生信基因功能分析工具:Kinfin使用教程
上周推出的Orthofinder受到广大粉丝的热烈欢迎,于是我决定再给大家介绍一个我经常使用的基因功能分析的工具Kinfin,这款工具可以用于整理orthofinder结果(相当于其下游分析),同样这款工具也是没有任何中文教程,希望大家可以通过我的介绍简单了解一下这款工具,如果合适适用的话,也可以进行模仿和使用。
什么是Kinfin??
工具设计背景
在认识一款新的工具时,第一件事当然是要了解这个工具可以拿来干嘛?不用着急,现在就为大家简单介绍。
目前,识别不同类群的基因同源性是比较基因组分析研究的组成部分。例子包括基因家族进化,基因组进化,物种系统发育以及群体遗传学和生态遗传学的基因座分析。相信大家多多少少都会接触过以上这些领域,就在这个情况下,KinFin,一款通过本地聚类蛋白质分析,来寻找你所定义的分类群分组的工具包,被设计出来了。
工具特点
- 它需要通过OrthoFinder或OrthoMCL等工具输出蛋白质聚类文件,以及功能注释数据(InterProScan输出,这个内容也蛮有意义,计划下周讲)和用户定义的物种分类,以获得丰富的直系组聚合注释。
- 它读取标准文件格式包括各种在基因组测序和注释项目中生成的输出文件。
- 它可以很容易地整合到比较基因组学项目中,用于在用户定义的,分类群感知的背景中鉴定感兴趣的蛋白质簇。
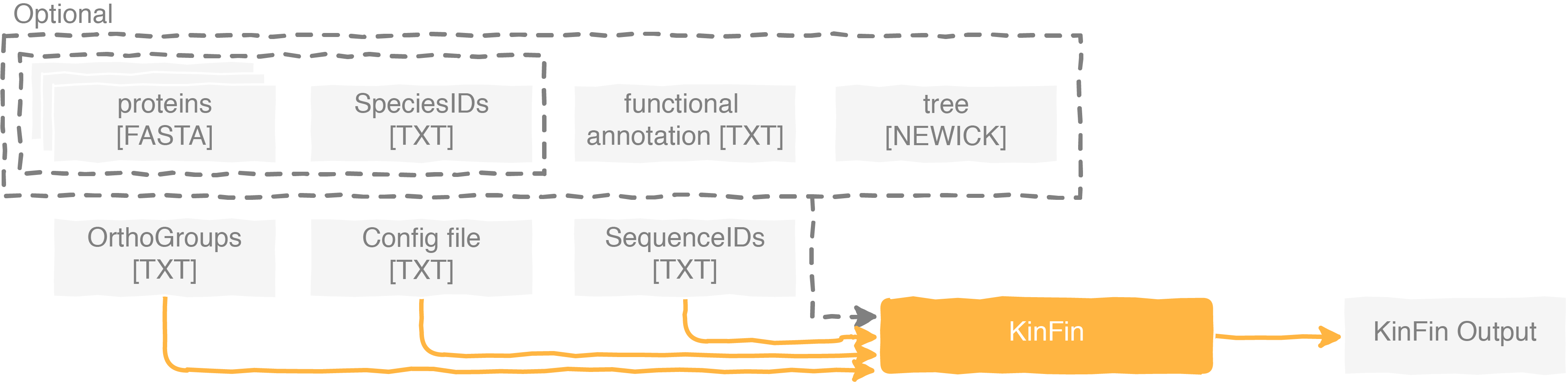
使用该工具的流程
然后流程一般有两个,后面会具体介绍基于蛋白质cluster的流程(相当于直接分析orthofinder的结果):
- 重蛋白质序列开始的流程
- 基于已经有蛋白质cluster结果的流程
工具安装
依赖的软件工具:
Python2.7+ (is installed on most Unix/Linux systems)
pip
GNU wget (is installed on most Unix/Linux systems)
git (optional)
interproscan
安装步骤:
git clone https://github.com/DRL/kinfin.git
cd kinfin
./install
基于已经有蛋白质cluster结果的工作流程
在运用该流程之前,你需要确保你满足一下条件:
- 假定你使用OrthoFinder,OrthoMCL或类似软件拥有聚类蛋白质文件。
- 如果你没有使用该工具,你也一定要有OrthoFinder输出结果 OrthologousGroups.txt格式相同的文件,说白了就直接使用Orthofinder就好了,省时省力
第一步蛋白质的功能分析,这一步是可选的

这里需要安装并使用interproscan,对蛋白质进行功能分析。
这里使用上一次Orthofinder的文件进行,先回顾一下蛋白质文件夹里面的内容
