观察,以此验证我们的预测
- 确认(Validate) : 不断重复上述过程,直到观察和假设能完全一致
3. 需要遵守的原则
- 实验必须可重复(reproducible)
- 假设必须可被明确检验对或者不对(falsifiable)
2. 观察
我们来看一个例子:3 - SUM问题。
2.1 3 - SUM问题
给出N个不同的整数,随机挑三个数构成一个组合,使这个组合中的三数之和为0, 这样的组合一共有多少个?

2.2 暴力破解
最容易想到的解法就是使用暴力算法,三个循环,遍历获取。代码如下:

如何判定这个实现好不好呢?我们需要计算它的运行时间。
1. 运行时间
如何获得运行时间呢?
- 使用秒表手动计时
- 使用
algs.jar中的Stopwatch类。
使用方法如下:

2. 数据分析
按照数据量从小到大排列,运行得出的时间:

使用标准坐标,将其坐标描点,用平滑曲线连接,如图所示。

使用纯对数坐标(Log-log图)。

通过对对数坐标的图进行观察,我们发现这条线近似直线。设其斜率为b,常数项为c。
得出方程:
lg(T (N)) = b lg N + c
解得常数项为:
b = 2.999
c = -33.2103
得出结论:
T (N) = a * N ^ b,其中 a = 2 c
假设 : 运行时间计算公式为(单位为s):
T(N) = 1.006 * 10 ^ 10 * N ^ 2.999
3. 预测和验证
根据上面假设的公式进行预测:
- N = 8000时, 时间为51s
- N = 16000时, 时间为408.1s
验证:

证实了假设是对的!
我们通过进一步观察发现,每当数据量翻倍时,其运行时间也呈规律性的变化。

每次运行时间与上次运行时间的比率ratio,其对2取对数,即 lg ratio 趋近于3。
根据这点,更进一步假设 :
T(N) = a * N ^ b, 其中 b = lg ratio
现在假设 b = 3, 从而求出a的值。

最终得出
T(N) = 0.998 × 10 ^ –10 × N ^ 3
事实上,这个公式和根据线性回归(linear regression)计算得出的公式相当相近了。
4. 在实践中影响算法表现的因素
不受外部系统影响的部分
- 算法
- 输入数据
受外部系统影响的部分
- 硬件(Hardware) : CPU, 内存, 缓存,...
- 软件(Software) : 编译器, 解释器, 垃圾回收(GC),...
- 系统(System) : 操作系统(OS), 网络, 其它应用,...
通过这节我们对3-SUM算法的暴力实现算法进行了分析,得出了一些简单的结论。能够根据公式,输入一定数量的数据,得出运行时间。
如何对其它更广泛的算法进行计算呢?我们需要对算法内部的代码进行更细致的分析。
3. 数学模型
3.1 运行时间的数学模型
给定一个算法,其总的运行时间T = 算法中每个具体操作耗费的时间T_i * 该操作出现的次数 n_i 之和。
我们需要知道以下几点:
- 需要对程序进行分析,以确认操作的次数
- 耗费时间取决于硬件和编译器
- 操作的次数取决于算法和输入的数据
大体上说, 精确的数学模型是十分有价值的。
1. 基本操作的时间

以上是常见数学计算的耗时。

以上是计算机语言中常见操作的耗时,c_i表示常数时间, N表示输入的数据量。
新手错误 : 滥用字符串连接(string concatenation),因为这和输入数据量成正比,我们应该追求更高效的做法。
接下来,我们看几个由3-SUM简化出的问题,逐步分析。
2. 例子: 1 - SUM问题
问题: 当输入的数据有N个时,需要操作多少步?

图中给出了各种必要的操作及其次数。
3. 例子: 2 - SUM问题
问题: 当输入的数据有N个时,需要操作多少步?

