WebAssembly 系列(三)编译器如何生成汇编
作者:Lin Clark
编译:胡子大哈
翻译原文:http://huziketang.com/blog/posts/detail?postId=58c55a3ba6d8a07e449fdd23
英文原文:A crash course in assembly
** 转载请注明出处,保留原文链接以及作者信息**
本文是关于 WebAssembly 系列的第三篇文章。如果你没有读先前文章的话,建议先读这里。如果对 WebAssembly 没概念,建议先读这里(中文文章)。
理解什么是汇编,以及编译器如何生成它,对于理解 WebAssembly 是很有帮助的。
在上一篇关于 JIT 的文章中,我介绍了和计算机打交道,就像同外星人打交道一样。

现在来思考一下“外星人”的大脑是如何工作的——机器的“大脑”是如何对我们输入给它的内容进行分析和理解的。
“大脑”中,有一部分负责思考——处理加法、减法或者逻辑运算。还有其他的部分分别负责短暂记忆和长期记忆的。
这些不同的部分都有自己的名字:
- 负责思考的部分叫做算数逻辑单元(ALU)
- 寄存器提供短暂记忆功能
- 随机存取存储器(RAM)提供长期记忆功能
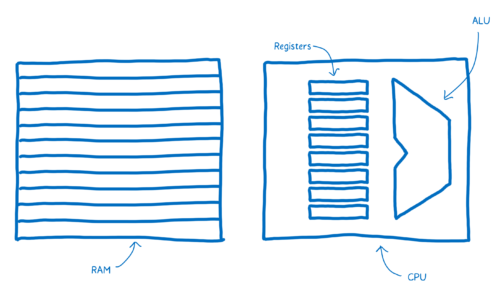
机器代码中的语句称作指令。
那么在指令进入“大脑”以后都发生了什么呢?它们会被切分为不同的部分传送到不同的单元进行处理。
“大脑”切分指令通过不同连接线路进行。举个例子,“大脑”会将指令最开始的 6 比特通过管道送到 ALU 中。而 ALU 会通过 0 和 1 的位置来决定对两个数做加法。
这串 01 串就叫做“操作码”,它告诉了 ALU 要执行什么样的操作。
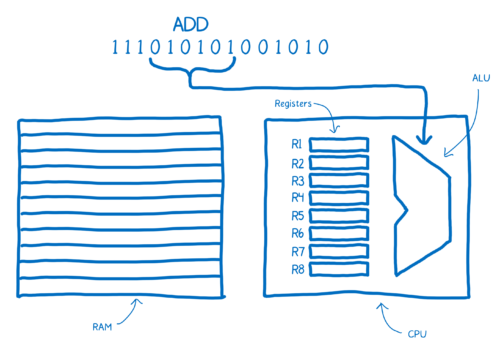
然后“大脑”会取后面两个连续的 3 比特 01 串来确定把哪两个数加到一起,而这 3 比特指的是寄存器的地址。
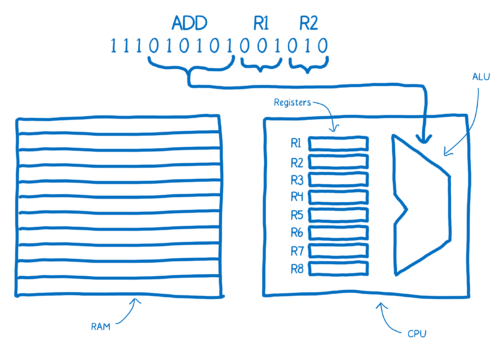
注意看上面机器码的注释:“ADD R1 R2”,这对于人类来讲很容易理解其含义。这就是汇编,也叫符号机器码,它使人类也能看懂机器代码的含义。
可以看到汇编和这台机器的机器码之间有直接的映射关系。正是因为如此,拥有不同机器结构的计算机会有不同的汇编系统。如果你有一个机器,它有自己的内部结构,那么它就需要它所独有的汇编语言。
从上面的分析可以知道我们进行机器码的翻译并不是只有一种,不同的机器有不同的机器码,就像我们人类也说各种各样的语言一样,机器也“说”不同的语言。
人类和外星人之间的语言翻译,可能会从英语、德语或中文翻译到外星语 A 或者外星语 B。而在程序的世界里,则是从 C、C++ 或者 JAVA 翻译到 x86 或者 ARM。
你想要从任意一个高级语言翻译到众多汇编语言中的一种(依赖机器内部结构),其中一种方式是创建不同的翻译器来完成各种高级语言到汇编的映射。
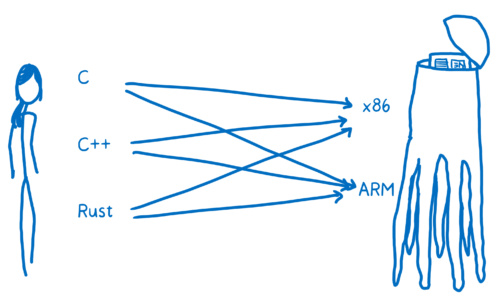
这种翻译的效率实在太低了。为了解决这个问题,大多数编译器都会在中间多加一层。它会把高级语言翻译到一个低层,而这个低层又没有低到机器码这个层级。这就是中间代码( intermediate representation,IR)。
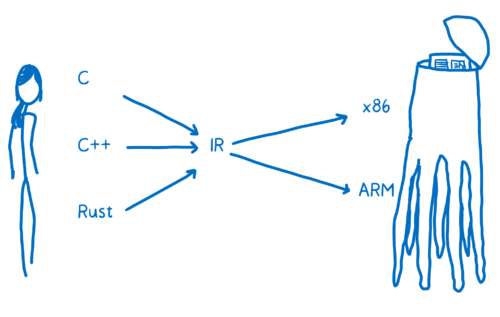
这就是说编译器会把高级语言翻译到 IR 语言,而编译器另外的部分再把 IR 语言编译成特定目标结构的可执行代码。
重新总结一下:编译器的前端把高级语言翻译到 IR,编译器的后端把 IR 翻译成目标机器的汇编代码。
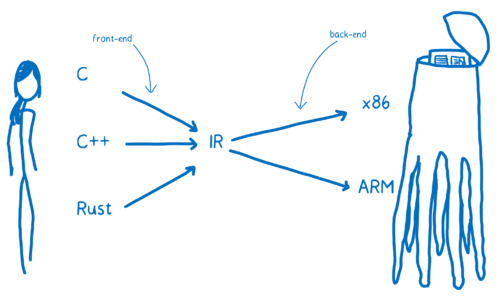
总结
本文介绍了什么是汇编以及编译器是如何把高级语言翻译成汇编语言的,在下一篇文章中,我们来介绍 WebAssembly 的工作原理。
我最近正在写一本《React.js 小书》,对 React.js 感兴趣的童鞋,欢迎指点。


