吴恩达机器学习笔记-反向传播算法练习
直观感受反向传播的概念
上篇文章讲述了神经网络的反向传播算法的基本概念,现在来详细的对此算法进行一些讲解。
回忆一下神经网络的代价函数:

如果我们只考虑一个简单的只有一个输出单元的情况,即k=1,那么代价函数则变成:

直观的说,项表示在第l层中第j个单元的误差。更正式的说,
的值实际上是代价函数的导数。
由于函数的导数即是其切线的斜率,因此其切线越陡则说明计算的误差越大。每一个神经元的误差都与后面连接的神经元有关,如下图计算:
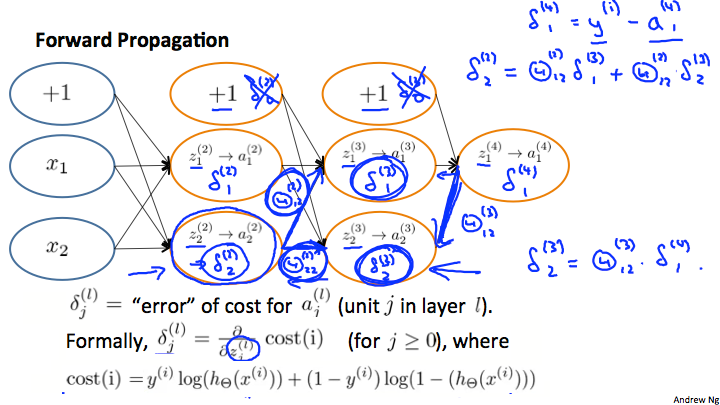
其中:
参数展开
使用神经网络时,我们处理的一组矩阵:,
,
...,为了使用最优化函数比如"fminuc()",我们需要将所有的元素展开将其放入一个长向量中:
比如说如果Theta1的维度是1011,Theta2是1011,Theta3是1*11,那我们通过展开后的向量来得到原始的矩阵的话,需要如下的方法:
总结的话就直接看吴恩达老师的笔记:

梯度校验
梯度校验是用来确保我们做的反向传播算法是否正确,这里假设代价函数的导数为:
那么在多个的矩阵,则可以得到下面近似于关于
的导数:
一般取比较合适,太小了会导致一些计算问题。因此我们只是在
矩阵中加上或减去
,在octave中代码如下所示:
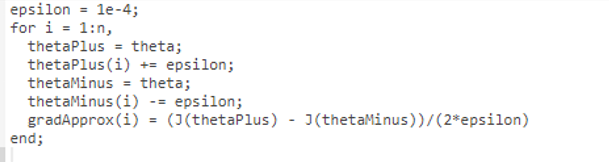
我们已经计算过deltaVector,因此计算出gradApprox后就可以判断是否gradApprox ≈ deltaVector。一旦计算出反向传播算法是准确的,就不需要再继续计算gradApprox了,因为计算gradApprox的过程是很缓慢的。
随机初始化参数
将所有的权重初始化为0不适用于神经网络,那样反向传播时,所有节点将重复更新为相同的值。因此,我们可以使用以下方法随机初始化我们的Θ矩阵的权重:

因此,这里初始化每个为
之间的随机值,使用上述公式保证我们得到所需的界限,相同的程序使用于所有的
。以下代码可以用来进行实验:(Theta1,Theta2,Theta3的维度同上面一样,这里的epsilon和上面梯度校验的无关):
Theta1 = rand(10,11) * (2*INIT_EPSILON) - INIT_EPSILON;
Theta2 = rand(10,11) * (2*INIT_EPSILON) - INIT_EPSILON;
Theta3 = rand(1,11) * (2*INIT_EPSILON) - INIT_EPSILON;
总结
这里就直接使用原课程的笔记,懒得写了,写了也只是把这个翻译一遍不如直接看原版笔记。这一周的内容的确有点难度了,需要一定时间消化。
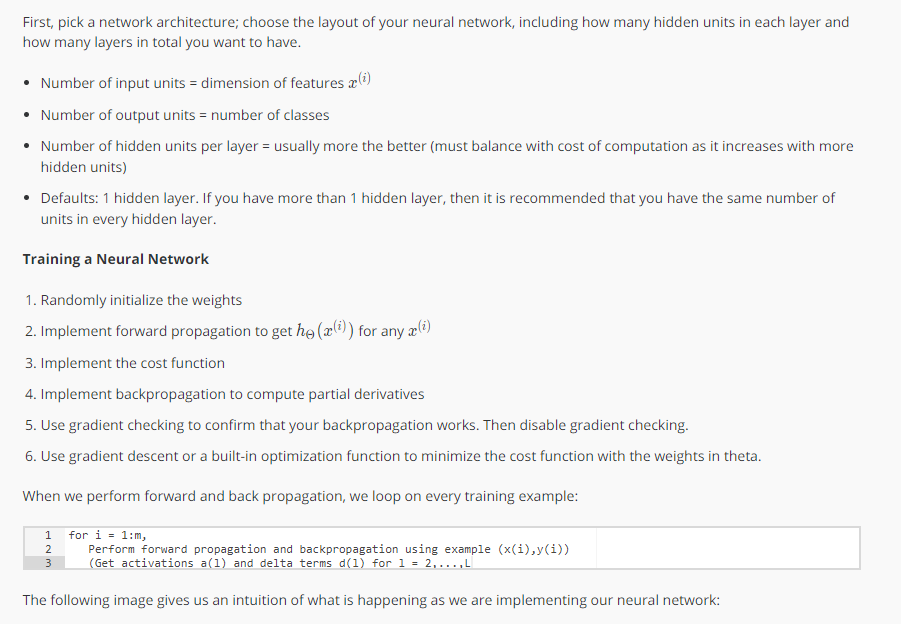
以上,为吴恩达机器学习第五周后半部分内容。