ls -thrl
-rw-r----- 1 hhu hhu 371106 Nov 10 16:20 Maga.faa
-rw-r----- 1 hhu hhu 381627 Nov 10 16:20 Mgal.faa
-rw-r----- 1 hhu hhu 220016 Nov 10 16:20 Mgen.faa
-rw-r----- 1 hhu hhu 326878 Nov 10 16:20 Mhyo.faa
然后开始运行蛋白质注释
mkdir out
cat *.faa > all_proteins.faa
./interproscan.sh \
-i all_proteins.faa \
-d out/ \
-dp \
-t p \
--goterms \
-appl Pfam \
-f TSV
完成InterProScan分析后,必须使用iprs2table.py将输出文件转换为KinFin可读的文件格式
python ~/git/kinfin/scripts/iprs2table.py -i all_proteins.tsv -domain_sources Pfam
第二步准备kinfin的配置文件
配置文件通过将taxa分组为任意属性下的用户定义集来指导分析。这些属性可以包括,例如,标准分类法(如NCBI分类标准“TaxID”标识符中所体现的),所涉及的分类单元的替代系统安排,生活方式,地理来源或表型或其他元数据的任何其他方面。
- 基于Orthofinder clustering结果:
可以从OrthoFinder SpeciesIDs.txt文件生成KinFin配置文件,但要求所有FASTA文件的文件名都带有TAXON前缀
回顾一下上次orthofinder生成的结果,所需的SpeciesIDs.txt可以从这里获取
cd Results_Nov10/WorkingDirectory
ll -trhl
-rw-r----- 1 hhu hhu 80355 Nov 10 16:50 OrthoFinder_v2.2.7_graph.txt
-rw-r----- 1 hhu hhu 268176 Nov 10 16:49 SequenceIDs.txt
-rw-r----- 1 hhu hhu 305691 Nov 10 16:49 Species0.fa
-rw-r----- 1 hhu hhu 307261 Nov 10 16:49 Species1.fa
-rw-r----- 1 hhu hhu 181490 Nov 10 16:49 Species2.fa
-rw-r----- 1 hhu hhu 271662 Nov 10 16:49 Species3.fa
-rw-r----- 1 hhu hhu 48 Nov 10 16:49 SpeciesIDs.txt
