怎样用Python识别条形码?[译]
# 怎样用Python识别条形码?[译]
现在每个人都在使用条形码,大家却几乎注意不到。当我们在商店买东西时,货品的识别使用条形码。仓库中的货物,邮政包裹等也同样使用条形码来识别。但实际上并没有多少人知道条形码是如何工作的。
条形码包含了什么内容,这个图像的编码内容是什么?

让我们来弄清楚,并写出我们自己的解码器。
## 介绍
使用条形码已经有很长的历史。首次尝试实现自动化是在50年代完成的,当时一个读码系统被授予专利。在宾夕法尼亚铁路公司工作的大卫.柯林斯(David Collins)决定简化火车车厢分拣过程。他的方法是 —— 用不同的颜色条纹来编制车厢标识码,然后使用光电管读取它们。1962年这套编码成为美国铁路协会的标准(即KarTrak系统)。到了1968年,为了增加识别准确率,同时减小读码器的尺寸,采用激光替代了氙气灯。1973年开发出通用产品编码(UPC码),1974年第一个带条码的百货商品(箭牌口香糖)开始在美国销售。1984年条形码已经在全美商店使用,其他国家稍后也开始流行。
对于不同的应用,有不同的条码类型。比如字符串“12345678”可以被编码成下列这些条码(不是全部哟):

让我们开始分析。为了方便理解其原理,下面所有条形码均使用 Code-128 码。若想尝试其他编码,请使用 [在线条码生成器](https://barcode.tec-it.com/en/Code128) 自行处理。
初看条形码象一组随机的数字,实际上它的结构井井有条:

1 — 空白区,需要确定条码的起始位置。
2 — 开始位 。有三种Code-128类型可供选择(叫作A,B和C)。开始位相应分别是11010000100, 11010010000 或 11010011100 。不同类型的编码表是不同的(详见Code_128规范)
3 — 条码本身,包含用户数据。
4 — 校验位。
5 — 停止位。对于 Code-128是 1100011101011 。
6(1) — 空白区。
现在让我们来看看这些位是如何编码的。其实很简单——如果我们将最细的线宽设为 «1»,那么2倍的线宽就是«11»,3倍的线宽就是 «111»,以此类推。空白宽度按照同样原则,分别代表 «0», «00» 或 «000»。有兴趣的人可以比较上面图片验证规则是否有效。
现在我们可以开始编码了。
## 获得条码序列
一般来说,这是最复杂的部分,可以通过不同的方式实现。 我不确定我的方法是否是最优的,但对于我们的任务来说,这绝对是足够的。
首先,让我们加载图像,拉伸其宽度,从中间裁剪一条水平线,将其转换为黑白颜色并保存到数组中。
```
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
image_path = "barcode.jpg"
img = Image.open(image_path)
width, height = img.size
basewidth = 4*width
img = img.resize((basewidth, height), Image.ANTIALIAS)
hor_line_bw = img.crop((0, int(height/2), basewidth, int(height/2) + 1)).convert('L')
hor_data = np.asarray(hor_line_bw, dtype="int32")[0]
```
