SpringBoot第二讲利用Spring Data JPA实现
在基本了解了springboot的运行流程之后,我们需要逐个来突破springboot的几个关键性问题,我们首先解决的是springboot访问数据库的问题。java访问数据库经历了几个阶段,第一个阶段是直接通过JDBC访问,这种方式工作量极大,而且会做大量的重复劳动,之后出现了一些现成的ORM框架,如Hibernate、Mybatis等,这些框架封装了大量的数据库的访问操作,但是我们依然要对这些框架进行二次封装。如今Spring Data帮助我们解决了数据库的操作的问题,Spring Data还提供了一套JPA接口帮助我们可以非常简单实现基于关系数据库的访问操作。如下图所示:
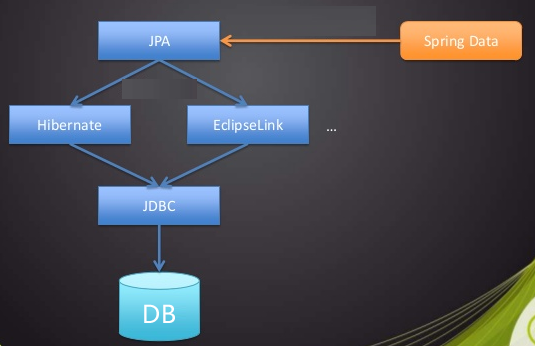 利用spring DATA JPA实现数据库访问
利用spring DATA JPA实现数据库访问
Spring Data JPA等于在ORM之上又进行了一次封装,但具体的对数据库的访问依然要依赖于底层的ORM框架,Spring Data JPA默认是通过Hibernate实现的,接下来我们就来看看Spring Data JPA如何访问我们的数据库和如何简化我们的操作的。
第一步创建一个Springboot的项目,并且添加Spring Data JPA的支持
这个操作可以直接在start.spring.io网站中创建,并且添加JPA的支持。这个项目我们可以考虑不使用Web。
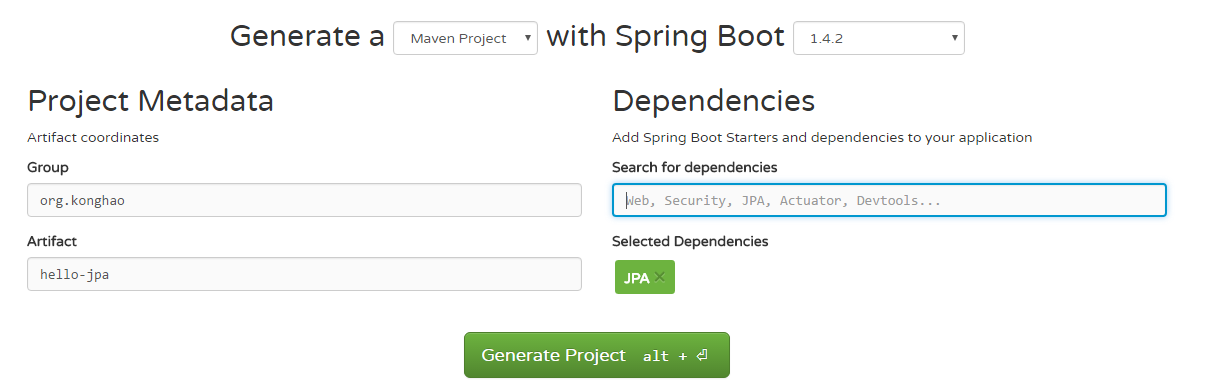 利用spring DATA JPA实现数据库访问
利用spring DATA JPA实现数据库访问
之后创建一个项目,拷贝maven的依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.konghao</groupId>
<artifactId>hello-jpa</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.4.2.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- spring data jpa的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>
pom.xml设置完成之后,我们会发现依赖包中有了hibernate的jar文件,这就说明spring data jpa默认就是使用hibernate框架来作为底层的ORM。
为了可以相对快速的上手spring Data,我们这里就创建一个Student的Model对象。
//Student
*/
/*
* 以下两个代码其实就是Hiberate声明实体的annotation
* */
@Entity
@Table(name="t_stu")
public class Student {
@Id()
@GeneratedValue(strategy = GenerationType.AUTO)
private int id;
private String name;
private String address;
private int age;
....