-rw-r----- 1 hhu hhu 22295 Nov 10 16:50 clusters_OrthoFinder_v2.2.7_I1.5.txt
-rw-r----- 1 hhu hhu 31243 Nov 10 16:50 clusters_OrthoFinder_v2.2.7_I1.5.txt_id_pairs.txt
现在可以开始生成配置文件了:
echo '#IDX,TAXON' > config.txt
sed 's/: /,/g' SpeciesIDs.txt | cut -f 1 -d"." >> config.txt
###查看一下配置文件
cat config.txt
###就是那么简单
#IDX,TAXON
0,Maga
1,Mgal
2,Mgen
3,Mhyo
- 传统 clustering结果:
在这里如果你没有使用orthofiner去生成蛋白质簇,kinfin也给你提供了相应的工具去生成配置文件:
~/git/kinfin/generate_kinfin_input.py \
--fasta_dir DIR
另外,额外的信息也可以加入到配置文件中:
-
OUT表示外群和内群蛋白质组 - 用于将蛋白质组分组为分类集的独一属性名称
第三步:整合不同的文件,运行kinfin
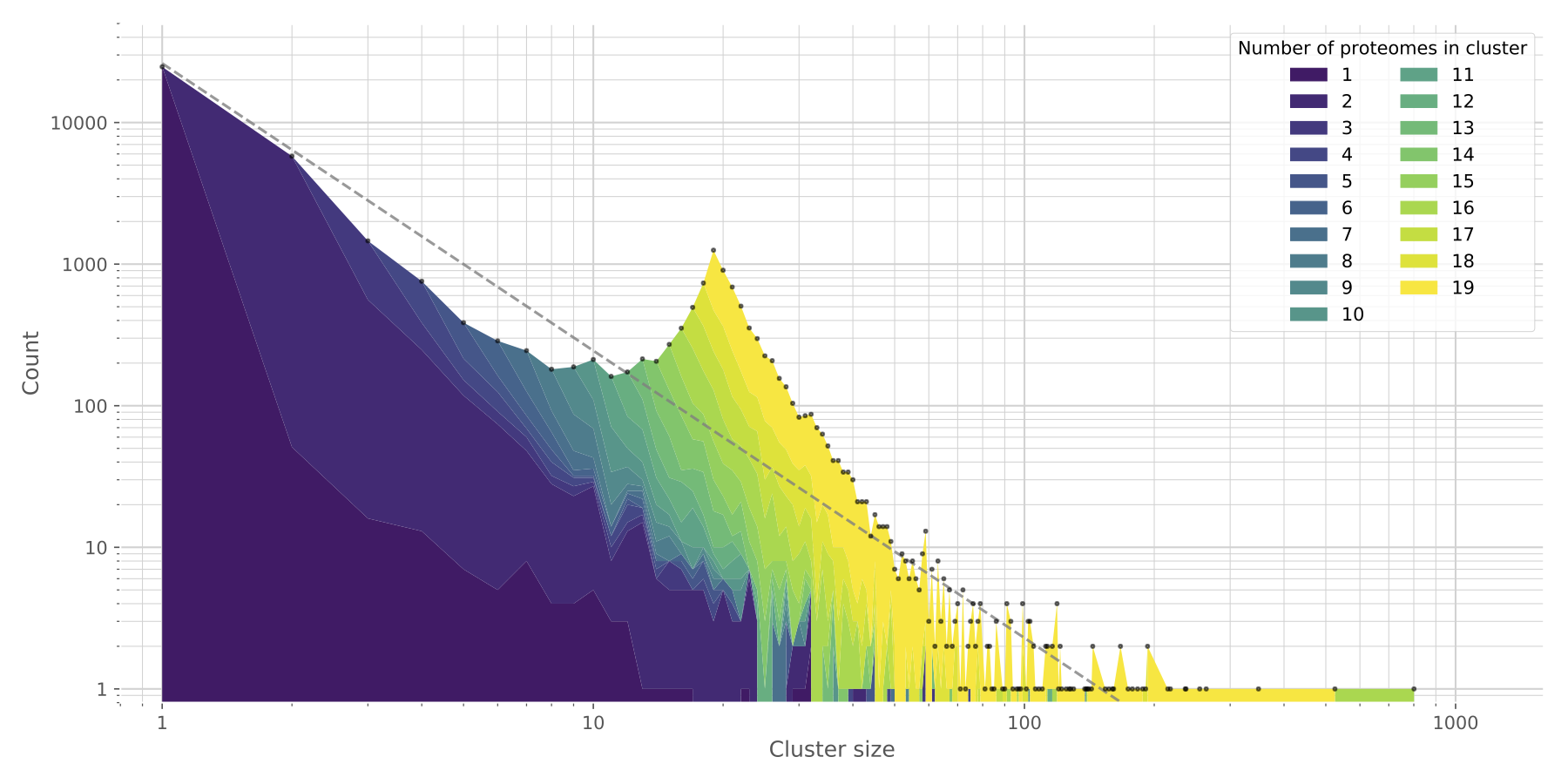
说白了kinfin就是一个整合的软件,可以将你同源的结果,功能分析的结果,还有甚至系统进化树的结果整合一起。
###我将需要的输入文件整合到一个文件夹里
-rw-r----- 1 hhu hhu 90448 Nov 18 10:30 Orthogroups.txt
-rw-r----- 1 hhu hhu 268176 Nov 18 10:30 SequenceIDs.txt
-rw-r----- 1 hhu hhu 48 Nov 18 10:31 SpeciesIDs.txt
-rw-r----- 1 hhu hhu 39 Nov 18 10:32 config.txt
-rw-r----- 1 hhu hhu 127039 Nov 17 16:07 functional_annotation.txt
运行kinfin
~/biosoft/kinfin/kinfin --cluster_file Orthogroups.txt --config_file config.txt --sequence_ids_file SequenceIDs.txt --species_ids_file SpeciesIDs.txt --fasta_dir /scratch/pawsey0149/hhu/tool/OrthoFinder-2.3.1/ExampleData/ --functional_annotation functional_annotation.txt
简单查看一下生成的结果:
###根据你物种来统计其对应的正交群,上一次用R也能做到,这次更能简单,全部正交群的分布都清楚明了
head cluster_counts_by_taxon.txt
#ID Maga Mgal Mgen Mhyo
OG0000000 0 56 0 0
OG0000001 27 0 0 0
OG0000002 5 2 3 1
OG0000003 1 5 4 1
OG0000004 2 2 4 2
OG0000005 4 3 2 0
OG0000006 0 1 0 8
OG0000007 0 1 0 8
OG0000008 2 2 2 2
OG0000009 2 2 2 2
OG0000010 2 2 2 1
OG0000011 3 1 2 1
OG0000012 3 3 0 1
OG0000013 3 2 0 2
OG0000014 5 1 1 0
OG0000015 1 2 3 1
也有总的数据统计,每个物种中对应有多少个正交群,还有各种其他的信息,例如singleton的cluster或者protein数目等等
head TAXON.attribute_metrics.txt
#attribute taxon_set cluster_total_count protein_total_count protein_total_span singleton_cluster_count singleton_protein_count singleton_protein_span specific_cluster_count specific_protein_count specific_protein_span shared_cluster_count shared_protein_count shared_protein_span specific_cluster_true_1to1_count specific_cluster_fuzzy_count shared_cluster_true_1to1_count shared_cluster_fuzzy_count absent_cluster_total_count absent_cluster_singleton_count absent_cluster_specific_count absent_cluster_shared_count
TAXON_count TAXON_taxa
TAXON Maga 749 820 295442 317 317 98288 2 29 9641 430 474 187513 0 0 0 0 582 478 4 100 1 Maga
TAXON Mgal 664 763 297398 202 202 67578 3 63 37143 459 498 192677 0 0 0 0 667 593 3 71 1 Mgal