在条形码中黑线对应«1»,但是在RGB中正相反,黑色对应«0»,所以数组中数据值需要倒置。另外我们还需要计算数组的平均值。
```
hor_data = 255 - hor_data
avg = np.average(hor_data)
plt.plot(hor_data)
plt.show()
```
让我们运行程序来验证条形码被正确加载:
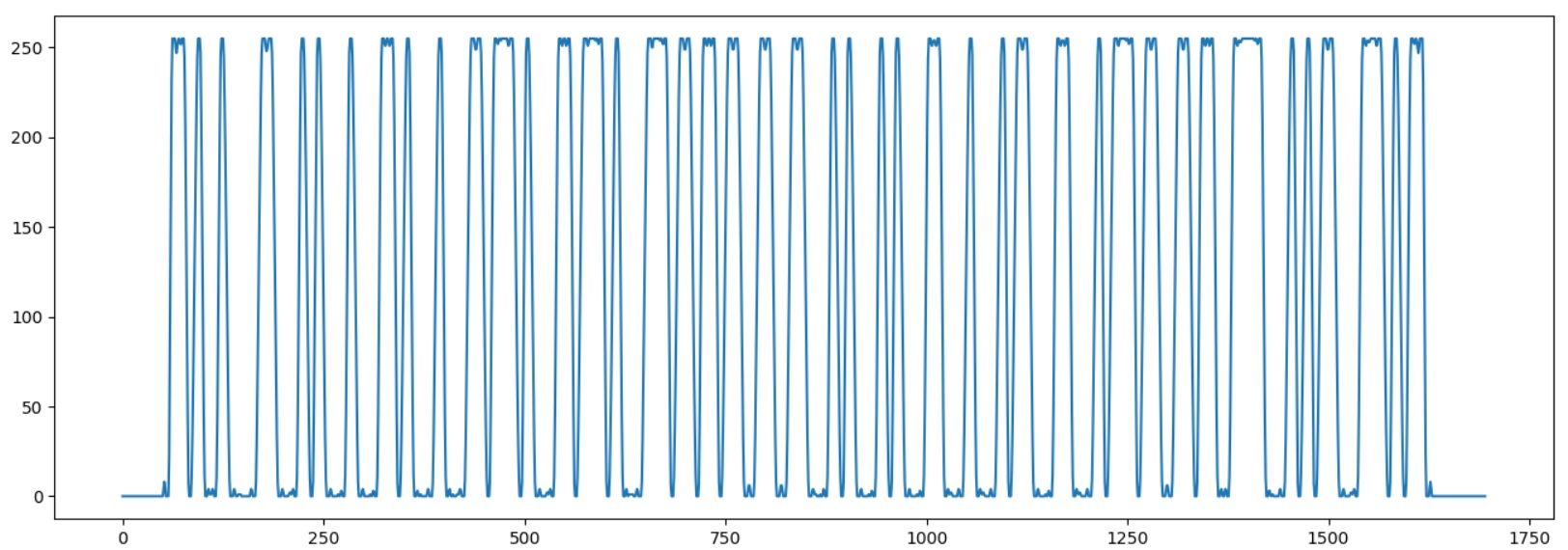
现在我们需要确定一个数位的宽度。为此我们要提取数据,记录黑白线分界点的位置
```
pos1, pos2 = -1, -1
bits = ""
for p in range(basewidth - 2):
if hor_data[p] < avg and hor_data[p + 1] > avg:
bits += "1"
if pos1 == -1:
pos1 = p
if bits == "101":
pos2 = p
break
if hor_data[p] > avg and hor_data[p + 1] < avg:
bits += "0"
bit_width = int((pos2 - pos1)/3)
```
我们只记录黑白线分界点的位置,所以条码«1101»会被存为 «101»,但是对于获取条码数位的像素宽度足够了。
现在让我们对数据进行解码。我们需要找到每个条码线,并找出其间距对应的位数。位数并不能精确匹配(条码会被拉伸或扭曲一点),所以我们需要将结果四舍五入为整数值。
```
bits = ""
for p in range(basewidth - 2):
if hor_data[p] > avg and hor_data[p + 1] < avg:
interval = p - pos1
cnt = interval/bit_width
bits += "1"*int(round(cnt))
pos1 = p
if hor_data[p] < avg and hor_data[p + 1] > avg:
interval = p - pos1
cnt = interval/bit_width
bits += "0"*int(round(cnt))
pos1 = p
```
也许有更好的方法来做到这一点,大家可以写到评论区。
如果一切都做得很完美,我们会得到类似的序列:
```
11010010000110001010001000110100010001101110100011011101000111011011
01100110011000101000101000110001000101100011000101110110011011001111
00010101100011101011
```
## 解码
一般来说,解码很容易。Code-128码是11位条码,具有不同的编码类型(根据编码类型—A,B或C,可以表示字母或[00]-[99]的数字对集合。
在我们的例子中,起始位是 11010010000,对应编码类型B。我懒得手动输入所有代码,所以直接从维基百科页面上复制粘贴它。解析每行的内容也是使用Python(提示—开发产品可别这么干)
```
CODE128_CHART = """
0 _ _ 00 32 S 11011001100 212222
1 ! ! 01 33 ! 11001101100 222122
2 " " 02 34 " 11001100110 222221
3 # # 03 35 # 10010011000 121223
...
