简年就要收简红包 ·互联网金融之量化投资深度文本挖掘
 陈小米
陈小米 · 7 个月前
一、 功能概述
关键词词频&网络图是以股票论坛、 个股新闻、研究报告三个网站作为数据源,以文本数据挖掘作为核心技术,以 Lucene 检索作为系统框架, 以证券分析为目的, 实现的智能文本分析系统,该系统主要实现了以下功能:
关键词词频统计
关键词网络图
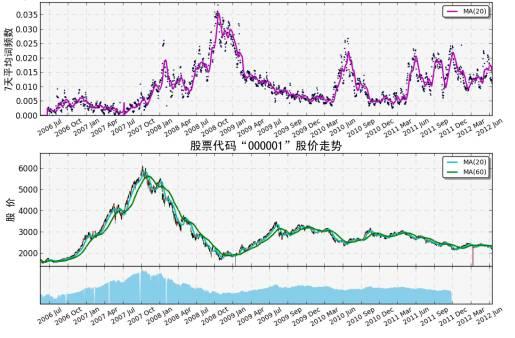
其中,关键词词频统计功能是: 对于给定的关键词(Word)以及给定的股票代码(Ticker)在一定的时间范围[StartDate,EndDate]内,计算每周的平均词频占比, 同时给出该词频占比时间序列与股价之间的相关系数。
 关键词网络图的功能是: 对于给定的关键词(Word)在一定的时间范围[StartDate,EndDate]内,根据 TF-IDF 关联度指标为依据,给出与关键词最相关的 20 个一级词,以及与一级词最相关的 5 个二级词,组成关键词网络图。
关键词网络图的功能是: 对于给定的关键词(Word)在一定的时间范围[StartDate,EndDate]内,根据 TF-IDF 关联度指标为依据,给出与关键词最相关的 20 个一级词,以及与一级词最相关的 5 个二级词,组成关键词网络图。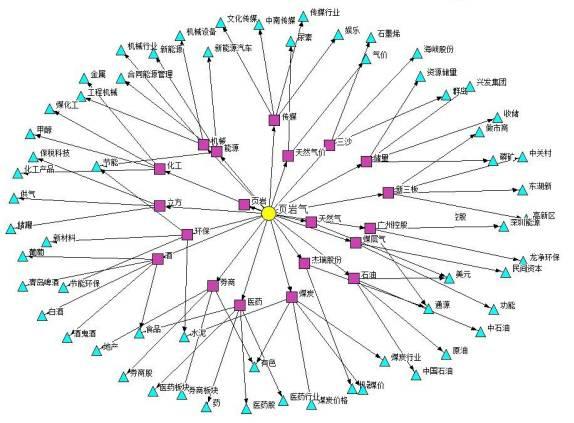 二、功能模块
二、功能模块如本文之前所述, 本文分析系统的两个功能是建立在三个文本的数据源,Lucene 检索的架构之上的。 所以,实现关键词词频、关键词网络图的功能需要先做一些准备工作和模块支持, 本文所实现的智能文本分析系统主要分为以下几个模块:
爬虫模块
检索模块
统计模块
关键词词频模块
关键词网络模块
1) 爬虫模块
爬虫模块的主要作用在于将股票论坛、 个股新闻、研究报告三个网站的网页数据通过网页解析的方式将文本内容爬下来, 用于之后模块的文本挖掘。 爬虫模块将爬到的文本数据以【 日期 + 股票代码】 为单位存至相应的 TXT 文本文件当中,同时将文本文件所在的位置以及其他相关信息写入数据库。对于每个数据源,都有一个独立的程序进行网页爬虫,他们分别是:▲GetGuba_pylucene.py股票论坛网页爬虫▲GetMbReport_pylucene.py研究报告网页爬虫▲GetSinaNews_pylucene.py个股新闻网页爬虫
2) 检索模块
检索模块的主要作用在于以 Lucene 为架构, 将爬虫模块爬到的文本数据加入到全文索引当中, 在建立索引的过程中,系统以“句子”作为基本的检索单位即检索关键词能够定位到该关键词所在的句子。 另外, 索引采用增量的方式来建立,即每次只将最新爬的文本加入到搜索索引当中, 而对于三个数据源,系统分别建立了三个独立的索引。同时,在建立的索引的基础上, 检索模块还实现了基本的文本检索功能, 检索程序能够在一定的时间范围内对于检索给定关键词,并返回该关键词所在的存储文件的文件名,以及该关键词所在的“句子”,并将所有的检索结果输出到一个给定的文件中。
简而言之,检索模块提供了建立索引和文本搜索两个主要的功能,他们分别是:
▲IndexFiles_pylucene.py增量建立索引▲SearchFiles_pylucene.py 关键词全文检索
3) 统计模块