}
以上代码我省略其中的getter和settter方法,创建完实体类之后,这个实体类上的annotation都是原来hibernate中常用的,就不一一讲解了。之后在resources文件夹中配置appication.properties文件,这是springboot的主配置文件,此时我们配置和数据库访问相关的内容,我们使用的是hibernate,所以就配置和hibernate相关的内容
#开启包的自动扫描
entitymanager.packagesToScan= org.konghao.model
# 数据库连接
spring.datasource.url=jdbc:mysql://localhost:3306/springboot
# 用户名
spring.datasource.username=root
# 密码
spring.datasource.password=123456
# 数据库驱动
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
# 自动更新表
spring.jpa.properties.hibernate.hbm2ddl.auto=update
# 使用MYSQL5作为数据库访问方言
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5Dialect
#显示sql语句
spring.jpa.properties.hibernate.show_sql=true
注意原来和hibernate的配置都改成了以spring.jpa.properties.hiberate.xx,此时由于使用了mysql,所以还得导入mysql的connector
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
有没有发现我们不用设置版本,由于继承了org.springframework.boot,它会自动帮助我们匹配一个合适的connector来项目中的。到此和数据库配置相关的所有任务就结束了。
接下来就让我们开始访问数据库吧,在原来的方式中,我们需要为每一个对象创建自己的DAO接口,然后写一个实现类基础我们自己封装好的BaseDao,然后完成数据对象的CRUD等操作,如今Spring Data JPA帮我们完成了这个工作,我们首先看一下Spring Data JPA中的几个接口
 利用spring DATA JPA实现数据库访问
利用spring DATA JPA实现数据库访问
最高层的Repository<T,ID>是一个空接口,我们定义的数据访问类只要实现或者继承这个接口,这个数据访问类就可以被spring data所管理,就此可以使用spring为我们提供操作方法(在原来的spring data中我们需要配置很多和Spring Data Repository相关的设置,但是现在有了spring boot,全部都已经自动配置好了)。这个接口要实现有两个泛型参数,第一个T表示实体类,第二个表示主键的类型,我们写一个数据库访问接口。
public interface StudentRepository extends Repository<Student,Integer> {
@Query("select s from Student s where s.id=?1")
public Student loadById(int id);
//根据地址和年龄进行查询
public List<Student> findByAddressAndAge(String address, int age);
//根据id获取对象,即可返回对象,也可以返回列表
public Student readById(int id);
//根据id获取列表,这里如果确定只有一个对象,也可以返回对象
public List<Student> getById(int id);
//根据id获取一个对象,同样也可以返回列表
public Student findById(int id);
}
这个接口实现了Repository接口,我们定义了两个方法,这两个方法代表Repository使用的一种基本方法,第一个方法增加了一个Query的annotation,通过这个声明,Spring Data JPA就知道该使用什么HQL去查询数据,?1表示用方法中的第一个参数。第二个函数我们并没有定义任何的Annotation,但是它也可以查询得出来,在Spring Data JPA中提供了一种衍生查询,只要函数的声明有findBy,getBy,readBy,他就会去读取,findByAddressAnAge表示根据address和age进行查询,方法的第一个参数就是address,第二个参数就是age,readByXX,getByXX都是一样的道理,这些方法的返回值可以是一个列表,也可以是一个对象,spring Data JPA会自动根据返回类型来进行处理。我们不用写实现类,Spring Data JPA会自动帮助我们实现查询。很多时候在项目中会用到这些简单的查询,但是不得不写个方法来实现,但是现在使用了Spring Data JPA之后,这个操作被完全简化了。接着看一下测试类的实现。
@RunWith(SpringRunner.class)
@SpringBootTest
public class DemoApplicationTests {
//注入刚才定义的接口
@Autowired
private StudentRepository studentRepository;
@Test
public void testStudent() {
Assert.assertEquals("foo",studentRepository.findById(1).getName());
Assert.assertEquals("foo",studentRepository.readById(1).getName());
Assert.assertEquals(1,studentRepository.getById(1).size());
Assert.assertEquals("foo",studentRepository.loadById(1).getName());
Assert.assertEquals(2,studentRepository.findByAddressAndAge("zt",22).size());
}
}
现在应该对Spring Data JPA有了基本了解了吧,我们再看看刚才那张图,CRUDRepository实现了CRUD的方法,PagingAndSortingRepository在CRUD的基础上扩展了分页和排序的功能,而JpaRepository同样扩展了一些方法方便我们查询。
我们先看看CRUDRepository这个接口,这个接口里面提供了CRUD的基本操作,使用非常的简单。
public interface StudentCrudRepository extends CrudRepository<Student,Integer>{
//增加了一个countByXX的方法
public long countByAge(int age);
}
测试代码
@Test
public void testAddStudent() {
//添加操作
Student stu = new Student("foo1","km",22);
studentCrudRepository.save(stu);
}
@Test
public void testUpdateStudent() {
/*修改的操作*/
Student stu = studentCrudRepository.findOne(1);
stu.setName("bar1");
studentCrudRepository.save(stu);
}
@Test
public void testDelete() {
//删除操作
studentCrudRepository.delete(1);
}
@Test
public void testCount() {
//取数量操作
Assert.assertEquals(3,studentCrudRepository.count());
Assert.assertEquals(2,studentCrudRepository.countByAge(22));
}
通过这个例子我们应该已经感受了Spring Data JPA如何简化了我们的数据库访问操作了吧!这一部分先讲到这里,下一讲我们实现分页,排序和更多的JPA查询功能。