TAXON Mgen 441 476 175532 47 47 13582 0 0 0 394 429 161950 0 0 0 0 890 748 6 136 1 Mgen
TAXON Mhyo 645 674 262963 229 229 87767 1 5 2217 415 440 172979 0 0 0 0 686 566 5 115 1 Mhyo
这个软件还可以将功能分析与其正交群相联系,这是我最喜欢的功能,可以迅速将正交组和其相应的功能相结合,对于挖掘对于正交群的功能有很重要的作用哦。
head cluster_domain_annotation.Pfam.txt
#cluster_id domain_source domain_id domain_description protein_count protein_count_with_domain TAXA_with_domain_fraction TAXA_with_domain TAXA_without_domain
OG0000000 Pfam PF08268 F-box associated domain 63 60 1.000 atha:60/63 atha:3/63
OG0000000 Pfam PF00646 F-box domain 63 53 1.000 atha:53/63 atha:10/63
OG0000001 Pfam PF00646 F-box domain 62 28 1.000 Am_pan:27/61,atha:1/1 Am_pan:34/61
OG0000001 Pfam PF12937 F-box-like 62 3 0.500 Am_pan:3/61 Am_pan:58/61,atha:1/1
OG0000001 Pfam PF08268 F-box associated domain 62 2 0.500 Am_pan:2/61 Am_pan:59/61,atha:1/1
OG0000001 Pfam PF07734 F-box associated 62 2 0.500 Am_pan:2/61 Am_pan:59/61,atha:1/1
OG0000002 Pfam PF00931 NB-ARC domain 35 35 1.000 atha:35/35 N/A
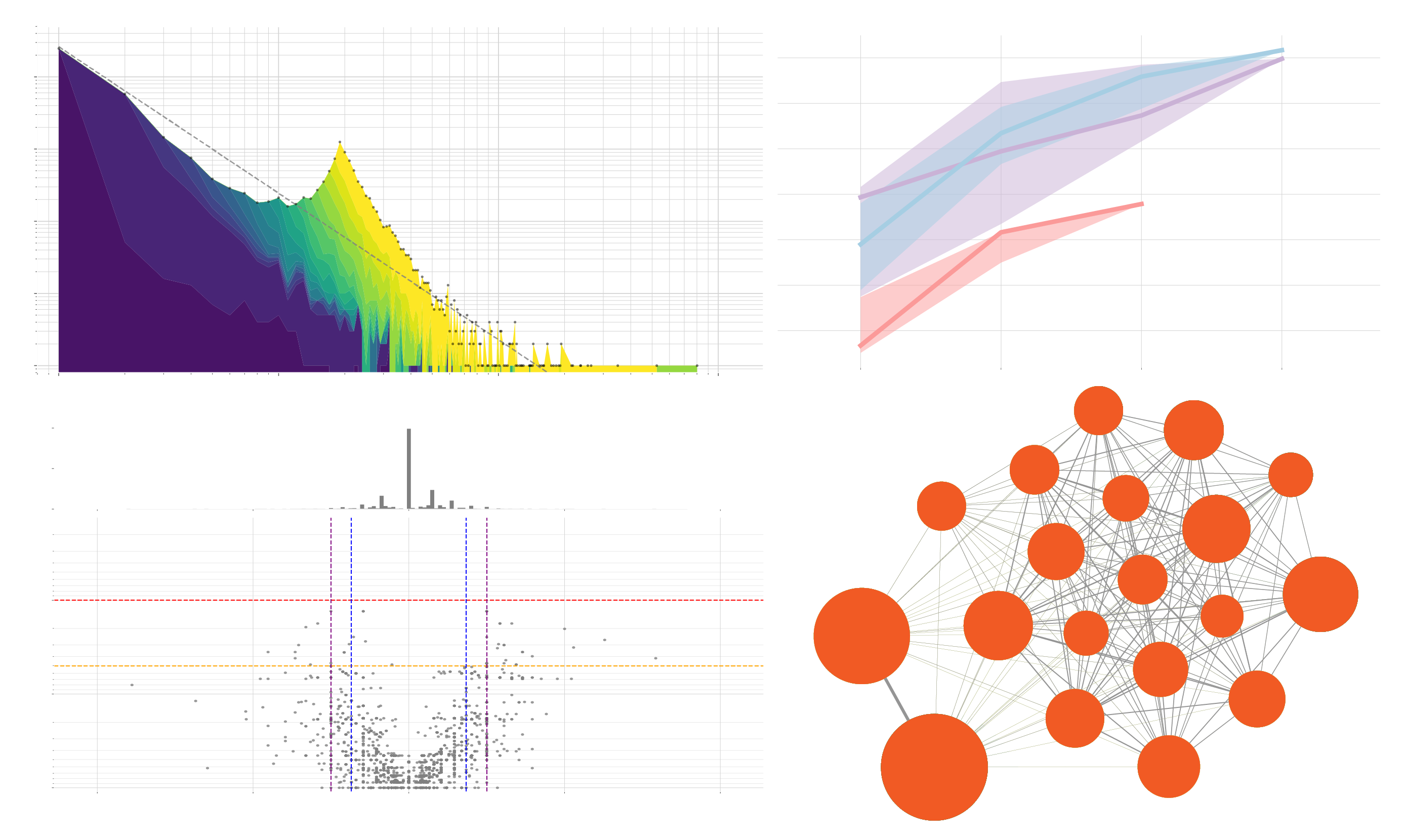
相信经过我的介绍大家对这款软件多少会有点认识,如果你觉得这个软件很cool,你一定要亲自实践一下,体会一下是怎样使用的。另外网上的maunal还介绍了其内置一些可视化的工具,可以画出以下的图,有需要或者兴趣的小伙伴可以自行进行探讨。

参考网站:
https://kinfin.readme.io/docs/starting-from-a-clustering-files