图中给出了各种必要的操作及其次数。
相比1 - SUM中的操作,2 - SUM中操作次数计算开始变得繁琐和难以计算。
3.2 简化计算
1. 耗费模型的简化

“ It is convenient to have a measure of the amount of work involved
in a computing process, even though it be a very crude one. We may
count up the number of times that various elementary operations are
applied in the whole process and then given them various weights.
We might, for instance, count the number of additions, subtractions,
multiplications, divisions, recording of numbers, and extractions
of figures from tables. In the case of computing with matrices most
of the work consists of multiplications and writing down numbers,
and we shall therefore only attempt to count the number of
multiplications and recordings. ” — Alan Turing
这是艾伦 图灵(Alan Turing)说过的一段话,大意是:
“测量计算过程中涉及的工作量是很方便的,尽管可能结果很粗糙。我们可以计算在整个过程中各种基本操作应用的次数,然后赋予它们各种权重。
例如,我们可以计算加法、减法、乘法、除法、记录数字和从表中提取数据的次数。在矩阵中计算的情况下,操作主要是由乘法和记录数字组成,因此我们只尝试计算乘法和记录的次数。”
其中最后一句话提到“只尝试计算乘法和记录的次数”,这为简化算法耗费时间的计算提供了思路。
例如刚才2-SUM问题中,我们只对关键操作的时间进行记录,而忽略其它操作的时间。

我们只记录访问数组的时间,其次数N (N - 1)。
2. 波浪线表示法
- 当输出个数为N时,估计函数的运行时间
- 忽略低阶项
- 当N很大时,低阶项微不足道
- 当N较小时,我们无需在意
| 式子 | 等价 |
|---|---|
| ⅙ N^3 + 20N + 16 | ~ ⅙ N^3 |
| ⅙ N^3 + 100 N^{4/3} + 56 | ~ ⅙ N^3 |
| ⅙ N^3 - ½ N^2 + ⅓ N | ~ ⅙ N^3 |
对于第三项来说,当N = 1000时, ½ N^2 + ⅓ N大概是500000(十万量级), 而⅙ N^3为166000000(亿量级),相比来说,忽略低阶项完全是说通的。
以下是2-SUM各项操作波浪线表示法得出的等价:

3. 例子: 2 - SUM问题
根据上面的方法进行简化,计算出时间。

得出结论:2-SUM问题的算法时间复杂度为 ~ N^2。
4. 例子: 3 - SUM问题
根据上面的方法进行简化,计算出时间。

得出结论:3-SUM问题的算法时间复杂度为 ~ {1/2} N^3。
5. 估计离散求和
问题:如何对离散值求和?
- 学习离散数学
- 使用微积分

理论中,精确的数学模型十分重要。
现实中,
- 方程可能很复杂
- 可能需要高等数学的知识
- 具体的数学模型还是留给专家吧!

我们需要的是一个大概的模型,例如:T(N) ~ c N^3
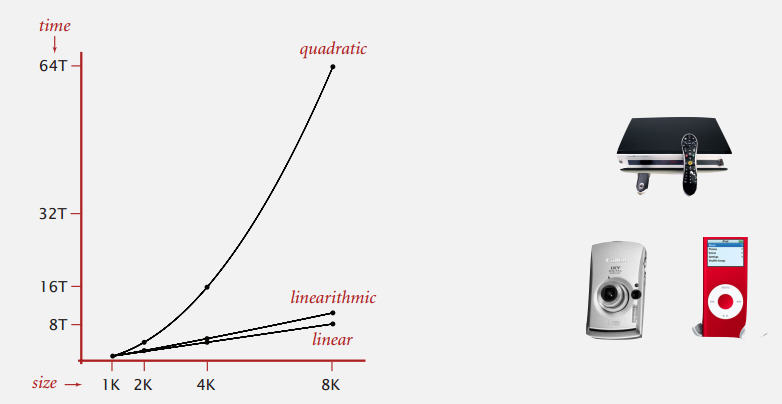
4. 增长级数分类(order-of-growth classifications)
4.1 常见的增长级数分类
常见的函数:1, log_2 N, N,N log_2 N, N^2, N^3 和 2^N
这些函数已经能足以描述常见算法的增长级数。(系数在此不做考虑)

下图是以上函数对应的常见算法。

实践中的增长级数

极限: 为了能摩尔定律(Moore's law)保持同步,我们需要线性(linear)或者线性对数级别(linearithmic)的算法。
4.2 二分查找
1. 目标
给定一个有序数组和其中的一个数,在数组中找到这个数的下标。
2. 二分查找
将此数和数组下标中点的数比较
- 给定的数太小,查找左边
- 给定的数太大,查找右边
- 相等的话,找到了

3. Java实现
这个问题的实现简单吗?
事实上
- 第一个二分查找算法于1946年发表;第一个没有bug的二分查找于1962年发表
- Java中的
Arrays.binarySearch()实现在2006年被发现有bug
提这些只是为了说明,正确的二分查找并没有想象中的简单..