93 GS } 93 125 } 10100011110 111341
94 RS ~ 94 126 ~ 10001011110 131141
103 Start Start A 208 SCA 11010000100 211412
104 Start Start B 209 SCB 11010010000 211214
105 Start Start C 210 SCC 11010011100 211232
106 Stop Stop - - - 11000111010 233111""".split()
SYMBOLS = [value for value in CODE128_CHART[6::8]]
VALUESB = [value for value in CODE128_CHART[2::8]]
CODE128B = dict(zip(SYMBOLS, VALUESB))
```
最后的部分很简单。首先,把序列拆分成11位数据块:
```
sym_len = 11
symbols = [bits[i:i+sym_len] for i in range(0, len(bits), sym_len)]
```
最后,生成字符串并显示:
```
str_out = ""
for sym in symbols:
if CODE128B[sym] == 'Start':
continue
if CODE128B[sym] == 'Stop':
break
str_out += CODE128B[sym]
print(" ", sym, CODE128B[sym])
print("Str:", str_out)
```
我没有在此显示本文开头条码图片的解码结果,把它作为读者的作业吧(使用下载的智能手机APP识别将被视为作弊:)
CRC校验也没有在此代码中实现,如有需要请自行解决。
当然,本算法并不完美,它只花了一个半小时完成。对于专业性任务可以使用现成的类库,比如 pyzbar。其解码条码图片,只需4行代码足矣:
```
from pyzbar.pyzbar import decode
img = Image.open(image_path)
decode = decode(img)
print(decode)
```
(首先使用命令行 «pip install pyzbar»安装类库)
**附:**关于条码校验位的算法历史,读者 vinograd19 写了很有趣的评论
校验位的计算很有趣。
校验位很明显是为了避免解码错误。如果一个代码是1234,被解码为7234,我们需要一个方法拒绝1变成7。验证方法可以不完美,但是至少90%条码能够被正确验证。
第一步算法:让我们得到数字和,且余数为0.第一个符号包含数据,最后一个数字是这样选择的,数字和除以10。解码后,如果数字和不能被10整除,则解码错误,需要重新解码。比如,条码1234有效—1+2+3+4 = 10。条码1216也有效,但1218无效。
这避免了解码问题。但是条码可以通过硬件键盘手工输入。这个方法的另一个缺陷被发现——如果订单的两位数字被交换了,校验位仍然正确,这太糟了。不如,代码1234被输入为2134,校验位仍然是一样的。如果人们输入数字很快,错误的数字顺序是常见的情况。
第二步算法:改进校验位算法——计算奇数位两次。这样,如果订单号改变了,数字和就不对了。比如代码2364是有效的(2 + 3\*2+ 6 + 4\*2 = 22),但代码3264是无效的(3 + 2\*2 + 6 + 4\*2 = 21)。很好,但是另一种情况又出现了。有些键盘是两行10键,第一行是12345,第二行是67890.如果 «1» 输入成«2»,检验码会出错。但是如果 «1» 输入成«6»,有时校验码仍然正确。因为6=1+5,如果数字在奇数位,26=21+2\*5—数字和增加了10.同样的错误也会发生在 «7»代替 «2», «8» 代替 «3», 等情况下。
第三步算法:再次计算数字和,但是让奇数位...乘以3。比如代码1234565 是有效的,因为1 + 2\*3 + 3 + 4\*3 + 5 + 6\*3 +5 = 50.
这个方法略微变化成为了EAN13编码的标准:数字位固定为13位,第13位为校验位。奇数位数字相加3次,偶数位数字相加1次。
EAN-13条码广泛使用在贸易和商业领域,是人们最常见到的条码编码。Code-128编码也使用同样的校验规则,具体条码数据结构参见Wikipedia相关条目。
## 结论
正如我们所看到的,即使像条形码这样简单的东西,也可以包含一些很酷的东西。顺便给耐心地读到这个地方的读者一个小窍门——条形码下的文本与条形码数据完全相同。这是为操作员准备的,如果扫描器无法读取,他们可以手动输入代码。因此很容易知道条形码内容—— 只需阅读条码下面的文字。
------
原文:[How does a barcode work?](https://habr.com/en/post/439768/)