设计统计模块是为了随后的关键词词频和网络模块进行数据的准备,和爬虫模块和检索模块一样,统计模块也是基础模块。 统计模块的主要功能有三个:▲ 以【用户字典】为列表,计算用户字典中每个关键词在三个数据源中出现的总词频数▲ 以【用户字典】为列表,计算用户字典中每个关键词在三个数据源中出现过的总文档数▲ 以句子为单位,计算三个数据源中每天文档的总句子数其中,用户字典关键词的词频数和文档数,是为了关键词网络模块中计算TF-IDF 相关度指标所准备的数据,而每天的句子数则树为了关键词词频模块中计算词频占比所准备的数据。对于统计模块的这三个功能,分别有三个独立的程序进行,他们分别是:
▲IDFCalWord.py 计算关键词总词频数▲IDFCal.py 计算关键词所在文档数
▲SentenceCal.py计算每天文档的句子数
4) 关键词词频模块
通过建立三个基础模块,能够完成一系列的应用,关键词词频模块是其中的一个应用模块, 关键词词频模块的主要功能在于:对于给定的关键词以及给定的股票代码,在一定的时间范围内,计算每周的平均词频占比,给出词频占比序列的曲线和股票价格曲线的对比图,同时给出该词频占比与股价之间的相关系数。模块中没有直接使用关键词每天的词频,而是根据每天的词频,以及当天文档的句子总数计算关键词的词频占比。 对于关键词 ,词频占比的计算公式如下:
 其中, 公式的各个指标的意义如下:分子: 概念关键词 在第 i 天出现的次数
其中, 公式的各个指标的意义如下:分子: 概念关键词 在第 i 天出现的次数分母: 第 i 天中文档的句子总数
从词频占比的计算公式可以看出,词频占比是将每个星期的关键词的词频总和除以每个星期文档的句子总数得到的。使用词频占比而非直接采用词频,能够更公平地反应出关键词 每天的关注程度,从而更合理地对词频信号进行使用。另外,在计算关键词与给定股票的相关系数时,模块会以一周为频率计算关键词的词频占比时间序列,同时计算该周内给定股票股价的均值,计算两个时间序列的相关系数作为两者相关性的依据。
对于关键词词频模块,只有一种调用的方式,调用时需给出关键词、股票代码以及时间范围:
▲*** sigWordSeq.py关键词词频时间序列
5) 关键词网络模块
和关键词词频模块一样,关键词网络模块也属于应用模块,关键词网络模块的主要功能在于:对于给定的关键词、在一定的时间范围内,根据TF-IDF关联度指标为依据,给出与关键词最相关的20个一级词,以及与一级词最相关的5个二级词,组成关键词网络图。其中关联度指标采用的是TF-IDF算法,TF-IDF是一种常用的文本检索与本文探勘的加权技术,主要用于评估某个词对于一份特定文档的重要程度。在本文的关键词网络模块中,将给定关键词的搜索结果集合作为特定文档,TF-IDF用于评估搜索结果中每个词对于该结果的关联程度,即对于关键词的关联程度。TF-IDF的具体计算公式如下:
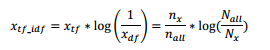 其中 x 为搜索结果中的某个词,为词 x 的与关键词的TF-IDF关联度指标,其他符号意义如下:
其中 x 为搜索结果中的某个词,为词 x 的与关键词的TF-IDF关联度指标,其他符号意义如下: 对于关键词网络模块,提供了两种形式的调用,一是对于给定的关键词,生成完整的关键词网络图,二是对于只给出与关键词关联度最高的20只股票组合,他们分别是:
对于关键词网络模块,提供了两种形式的调用,一是对于给定的关键词,生成完整的关键词网络图,二是对于只给出与关键词关联度最高的20只股票组合,他们分别是:▲ WordNet.py 完整关键词网络图▲ WordNet_stock.py 关键词关联股票组合
三、 模块运行
1) 爬虫模块举例2个,其余不再呈现
路径: D:\TotalCode\LuceneCode\GetData\GetGuba_pylucene.py功能: 股票论坛网页爬虫输入参数:无运行举例: python GetGuba_pylucene.py运行过程实例:
 运行结果:
运行结果: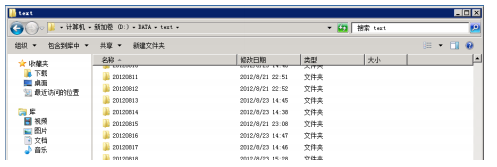 路径:D:\TotalCode\LuceneCode\GetData\GetSinaNews_pyl功能: 个股新闻网页爬虫
路径:D:\TotalCode\LuceneCode\GetData\GetSinaNews_pyl功能: 个股新闻网页爬虫输入参数:无
运行举例: python GetGuba_pylucene.py
运行过程实例:
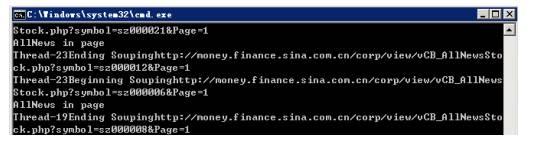 运行结果:
运行结果: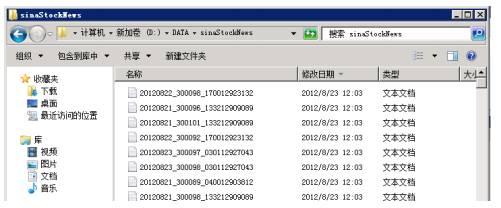 2) 检索模块*
2) 检索模块*路径: D:\TotalCode\LuceneCode\Index_Search\IndexFiles_pylucene.py功能: 增量建立索引输入参数:<数据目录> <索引目录> <开始日期> <结束日期>运行举例:python IndexFiles_pylucene.py D:\DATA\text D:\DATA\Index\text20120715 20120820
运行过程实例:
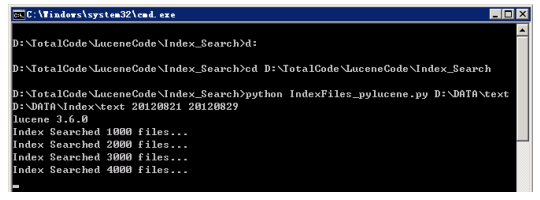 运行结果:
运行结果: 路径: D:\TotalCode\LuceneCode\Index_Search\SearchFiles_pylucene.py功能: 关键词全文检索输入参数:<索引目录> <关键词> <输出文件>运行举例:python SearchFiles_pylucene.py D:\DATA\Index\text "页岩气 "
路径: D:\TotalCode\LuceneCode\Index_Search\SearchFiles_pylucene.py功能: 关键词全文检索输入参数:<索引目录> <关键词> <输出文件>运行举例:python SearchFiles_pylucene.py D:\DATA\Index\text "页岩气 "D:\TotalCode\LuceneCode\Index_Search\Output_pylucene.txt
运行过程实例:
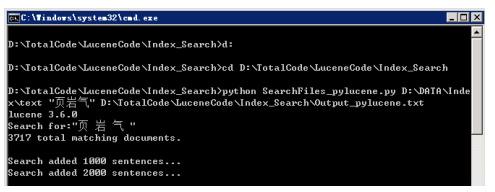
 3)统计模块举例1个,其余不再呈现
3)统计模块举例1个,其余不再呈现路径: D:\TotalCode\LuceneCode\ICTCLAS_Cal/IDFCal.py功能: 计算关键词所在文档数输入参数:<数据源> <开始日期> <结束日期>运行举例:python IDFCal.py 股票论坛 20120715 20120820运行过程实例:
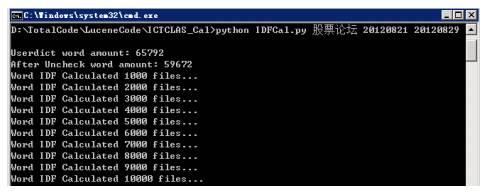 运行结果:
运行结果: 4)关键词词频模块举例1个,其余不再呈现
4)关键词词频模块举例1个,其余不再呈现路径:*** D:\TotalCode\LuceneCode\ICTCLAS_ IDF/ sigWordSeq.py功能: 关键词词频时间序列输入参数:<数据源> <关键词> <股票代码> <开始日期> <结束日期> <是否搜索标识>运行举例:python sigWordSeq.py 股票论坛 "物联网" 000001 20100601 20120820 1运行过程实例:
 运行结果:
运行结果: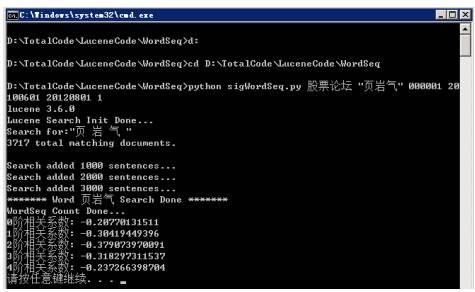 路径:D:\TotalCode\LuceneCode\ICTCLAS_ IDF/ WordNet.py功能: 完整关键词网络图输入参数:<数据源> <关键词> <开始日期> <结束日期>运行举例:python WordNet.py 研究报告 "页岩气" 20120601 20120817*
路径:D:\TotalCode\LuceneCode\ICTCLAS_ IDF/ WordNet.py功能: 完整关键词网络图输入参数:<数据源> <关键词> <开始日期> <结束日期>运行举例:python WordNet.py 研究报告 "页岩气" 20120601 20120817*运行过程实例:
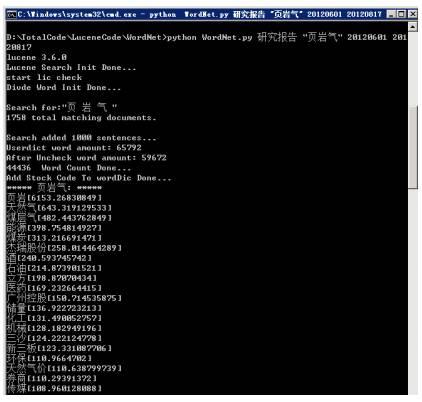 运行结果:
运行结果: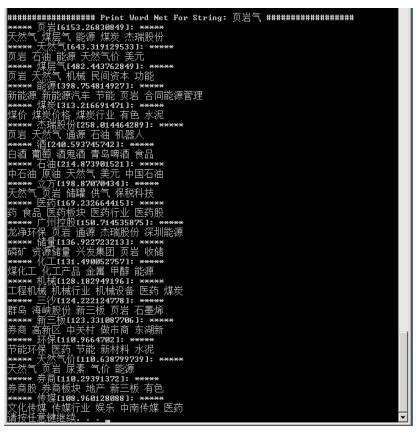 四、模块效率性能总汇
四、模块效率性能总汇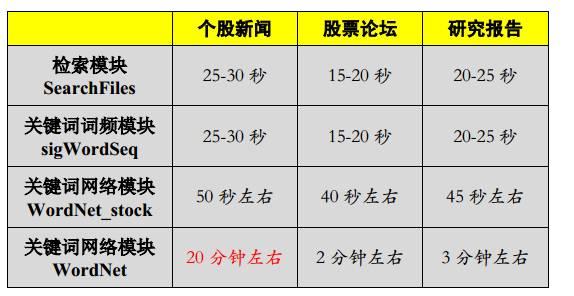 根据上表所示的各模块平均时间效率估计的结果,可以得到如下结论:▲ 在三个数据源中,所有模块个股新闻的平均运行时间是最长的,研究报告次之,而股票论坛是耗时最少的▲ 所有模块的时间消耗主要都关键词的搜索上,模块的平均耗时和模块进行的关键词搜索次数成正比▲ 关键词词频模块 sigWordSeq 进行了一次词频检索,因此和检索模块SearchFiles 的平均耗时相当▲ 关键词网络模块 WordNet_stock 同样只进行了一次关键词检索,但是在计算关联股票TF-IDF 指标是需要耗费一定的时间,因此平均耗时略长于单次的检索
根据上表所示的各模块平均时间效率估计的结果,可以得到如下结论:▲ 在三个数据源中,所有模块个股新闻的平均运行时间是最长的,研究报告次之,而股票论坛是耗时最少的▲ 所有模块的时间消耗主要都关键词的搜索上,模块的平均耗时和模块进行的关键词搜索次数成正比▲ 关键词词频模块 sigWordSeq 进行了一次词频检索,因此和检索模块SearchFiles 的平均耗时相当▲ 关键词网络模块 WordNet_stock 同样只进行了一次关键词检索,但是在计算关联股票TF-IDF 指标是需要耗费一定的时间,因此平均耗时略长于单次的检索▲ 关键词网络模块 WordNet 由于需要进行对20个一级词的搜索,因此耗费的时间是最长的。另外,由于三个数据源中【 个股新闻】的数据量最大,运行 WordNet 一旦遇到高频词会消耗大量的时间,需要格外注意。
本文基于光大文本挖掘系统框架概述全文。
关注同名微信公众号:神秘的宽客们,回复【文本挖掘】获取链接与代码附录