如果key在数组a[]中,那么必有 a[lo] <= key <= a[hi]。
4. 数学分析
命题: 在长度为N的有序数组中进行二分查找,最多比较1 + lg N次。
证明:设T(N)为在长度为N的有序数组中进行二分查找时比较的次数。
易得T(1) = 1
N > 1时, T(N) = T(N / 2) + 1 (其中的1次是在和中点的数进行比较,T(N / 2)是之后左半部分或者右半部分进行比较)。
证明过程:
T (N) ≤ T (N / 2) + 1 // 小于等于是可能第一次比较就等于
≤ T (N / 4) + 1 + 1
≤ T (N / 8) + 1 + 1 + 1
. . .
≤ T (N / N) + 1 + 1 + … + 1 // 停止, 此时T(1) = 1
= 1 + lg N
4.3 3 - SUM算法的一个N ^ 2 log N 实现
基于排序的算法
- 步骤一: 对N个不同的数进行排序
- 步骤二: 对于每对
a[i]和a[j], 在数组中二分查找-(a[i] + a[j])

分析: 增长级为N ^ 2 log N。
- 步骤一: 插入排序(insertion sort) -- N ^ 2
- 步骤二: 二分查找(binary search) -- N ^ 2 log N
4.4 算法比较
假设: 对于3-SUM 问题的两个实现
- 基于排序的增长级为N ^ 2 log N的算法
- 暴力算法N ^ 3 算法
前者比后者要快。

事实证明, 增长级更好 => 速度更快
4.5 算法理论中常用的符号表示

其中有三种符号: Theta (N^2), O (N^2)和Omega (N^2)。
O 是用于描述函数渐近行为的数学符号。更确切地说,它是用另一个(通常更简单的)函数来描述一个函数数量级的渐近上界。
Omega 的定义与O 的定义类似,但主要区别是,O 表示函数在增长到一定程度时总小于一个特定函数的常数倍,Omega 则表示总大于,来描述一个函数数量级的渐近下界。
Theta 是O 和Omega 的结合,是用来定义一个函数的数量级。
常见错误时:使用O 表示近似时间模型。
本文使用波浪线~ (tlide notation)用来表示算法的近似时间模型。
5. 内存
5.1 基础
- 比特(Bit): 0 或 1
- 字节(Byte): 8个比特
- 兆(MB, Megabyte): 10 ^ 6或者2 ^ 20个比特
- 吉(GB, Gigabyte): 10 ^ 9或者2 ^ 30个比特
64-bit计算机:其中指针长度为8bytes
- 可以为更大的内存提供地址
- 指针消耗内存更多(一些JVM会“压缩”对象指针到4字节以节省内存)
5.2 基本数据类型和数组的内存占用

5.3 Java中对象的内存占用
- 对象头(Object overhead): 16bytes
- 引用(Reference): 8bytes
- 对齐填充(Padding): 每个对象使用内存均为8bytes的整数倍
例1: 一个Date对象使用32bytes的内存

例2:一个长度为N的String类使用N ~ 2N bytes的内存

5.4 总结
各种数据类型的内存使用
- 基本数据类型(primitive type): int型 4bytes, double型 8bytes
- 对象引用(object reference): 8bytes
- 数组(array): 24bytes + 每个数组成员的内存 + 8bytes(如果有内部类的话, 指向内部类的指针)
- 对齐(padding): 为了让对象长度为8bytes的整数倍
浅层次内存的计算: 不计算引用对象
深层次内存的计算: 如果数组成员是一个对象引用, 需要将引用的对象内存也计算在内
举例: 一个WeightedQuickUnionUF对象,其中数据长度为N, 计算其对象大小

其大小为 8 N + 88 ~ 8 N bytes。
参考网址
[1] Algorithms4
[2] 大O符号/大Ω符号/大Θ符号/小o符号/小w符号等各种算法复杂度记法含义
[3] Markdown中插入数学公式的方法
[4] MathJax basic tutorial and quick reference


